 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Learning for Multi-speaker Text-to-speech Synthesis Using Discrete Speech Representation
Paper and Code
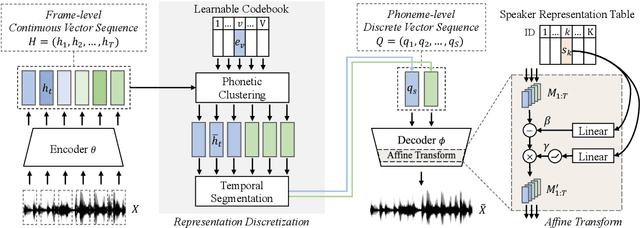
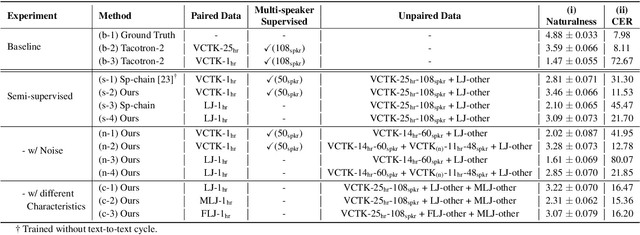
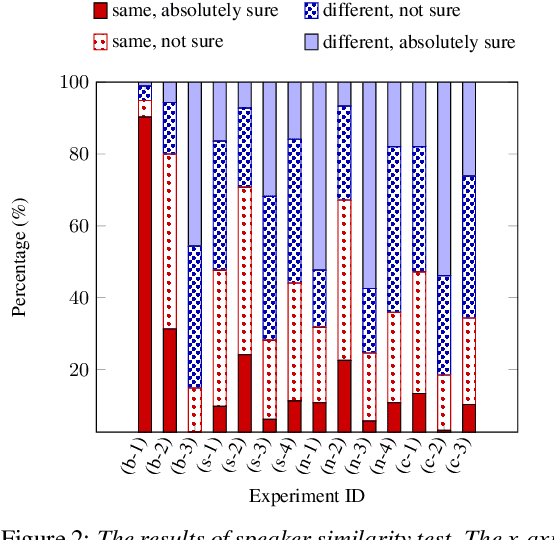
Recently, end-to-end multi-speaker text-to-speech (TTS) systems gain success in the situation where a lot of high-quality speech plus their corresponding transcriptions are available. However, laborious paired data collection processes prevent many institutes from building multi-speaker TTS systems of great performance. In this work, we propose a semi-supervised learning approach for multi-speaker TTS. A multi-speaker TTS model can learn from the untranscribed audio via the proposed encoder-decoder framework with discrete speech representation. The experiment results demonstrate that with only an hour of paired speech data, no matter the paired data is from multiple speakers or a single speaker, the proposed model can generate intelligible speech in different voices. We found the model can benefit from the proposed semi-supervised learning approach even when part of the unpaired speech data is noisy. In addition, our analysis reveals that different speaker characteristics of the paired data have an impact on the effectiveness of semi-supervised TTS.