 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning for Multi-speaker Text-to-speech Synthesis Using Discrete Speech Representation
May 16, 2020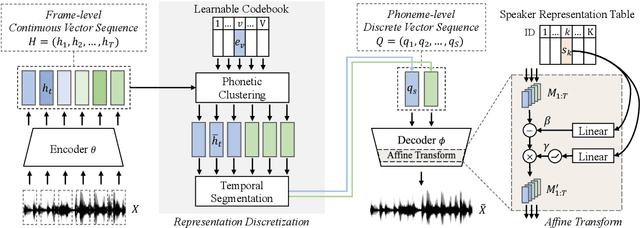
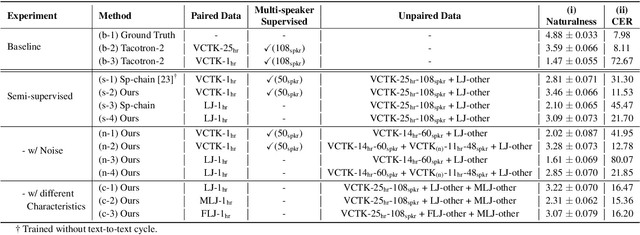
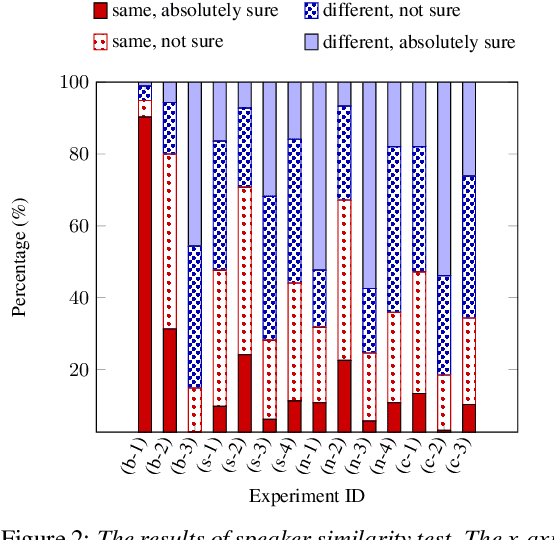
Recently, end-to-end multi-speaker text-to-speech (TTS) systems gain success in the situation where a lot of high-quality speech plus their corresponding transcriptions are available. However, laborious paired data collection processes prevent many institutes from building multi-speaker TTS systems of great performance. In this work, we propose a semi-supervised learning approach for multi-speaker TTS. A multi-speaker TTS model can learn from the untranscribed audio via the proposed encoder-decoder framework with discrete speech representation. The experiment results demonstrate that with only an hour of paired speech data, no matter the paired data is from multiple speakers or a single speaker, the proposed model can generate intelligible speech in different voices. We found the model can benefit from the proposed semi-supervised learning approach even when part of the unpaired speech data is noisy. In addition, our analysis reveals that different speaker characteristics of the paired data have an impact on the effectiveness of semi-supervised TTS.
Meta Learning for End-to-End Low-Resource Speech Recognition
Oct 26, 2019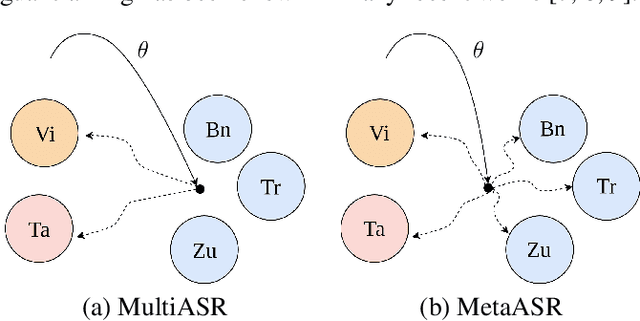
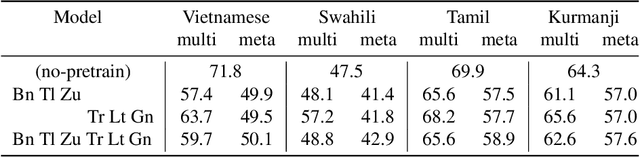
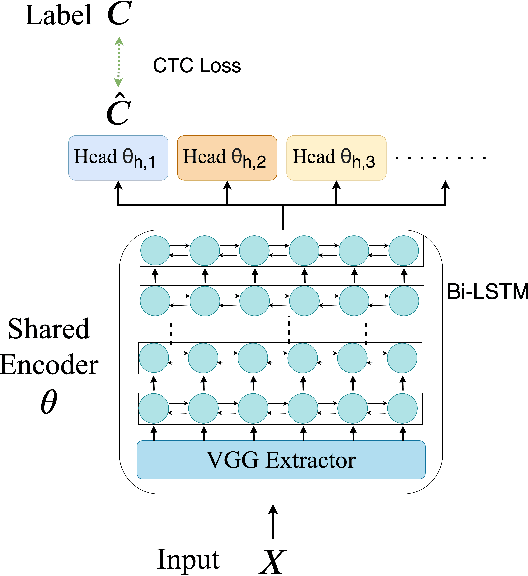
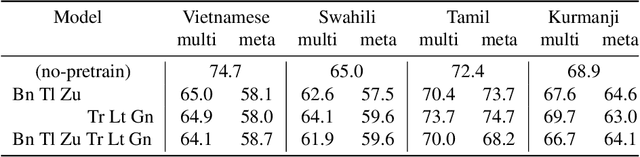
In this paper, we proposed to apply meta learning approach for low-resource automatic speech recognition (ASR). We formulated ASR for different languages as different tasks, and meta-learned the initialization parameters from many pretraining languages to achieve fast adaptation on unseen target language, via recently proposed model-agnostic meta learning algorithm (MAML). We evaluated the proposed approach using six languages as pretraining tasks and four languages as target tasks. Preliminary results showed that the proposed method, MetaASR, significantly outperforms the state-of-the-art multitask pretraining approach on all target languages with different combinations of pretraining languages. In addition, since MAML's model-agnostic property, this paper also opens new research direction of applying meta learning to more speech-related applications.
