 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkipCat: Rank-Maximized Low-Rank Compression of Large Language Models via Shared Projection and Block Skipping
Dec 15, 2025Large language models (LLM) have achieved remarkable performance across a wide range of tasks. However, their substantial parameter sizes pose significant challenges for deployment on edge devices with limited computational and memory resources. Low-rank compression is a promising approach to address this issue, as it reduces both computational and memory costs, making LLM more suitable for resource-constrained environments. Nonetheless, naïve low-rank compression methods require a significant reduction in the retained rank to achieve meaningful memory and computation savings. For a low-rank model, the ranks need to be reduced by more than half to yield efficiency gains. Such aggressive truncation, however, typically results in substantial performance degradation. To address this trade-off, we propose SkipCat, a novel low-rank compression framework that enables the use of higher ranks while achieving the same compression rates. First, we introduce an intra-layer shared low-rank projection method, where multiple matrices that share the same input use a common projection. This reduces redundancy and improves compression efficiency. Second, we propose a block skipping technique that omits computations and memory transfers for selected sub-blocks within the low-rank decomposition. These two techniques jointly enable our compressed model to retain more effective ranks under the same compression budget. Experimental results show that, without any additional fine-tuning, our method outperforms previous low-rank compression approaches by 7% accuracy improvement on zero-shot tasks under the same compression rate. These results highlight the effectiveness of our rank-maximized compression strategy in preserving model performance under tight resource constraints.
Quamba2: A Robust and Scalable Post-training Quantization Framework for Selective State Space Models
Mar 28, 2025State Space Models (SSMs) are emerging as a compelling alternative to Transformers because of their consistent memory usage and high performance. Despite this, scaling up SSMs on cloud services or limited-resource devices is challenging due to their storage requirements and computational power. To overcome this, quantizing SSMs with low bit-width data formats can reduce model size and benefit from hardware acceleration. As SSMs are prone to quantization-induced errors, recent efforts have focused on optimizing a particular model or bit-width for efficiency without sacrificing performance. However, distinct bit-width configurations are essential for different scenarios, like W4A8 for boosting large-batch decoding speed, and W4A16 for enhancing generation speed in short prompt applications for a single user. To this end, we present Quamba2, compatible with W8A8, W4A8, and W4A16 for both Mamba1 and Mamba2 backbones, addressing the growing demand for SSM deployment on various platforms. Based on the channel order preserving and activation persistence of SSMs, we propose an offline approach to quantize inputs of a linear recurrence in 8-bit by sorting and clustering for input $x$, combined with a per-state-group quantization for input-dependent parameters $B$ and $C$. To ensure compute-invariance in the SSM output, we rearrange weights offline according to the clustering sequence. The experiments show that Quamba2-8B outperforms several state-of-the-art SSM quantization methods and delivers 1.3$\times$ and 3$\times$ speed-ups in the pre-filling and generation stages, respectively, while offering 4$\times$ memory reduction with only a $1.6\%$ average accuracy drop. The evaluation on MMLU shows the generalizability and robustness of our framework. The code and quantized models will be released at: https://github.com/enyac-group/Quamba.
Similarity Trajectories: Linking Sampling Process to Artifacts in Diffusion-Generated Images
Dec 22, 2024Artifact detection algorithms are crucial to correcting the output generated by diffusion models. However, because of the variety of artifact forms, existing methods require substantial annotated data for training. This requirement limits their scalability and efficiency, which restricts their wide application. This paper shows that the similarity of denoised images between consecutive time steps during the sampling process is related to the severity of artifacts in images generated by diffusion models. Building on this observation, we introduce the concept of Similarity Trajectory to characterize the sampling process and its correlation with the image artifacts presented. Using an annotated data set of 680 images, which is only 0.1% of the amount of data used in the prior work, we trained a classifier on these trajectories to predict the presence of artifacts in images. By performing 10-fold validation testing on the balanced annotated data set, the classifier can achieve an accuracy of 72.35%, highlighting the connection between the Similarity Trajectory and the occurrence of artifacts. This approach enables differentiation between artifact-exhibiting and natural-looking images using limited training data.
