 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022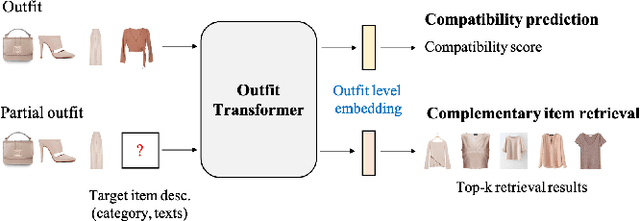

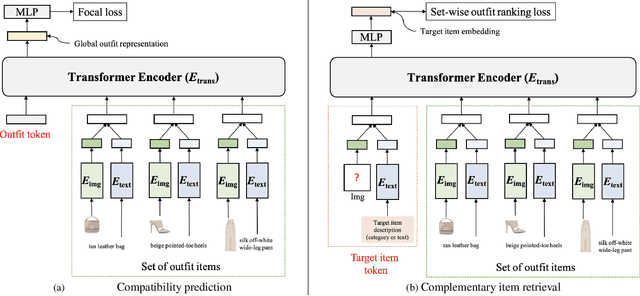
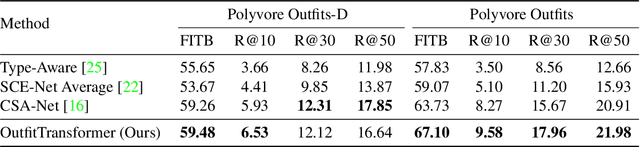
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.
SLADE: A Self-Training Framework For Distance Metric Learning
Nov 20, 2020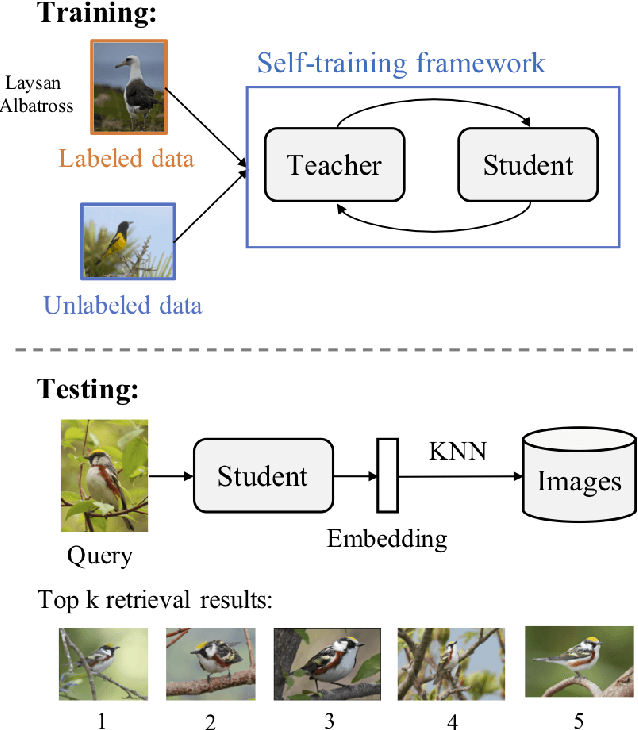
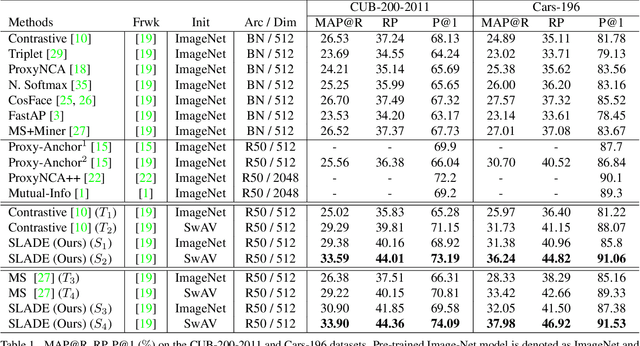
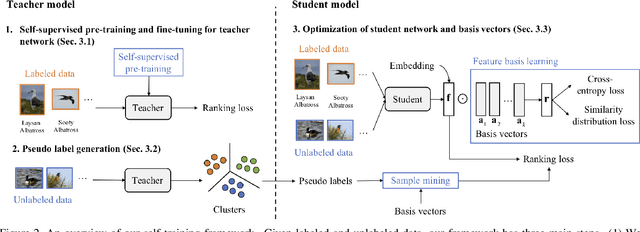
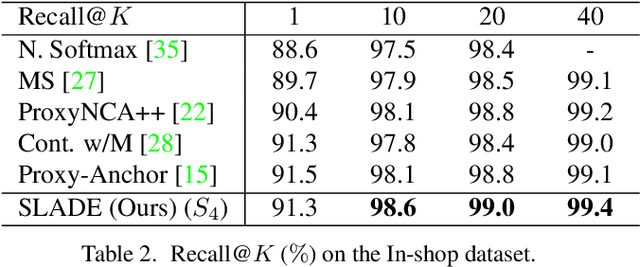
Most existing distance metric learning approaches use fully labeled data to learn the sample similarities in an embedding space. We present a self-training framework, SLADE, to improve retrieval performance by leveraging additional unlabeled data. We first train a teacher model on the labeled data and use it to generate pseudo labels for the unlabeled data. We then train a student model on both labels and pseudo labels to generate final feature embeddings. We use self-supervised representation learning to initialize the teacher model. To better deal with noisy pseudo labels generated by the teacher network, we design a new feature basis learning component for the student network, which learns basis functions of feature representations for unlabeled data. The learned basis vectors better measure the pairwise similarity and are used to select high-confident samples for training the student network. We evaluate our method on standard retrieval benchmarks: CUB-200, Cars-196 and In-shop. Experimental results demonstrate that our approach significantly improves the performance over the state-of-the-art methods.
Fashion Outfit Complementary Item Retrieval
Dec 19, 2019