End-to-end Text-to-speech for Low-resource Languages by Cross-Lingual Transfer Learning
Apr 13, 2019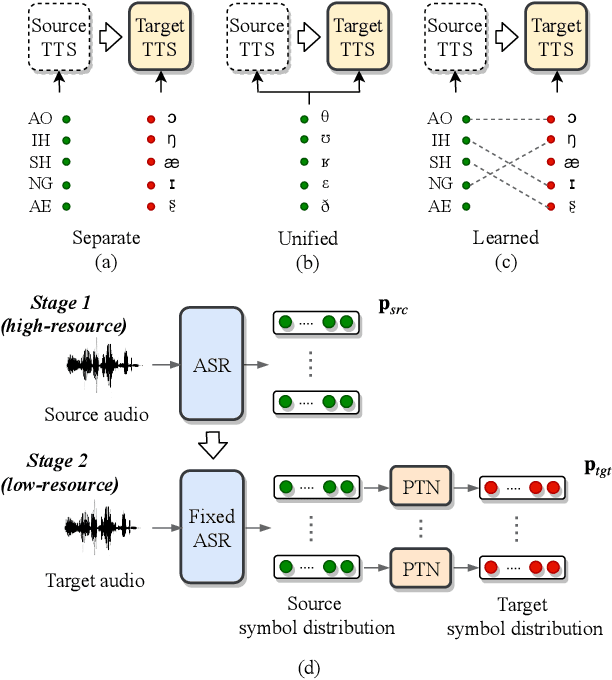
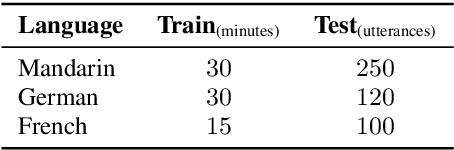
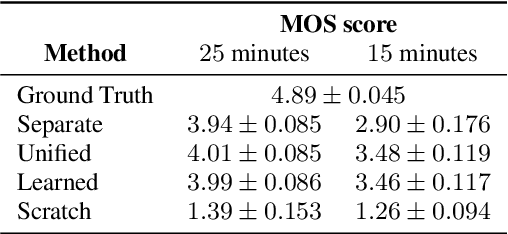
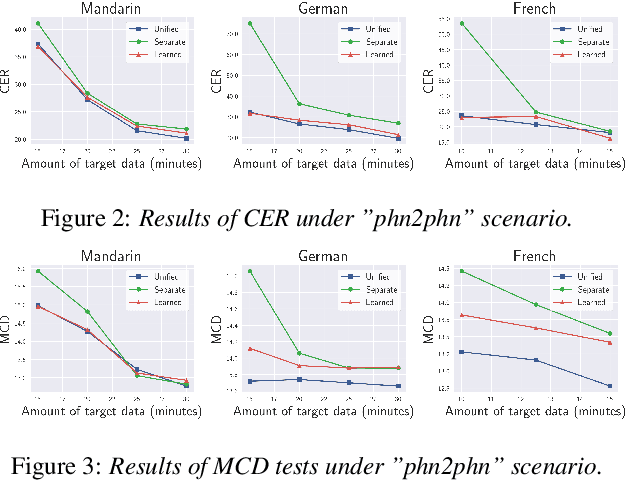
End-to-end text-to-speech (TTS) has shown great success on large quantities of paired text plus speech data. However, laborious data collection remains difficult for at least 95% of the languages over the world, which hinders the development of TTS in different languages. In this paper, we aim to build TTS systems for such low-resource (target) languages where only very limited paired data are available. We show such TTS can be effectively constructed by transferring knowledge from a high-resource (source) language. Since the model trained on source language cannot be directly applied to target language due to input space mismatch, we propose a method to learn a mapping between source and target linguistic symbols. Benefiting from this learned mapping, pronunciation information can be preserved throughout the transferring procedure. Preliminary experiments show that we only need around 15 minutes of paired data to obtain a relatively good TTS system. Furthermore, analytic studies demonstrated that the automatically discovered mapping correlate well with the phonetic expertise.