 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOX-NAS: Fast, On-device and Explainable Neural Architecture Search
Aug 14, 2021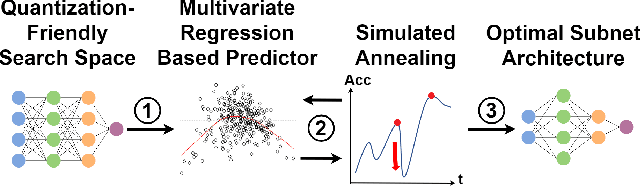
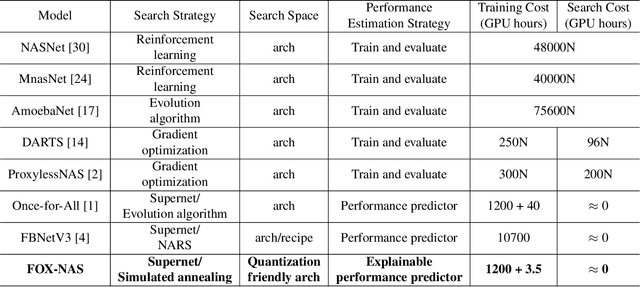
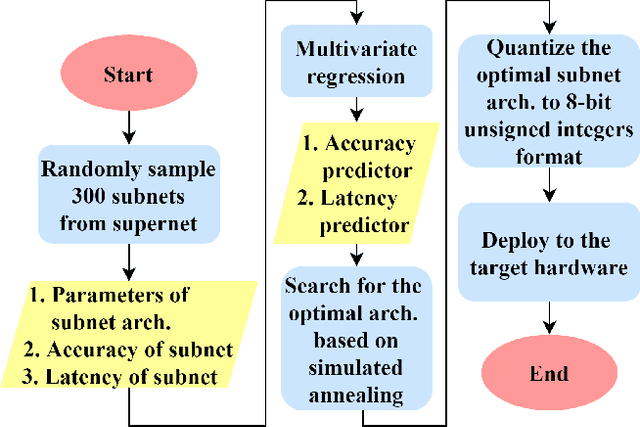
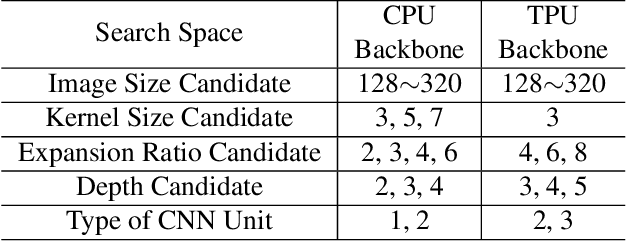
Neural architecture search can discover neural networks with good performance, and One-Shot approaches are prevalent. One-Shot approaches typically require a supernet with weight sharing and predictors that predict the performance of architecture. However, the previous methods take much time to generate performance predictors thus are inefficient. To this end, we propose FOX-NAS that consists of fast and explainable predictors based on simulated annealing and multivariate regression. Our method is quantization-friendly and can be efficiently deployed to the edge. The experiments on different hardware show that FOX-NAS models outperform some other popular neural network architectures. For example, FOX-NAS matches MobileNetV2 and EfficientNet-Lite0 accuracy with 240% and 40% less latency on the edge CPU. FOX-NAS is the 3rd place winner of the 2020 Low-Power Computer Vision Challenge (LPCVC), DSP classification track. See all evaluation results at https://lpcv.ai/competitions/2020. Search code and pre-trained models are released at https://github.com/great8nctu/FOX-NAS.
