 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnizart: A General Toolbox for Automatic Music Transcription
Jun 01, 2021We present and release Omnizart, a new Python library that provides a streamlined solution to automatic music transcription (AMT). Omnizart encompasses modules that construct the life-cycle of deep learning-based AMT, and is designed for ease of use with a compact command-line interface. To the best of our knowledge, Omnizart is the first transcription toolkit which offers models covering a wide class of instruments ranging from solo, instrument ensembles, percussion instruments to vocal, as well as models for chord recognition and beat/downbeat tracking, two music information retrieval (MIR) tasks highly related to AMT.
DARTS-ASR: Differentiable Architecture Search for Multilingual Speech Recognition and Adaptation
May 13, 2020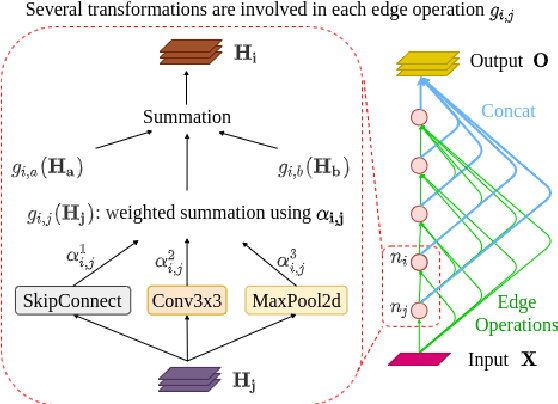
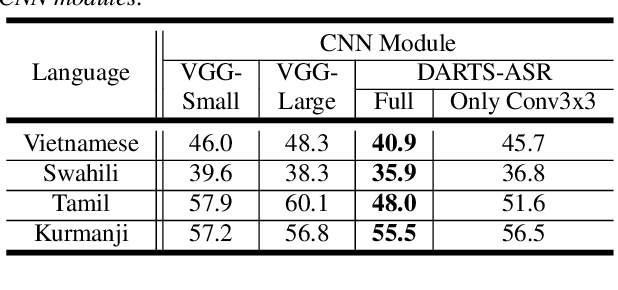
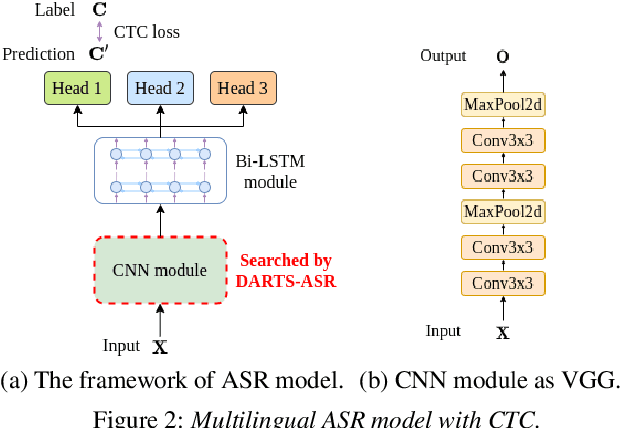
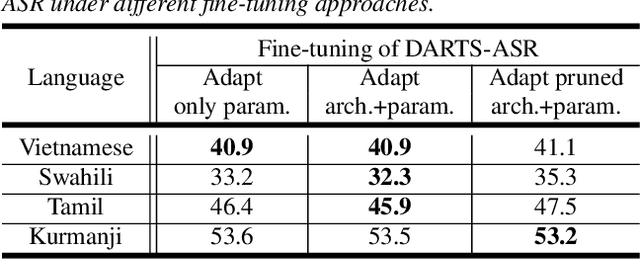
In previous works, only parameter weights of ASR models are optimized under fixed-topology architecture. However, the design of successful model architecture has always relied on human experience and intuition. Besides, many hyperparameters related to model architecture need to be manually tuned. Therefore in this paper, we propose an ASR approach with efficient gradient-based architecture search, DARTS-ASR. In order to examine the generalizability of DARTS-ASR, we apply our approach not only on many languages to perform monolingual ASR, but also on a multilingual ASR setting. Following previous works, we conducted experiments on a multilingual dataset, IARPA BABEL. The experiment results show that our approach outperformed the baseline fixed-topology architecture by 10.2% and 10.0% relative reduction on character error rates under monolingual and multilingual ASR settings respectively. Furthermore, we perform some analysis on the searched architectures by DARTS-ASR.