V"Mean"ba: Visual State Space Models only need 1 hidden dimension
Dec 21, 2024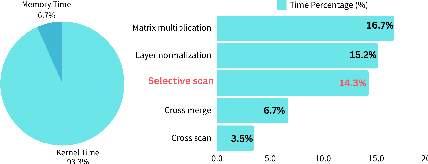
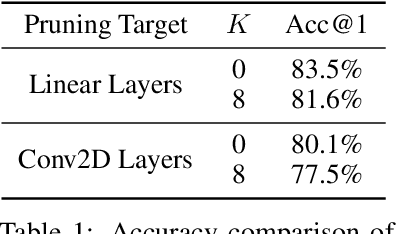
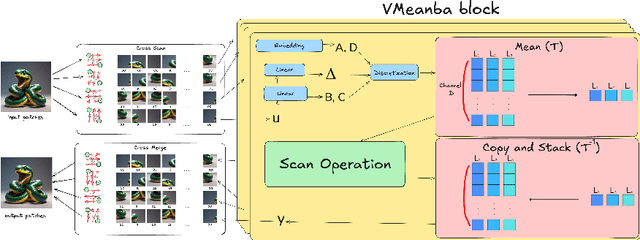
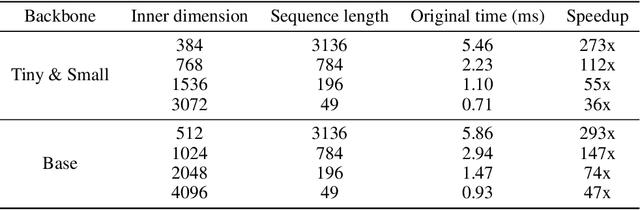
Vision transformers dominate image processing tasks due to their superior performance. However, the quadratic complexity of self-attention limits the scalability of these systems and their deployment on resource-constrained devices. State Space Models (SSMs) have emerged as a solution by introducing a linear recurrence mechanism, which reduces the complexity of sequence modeling from quadratic to linear. Recently, SSMs have been extended to high-resolution vision tasks. Nonetheless, the linear recurrence mechanism struggles to fully utilize matrix multiplication units on modern hardware, resulting in a computational bottleneck. We address this issue by introducing \textit{VMeanba}, a training-free compression method that eliminates the channel dimension in SSMs using mean operations. Our key observation is that the output activations of SSM blocks exhibit low variances across channels. Our \textit{VMeanba} leverages this property to optimize computation by averaging activation maps across the channel to reduce the computational overhead without compromising accuracy. Evaluations on image classification and semantic segmentation tasks demonstrate that \textit{VMeanba} achieves up to a 1.12x speedup with less than a 3\% accuracy loss. When combined with 40\% unstructured pruning, the accuracy drop remains under 3\%.
Quamba: A Post-Training Quantization Recipe for Selective State Space Models
Oct 17, 2024State Space Models (SSMs) have emerged as an appealing alternative to Transformers for large language models, achieving state-of-the-art accuracy with constant memory complexity which allows for holding longer context lengths than attention-based networks. The superior computational efficiency of SSMs in long sequence modeling positions them favorably over Transformers in many scenarios. However, improving the efficiency of SSMs on request-intensive cloud-serving and resource-limited edge applications is still a formidable task. SSM quantization is a possible solution to this problem, making SSMs more suitable for wide deployment, while still maintaining their accuracy. Quantization is a common technique to reduce the model size and to utilize the low bit-width acceleration features on modern computing units, yet existing quantization techniques are poorly suited for SSMs. Most notably, SSMs have highly sensitive feature maps within the selective scan mechanism (i.e., linear recurrence) and massive outliers in the output activations which are not present in the output of token-mixing in the self-attention modules. To address this issue, we propose a static 8-bit per-tensor SSM quantization method which suppresses the maximum values of the input activations to the selective SSM for finer quantization precision and quantizes the output activations in an outlier-free space with Hadamard transform. Our 8-bit weight-activation quantized Mamba 2.8B SSM benefits from hardware acceleration and achieves a 1.72x lower generation latency on an Nvidia Orin Nano 8G, with only a 0.9% drop in average accuracy on zero-shot tasks. The experiments demonstrate the effectiveness and practical applicability of our approach for deploying SSM-based models of all sizes on both cloud and edge platforms.