Unsupervised Iterative Deep Learning of Speech Features and Acoustic Tokens with Applications to Spoken Term Detection
Jul 17, 2017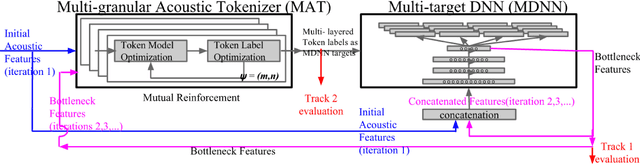
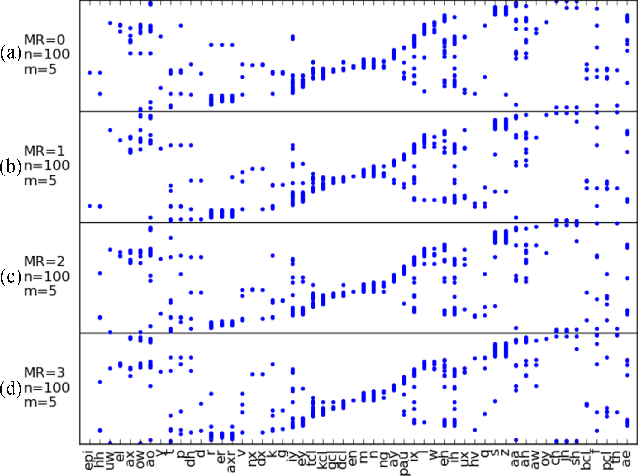
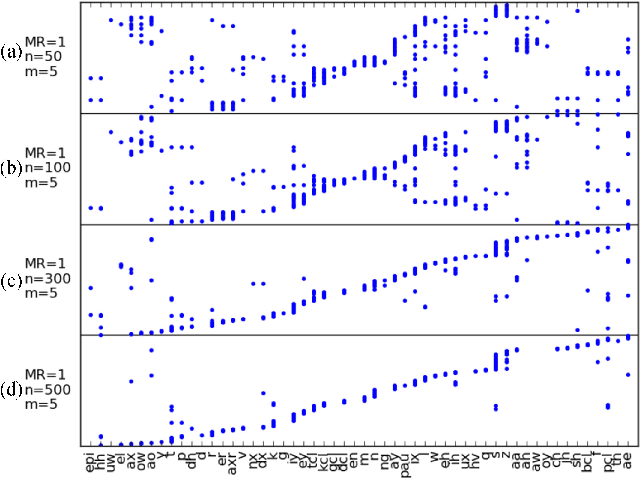
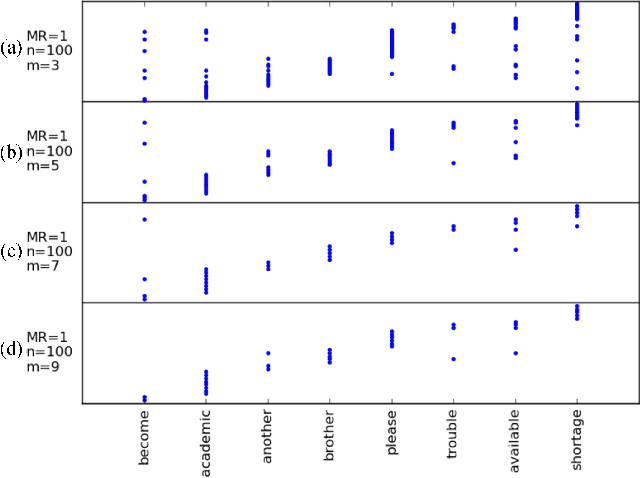
In this paper we aim to automatically discover high quality frame-level speech features and acoustic tokens directly from unlabeled speech data. A Multi-granular Acoustic Tokenizer (MAT) was proposed for automatic discovery of multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters describing the model configuration. These different sets of acoustic tokens carry different characteristics for the given corpus and the language behind, thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target Deep Neural Network (MDNN) trained on frame-level acoustic features. Bottleneck features extracted from the MDNN are then used as the feedback input to the MAT and the MDNN itself in the next iteration. The multi-granular acoustic token sets and the frame-level speech features can be iteratively optimized in the iterative deep learning framework. We call this framework the Multi-granular Acoustic Tokenizing Deep Neural Network (MATDNN). The results were evaluated using the metrics and corpora defined in the Zero Resource Speech Challenge organized at Interspeech 2015, and improved performance was obtained with a set of experiments of query-by-example spoken term detection on the same corpora. Visualization for the discovered tokens against the English phonemes was also shown.
