 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Automatically Discovered Multi-level Acoustic Patterns Considering Context Consistency With Applications in Spoken Term Detection
Paper and Code
Sep 07, 2015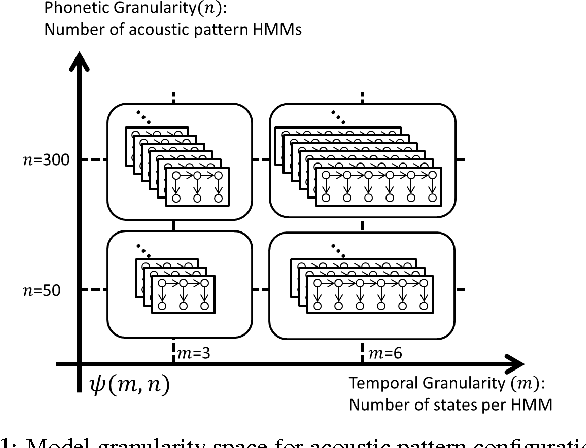
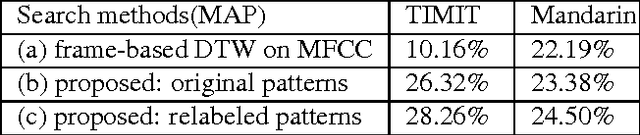
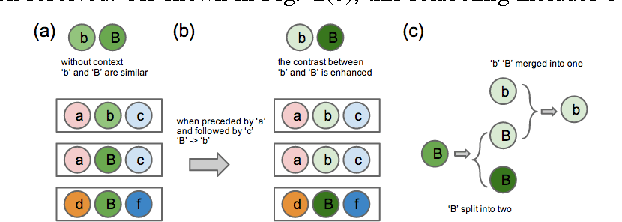
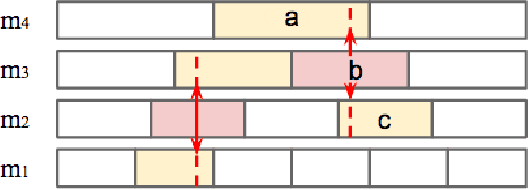
This paper presents a novel approach for enhancing the multiple sets of acoustic patterns automatically discovered from a given corpus. In a previous work it was proposed that different HMM configurations (number of states per model, number of distinct models) for the acoustic patterns form a two-dimensional space. Multiple sets of acoustic patterns automatically discovered with the HMM configurations properly located on different points over this two-dimensional space were shown to be complementary to one another, jointly capturing the characteristics of the given corpus. By representing the given corpus as sequences of acoustic patterns on different HMM sets, the pattern indices in these sequences can be relabeled considering the context consistency across the different sequences. Good improvements were observed in preliminary experiments of pattern spoken term detection (STD) performed on both TIMIT and Mandarin Broadcast News with such enhanced patterns.