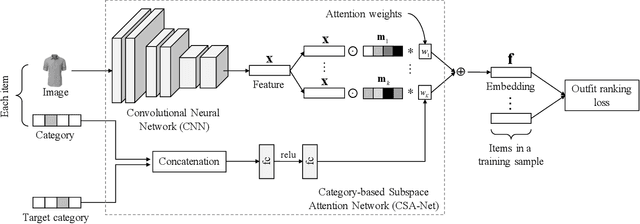

Complementary fashion item recommendation is critical for fashion outfit completion. Existing methods mainly focus on outfit compatibility prediction but not in a retrieval setting. We propose a new framework for outfit complementary item retrieval. Specifically, a category-based subspace attention network is presented, which is a scalable approach for learning the subspace attentions. In addition, we introduce an outfit ranking loss that better models the item relationships of an entire outfit. We evaluate our method on the outfit compatibility, FITB and new retrieval tasks. Experimental results demonstrate that our approach outperforms state-of-the-art methods in both compatibility prediction and complementary item retrieval
A Unified Point-Based Framework for 3D Segmentation
Aug 18, 2019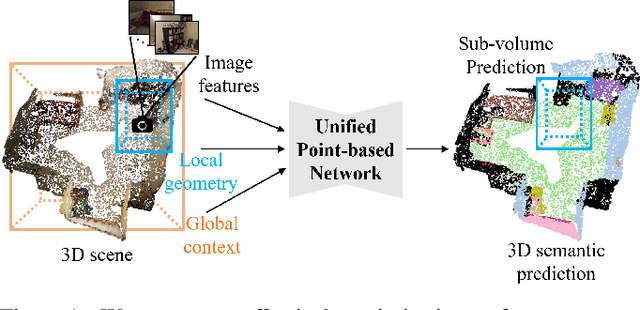