SCAN-Edge: Finding MobileNet-speed Hybrid Networks for Diverse Edge Devices via Hardware-Aware Evolutionary Search
Aug 27, 2024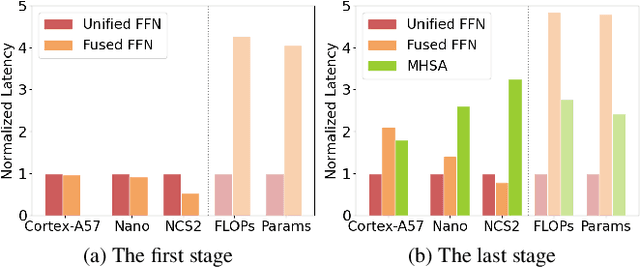
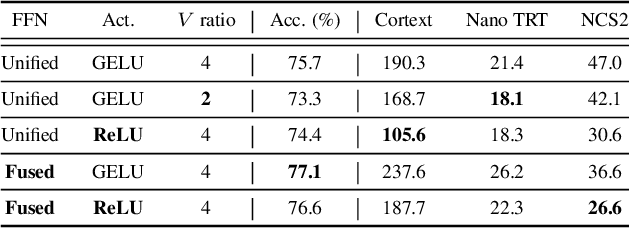
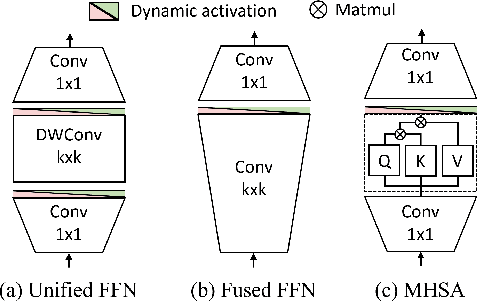
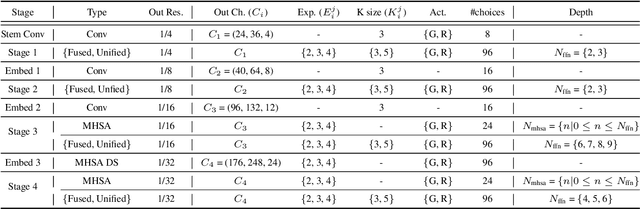
Designing low-latency and high-efficiency hybrid networks for a variety of low-cost commodity edge devices is both costly and tedious, leading to the adoption of hardware-aware neural architecture search (NAS) for finding optimal architectures. However, unifying NAS for a wide range of edge devices presents challenges due to the variety of hardware designs, supported operations, and compilation optimizations. Existing methods often fix the search space of architecture choices (e.g., activation, convolution, or self-attention) and estimate latency using hardware-agnostic proxies (e.g., FLOPs), which fail to achieve proclaimed latency across various edge devices. To address this issue, we propose SCAN-Edge, a unified NAS framework that jointly searches for self-attention, convolution, and activation to accommodate the wide variety of edge devices, including CPU-, GPU-, and hardware accelerator-based systems. To handle the large search space, SCAN-Edge relies on with a hardware-aware evolutionary algorithm that improves the quality of the search space to accelerate the sampling process. Experiments on large-scale datasets demonstrate that our hybrid networks match the actual MobileNetV2 latency for 224x224 input resolution on various commodity edge devices.