Meta Learning for End-to-End Low-Resource Speech Recognition
Oct 26, 2019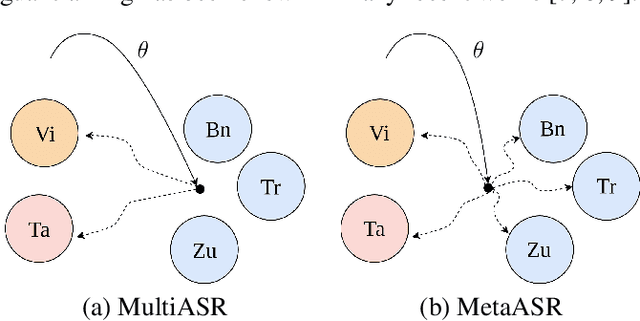
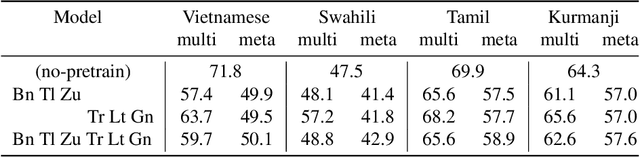
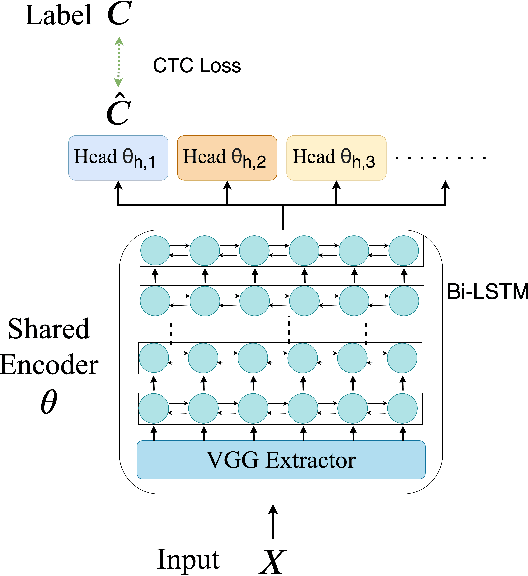
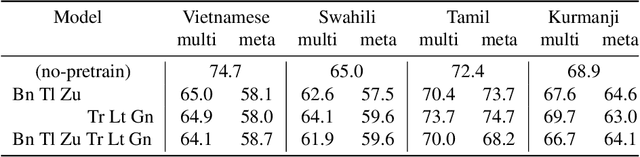
In this paper, we proposed to apply meta learning approach for low-resource automatic speech recognition (ASR). We formulated ASR for different languages as different tasks, and meta-learned the initialization parameters from many pretraining languages to achieve fast adaptation on unseen target language, via recently proposed model-agnostic meta learning algorithm (MAML). We evaluated the proposed approach using six languages as pretraining tasks and four languages as target tasks. Preliminary results showed that the proposed method, MetaASR, significantly outperforms the state-of-the-art multitask pretraining approach on all target languages with different combinations of pretraining languages. In addition, since MAML's model-agnostic property, this paper also opens new research direction of applying meta learning to more speech-related applications.
Hierarchical Attention Model for Improved Machine Comprehension of Spoken Content
Jan 01, 2017
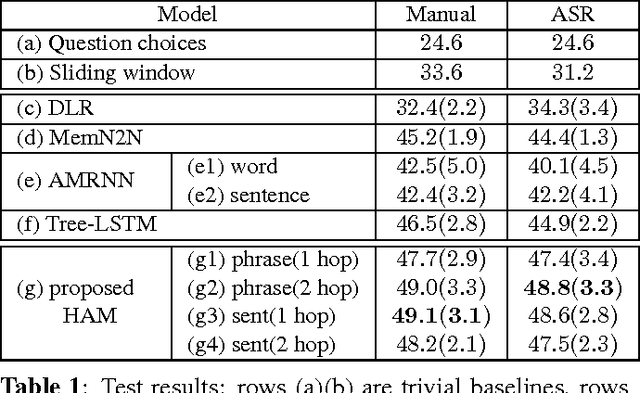
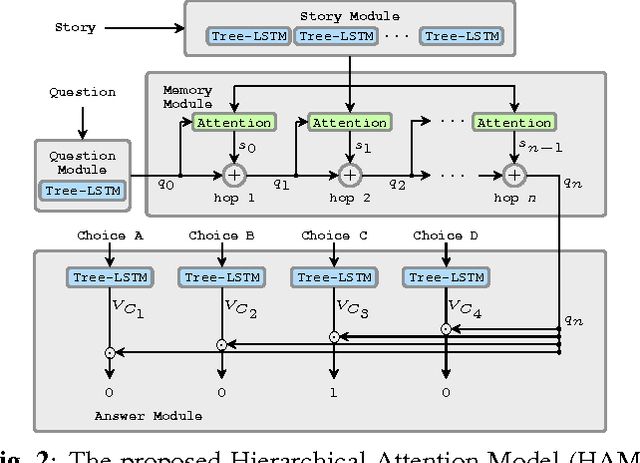
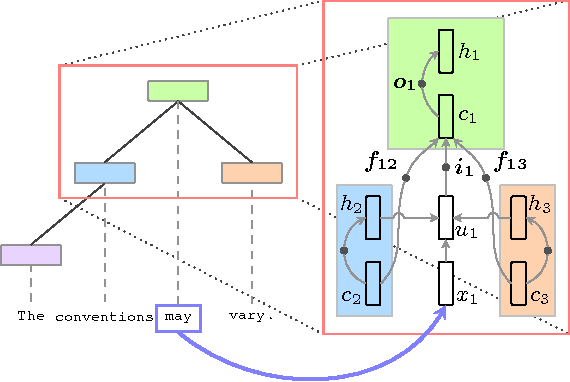
Multimedia or spoken content presents more attractive information than plain text content, but the former is more difficult to display on a screen and be selected by a user. As a result, accessing large collections of the former is much more difficult and time-consuming than the latter for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content and summarize the key information for humans to browse over. In this endeavor, a new task of machine comprehension of spoken content was proposed recently. The initial goal was defined as the listening comprehension test of TOEFL, a challenging academic English examination for English learners whose native languages are not English. An Attention-based Multi-hop Recurrent Neural Network (AMRNN) architecture was also proposed for this task, which considered only the sequential relationship within the speech utterances. In this paper, we propose a new Hierarchical Attention Model (HAM), which constructs multi-hopped attention mechanism over tree-structured rather than sequential representations for the utterances. Improved comprehension performance robust with respect to ASR errors were obtained.