An Iterative Deep Learning Framework for Unsupervised Discovery of Speech Features and Linguistic Units with Applications on Spoken Term Detection
Feb 01, 2016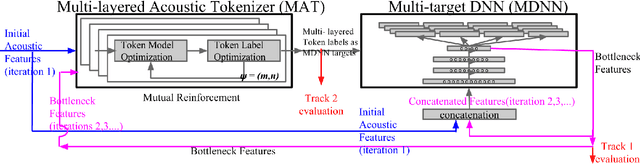
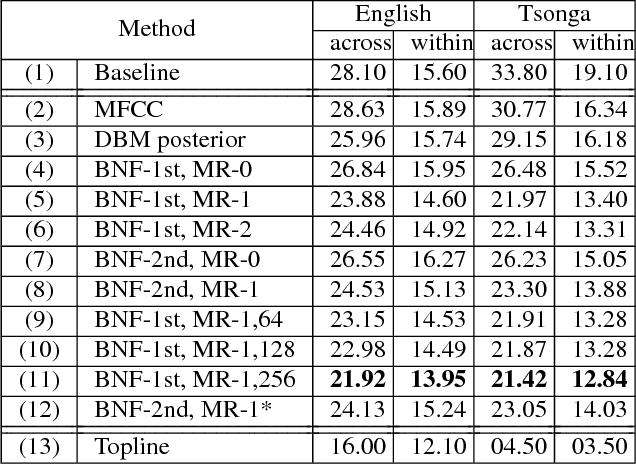
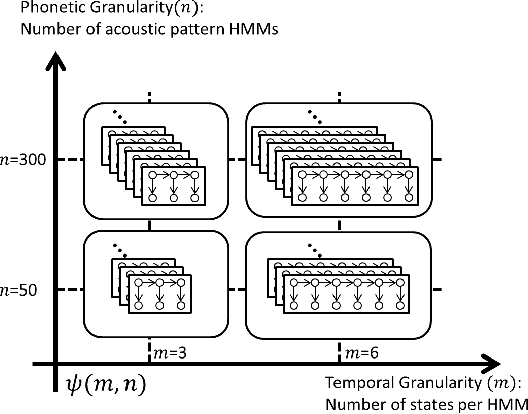
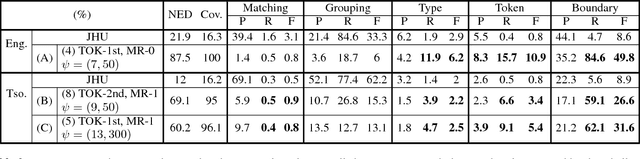
In this work we aim to discover high quality speech features and linguistic units directly from unlabeled speech data in a zero resource scenario. The results are evaluated using the metrics and corpora proposed in the Zero Resource Speech Challenge organized at Interspeech 2015. A Multi-layered Acoustic Tokenizer (MAT) was proposed for automatic discovery of multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters that describe the model configuration. These sets of acoustic tokens carry different characteristics fof the given corpus and the language behind, thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target Deep Neural Network (MDNN) trained on low-level acoustic features. Bottleneck features extracted from the MDNN are then used as the feedback input to the MAT and the MDNN itself in the next iteration. We call this iterative deep learning framework the Multi-layered Acoustic Tokenizing Deep Neural Network (MAT-DNN), which generates both high quality speech features for the Track 1 of the Challenge and acoustic tokens for the Track 2 of the Challenge. In addition, we performed extra experiments on the same corpora on the application of query-by-example spoken term detection. The experimental results showed the iterative deep learning framework of MAT-DNN improved the detection performance due to better underlying speech features and acoustic tokens.