Efficient Low-rank Backpropagation for Vision Transformer Adaptation
Sep 26, 2023
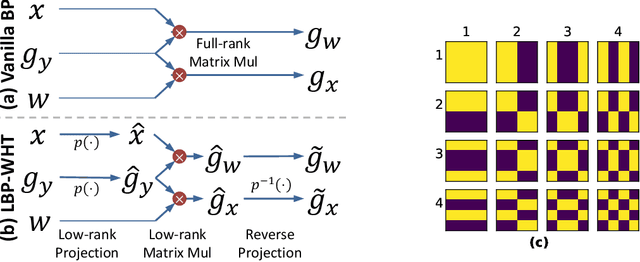


The increasing scale of vision transformers (ViT) has made the efficient fine-tuning of these large models for specific needs a significant challenge in various applications. This issue originates from the computationally demanding matrix multiplications required during the backpropagation process through linear layers in ViT. In this paper, we tackle this problem by proposing a new Low-rank BackPropagation via Walsh-Hadamard Transformation (LBP-WHT) method. Intuitively, LBP-WHT projects the gradient into a low-rank space and carries out backpropagation. This approach substantially reduces the computation needed for adapting ViT, as matrix multiplication in the low-rank space is far less resource-intensive. We conduct extensive experiments with different models (ViT, hybrid convolution-ViT model) on multiple datasets to demonstrate the effectiveness of our method. For instance, when adapting an EfficientFormer-L1 model on CIFAR100, our LBP-WHT achieves 10.4% higher accuracy than the state-of-the-art baseline, while requiring 9 MFLOPs less computation. As the first work to accelerate ViT adaptation with low-rank backpropagation, our LBP-WHT method is complementary to many prior efforts and can be combined with them for better performance.
MobileTL: On-device Transfer Learning with Inverted Residual Blocks
Dec 05, 2022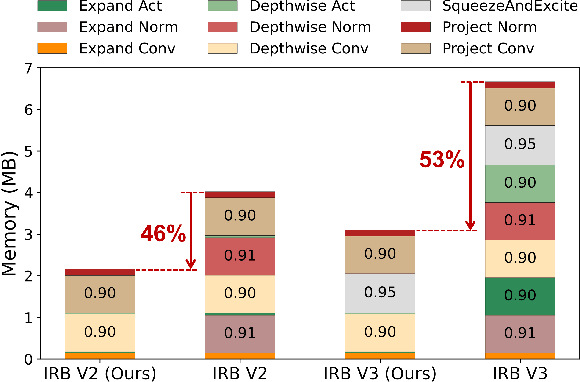
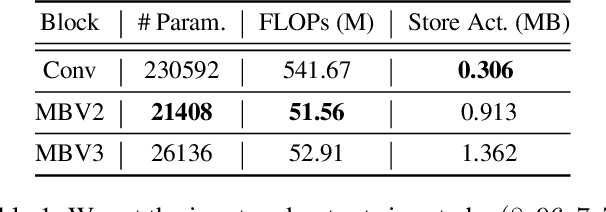
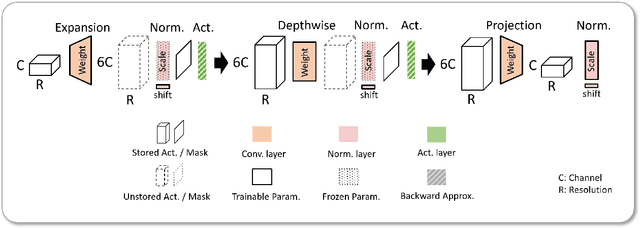

Transfer learning on edge is challenging due to on-device limited resources. Existing work addresses this issue by training a subset of parameters or adding model patches. Developed with inference in mind, Inverted Residual Blocks (IRBs) split a convolutional layer into depthwise and pointwise convolutions, leading to more stacking layers, e.g., convolution, normalization, and activation layers. Though they are efficient for inference, IRBs require that additional activation maps are stored in memory for training weights for convolution layers and scales for normalization layers. As a result, their high memory cost prohibits training IRBs on resource-limited edge devices, and making them unsuitable in the context of transfer learning. To address this issue, we present MobileTL, a memory and computationally efficient on-device transfer learning method for models built with IRBs. MobileTL trains the shifts for internal normalization layers to avoid storing activation maps for the backward pass. Also, MobileTL approximates the backward computation of the activation layer (e.g., Hard-Swish and ReLU6) as a signed function which enables storing a binary mask instead of activation maps for the backward pass. MobileTL fine-tunes a few top blocks (close to output) rather than propagating the gradient through the whole network to reduce the computation cost. Our method reduces memory usage by 46% and 53% for MobileNetV2 and V3 IRBs, respectively. For MobileNetV3, we observe a 36% reduction in floating-point operations (FLOPs) when fine-tuning 5 blocks, while only incurring a 0.6% accuracy reduction on CIFAR10. Extensive experiments on multiple datasets demonstrate that our method is Pareto-optimal (best accuracy under given hardware constraints) compared to prior work in transfer learning for edge devices.
