 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Attention Model for Improved Machine Comprehension of Spoken Content
Paper and Code
Jan 01, 2017
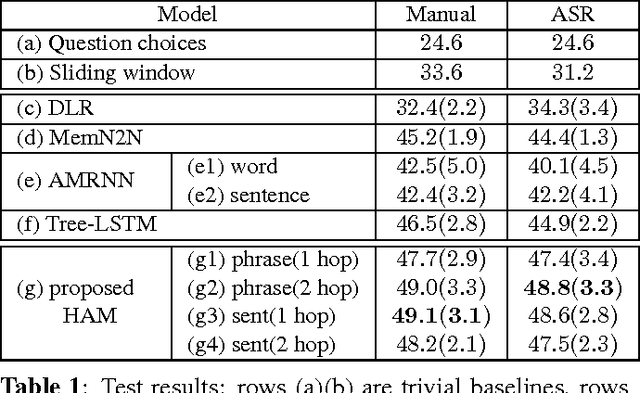
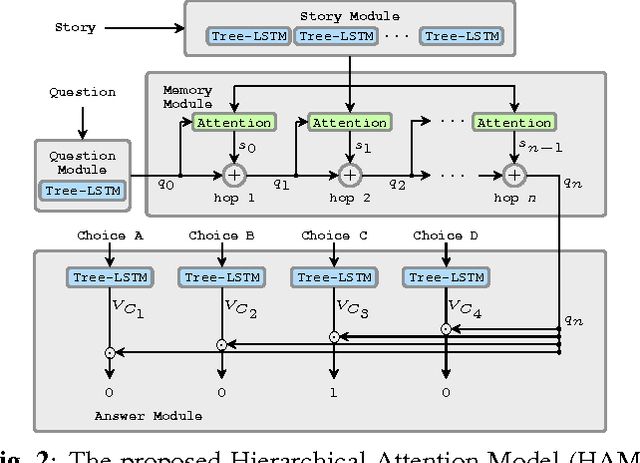
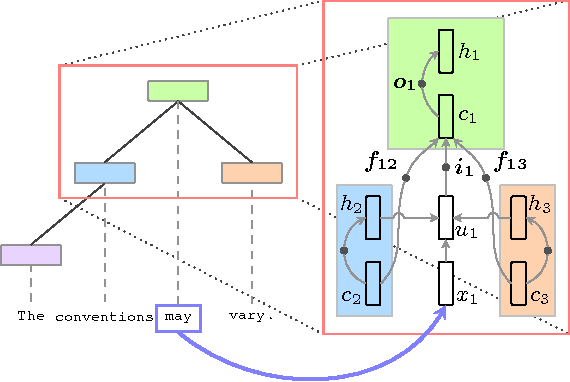
Multimedia or spoken content presents more attractive information than plain text content, but the former is more difficult to display on a screen and be selected by a user. As a result, accessing large collections of the former is much more difficult and time-consuming than the latter for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content and summarize the key information for humans to browse over. In this endeavor, a new task of machine comprehension of spoken content was proposed recently. The initial goal was defined as the listening comprehension test of TOEFL, a challenging academic English examination for English learners whose native languages are not English. An Attention-based Multi-hop Recurrent Neural Network (AMRNN) architecture was also proposed for this task, which considered only the sequential relationship within the speech utterances. In this paper, we propose a new Hierarchical Attention Model (HAM), which constructs multi-hopped attention mechanism over tree-structured rather than sequential representations for the utterances. Improved comprehension performance robust with respect to ASR errors were obtained.