FOX-NAS: Fast, On-device and Explainable Neural Architecture Search
Aug 14, 2021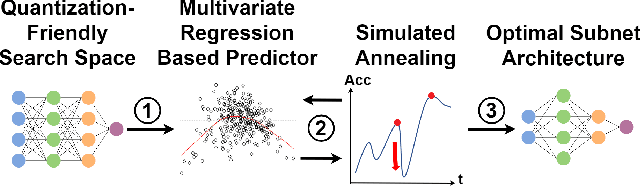
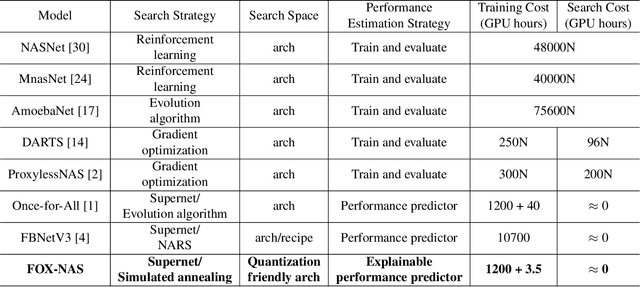
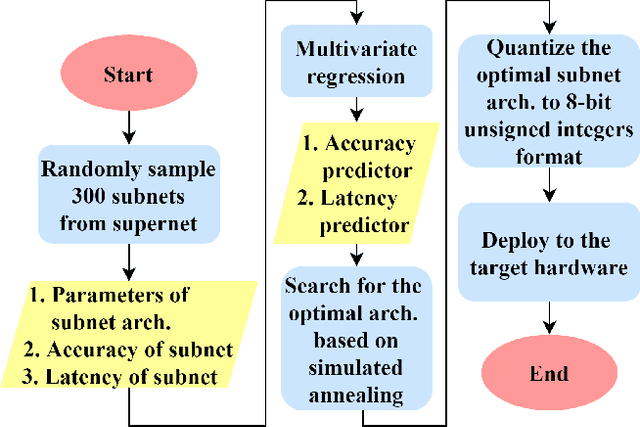
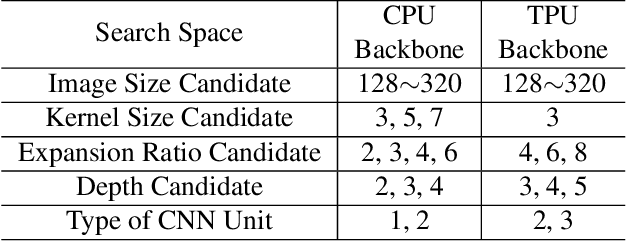
Neural architecture search can discover neural networks with good performance, and One-Shot approaches are prevalent. One-Shot approaches typically require a supernet with weight sharing and predictors that predict the performance of architecture. However, the previous methods take much time to generate performance predictors thus are inefficient. To this end, we propose FOX-NAS that consists of fast and explainable predictors based on simulated annealing and multivariate regression. Our method is quantization-friendly and can be efficiently deployed to the edge. The experiments on different hardware show that FOX-NAS models outperform some other popular neural network architectures. For example, FOX-NAS matches MobileNetV2 and EfficientNet-Lite0 accuracy with 240% and 40% less latency on the edge CPU. FOX-NAS is the 3rd place winner of the 2020 Low-Power Computer Vision Challenge (LPCVC), DSP classification track. See all evaluation results at https://lpcv.ai/competitions/2020. Search code and pre-trained models are released at https://github.com/great8nctu/FOX-NAS.
Learning from 2D: Pixel-to-Point Knowledge Transfer for 3D Pretraining
Apr 10, 2021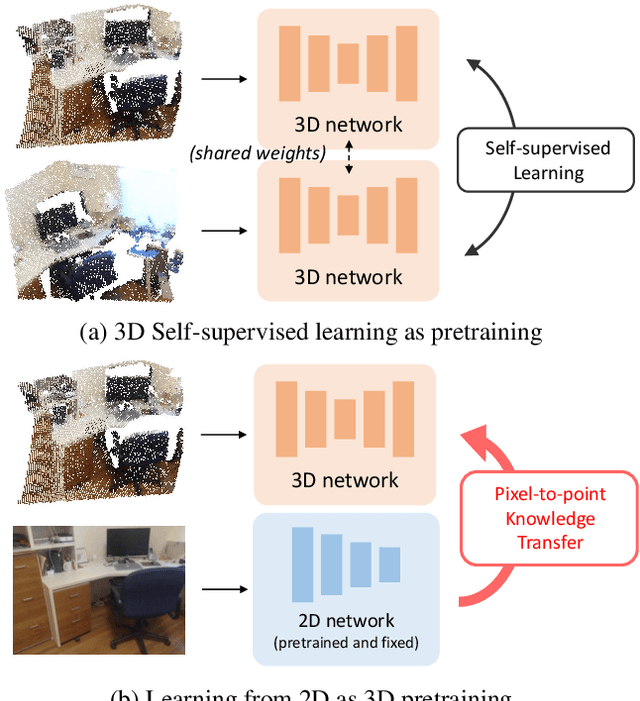
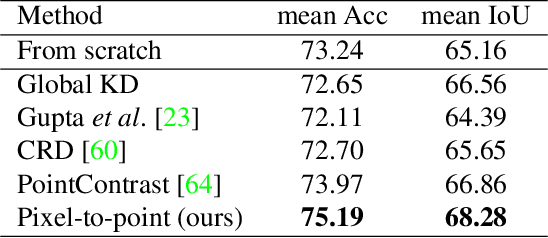
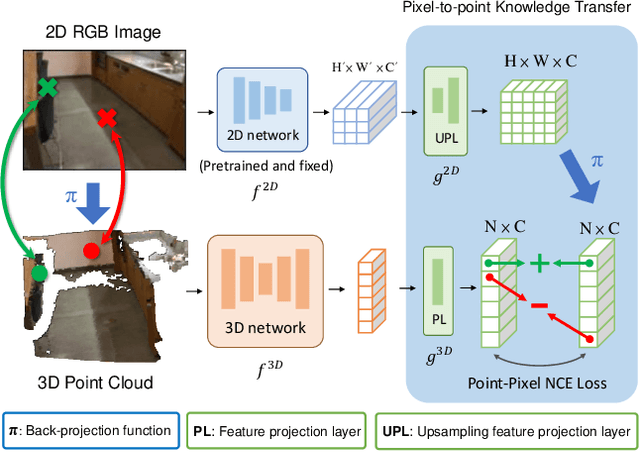
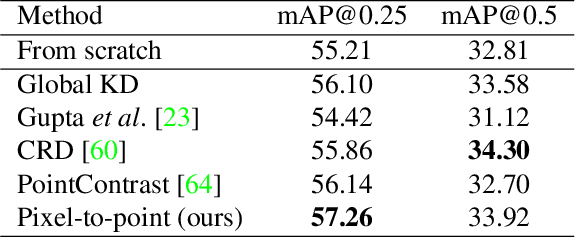
Most of the 3D networks are trained from scratch owning to the lack of large-scale labeled datasets. In this paper, we present a novel 3D pretraining method by leveraging 2D networks learned from rich 2D datasets. We propose the pixel-to-point knowledge transfer to effectively utilize the 2D information by mapping the pixel-level and point-level features into the same embedding space. Due to the heterogeneous nature between 2D and 3D networks, we introduce the back-projection function to align the features between 2D and 3D to make the transfer possible. Additionally, we devise an upsampling feature projection layer to increase the spatial resolution of high-level 2D feature maps, which helps learning fine-grained 3D representations. With a pretrained 2D network, the proposed pretraining process requires no additional 2D or 3D labeled data, further alleviating the expansive 3D data annotation cost. To the best of our knowledge, we are the first to exploit existing 2D trained weights to pretrain 3D deep neural networks. Our intensive experiments show that the 3D models pretrained with 2D knowledge boost the performances across various real-world 3D downstream tasks.