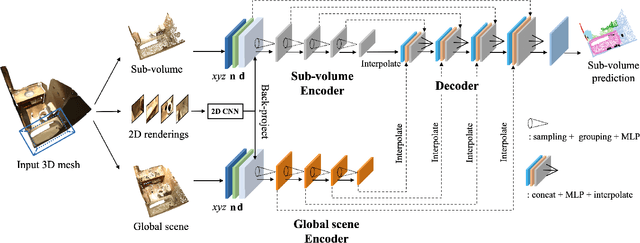
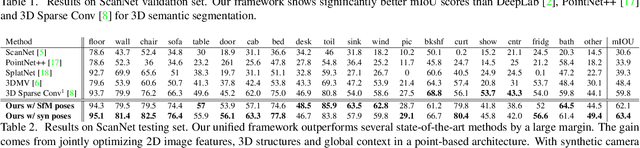
3D point cloud segmentation remains challenging for structureless and textureless regions. We present a new unified point-based framework for 3D point cloud segmentation that effectively optimizes pixel-level features, geometrical structures and global context priors of an entire scene. By back-projecting 2D image features into 3D coordinates, our network learns 2D textural appearance and 3D structural features in a unified framework. In addition, we investigate a global context prior to obtain a better prediction. We evaluate our framework on ScanNet online benchmark and show that our method outperforms several state-of-the-art approaches. We explore synthesizing camera poses in 3D reconstructed scenes for achieving higher performance. In-depth analysis on feature combinations and synthetic camera pose verify that features from different modalities benefit each other and dense camera pose sampling further improves the segmentation results.
Primitive-based 3D Building Modeling, Sensor Simulation, and Estimation
Jan 16, 2019
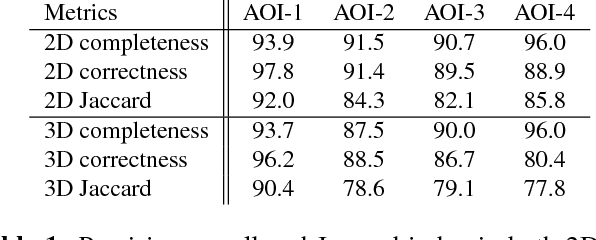
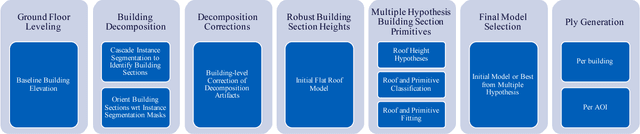
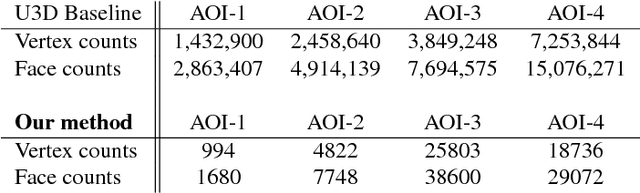
As we begin to consider modeling large, realistic 3D building scenes, it becomes necessary to consider a more compact representation over the polygonal mesh model. Due to the large amounts of annotated training data, which is costly to obtain, we leverage synthetic data to train our system for the satellite image domain. By utilizing the synthetic data, we formulate the building decomposition as an application of instance segmentation and primitive fitting to decompose a building into a set of primitive shapes. Experimental results on WorldView-3 satellite image dataset demonstrate the effectiveness of our 3D building modeling approach.
DCAN: Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation
Apr 16, 2018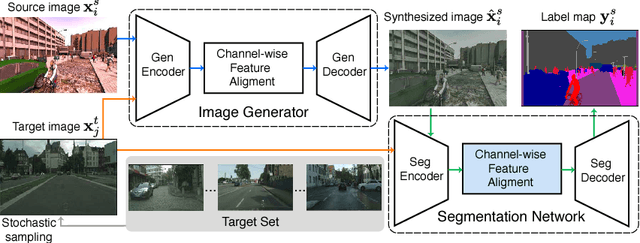



Harvesting dense pixel-level annotations to train deep neural networks for semantic segmentation is extremely expensive and unwieldy at scale. While learning from synthetic data where labels are readily available sounds promising, performance degrades significantly when testing on novel realistic data due to domain discrepancies. We present Dual Channel-wise Alignment Networks (DCAN), a simple yet effective approach to reduce domain shift at both pixel-level and feature-level. Exploring statistics in each channel of CNN feature maps, our framework performs channel-wise feature alignment, which preserves spatial structures and semantic information, in both an image generator and a segmentation network. In particular, given an image from the source domain and unlabeled samples from the target domain, the generator synthesizes new images on-the-fly to resemble samples from the target domain in appearance and the segmentation network further refines high-level features before predicting semantic maps, both of which leverage feature statistics of sampled images from the target domain. Unlike much recent and concurrent work relying on adversarial training, our framework is lightweight and easy to train. Extensive experiments on adapting models trained on synthetic segmentation benchmarks to real urban scenes demonstrate the effectiveness of the proposed framework.
Drone-based Object Counting by Spatially Regularized Regional Proposal Network
Aug 03, 2017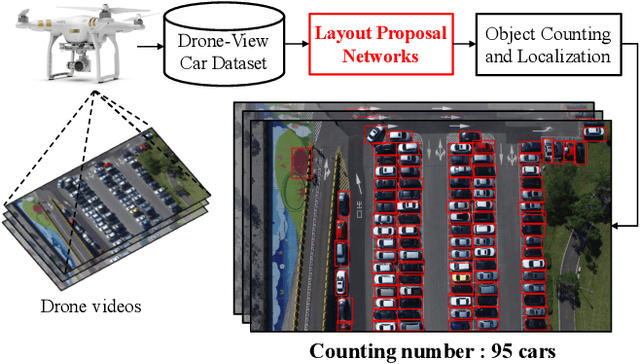


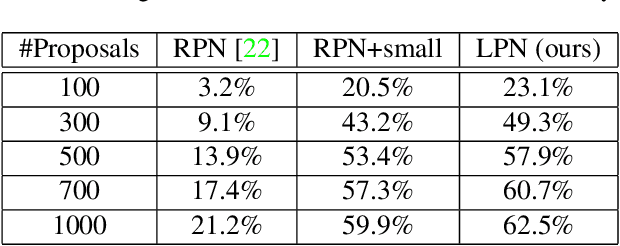
Existing counting methods often adopt regression-based approaches and cannot precisely localize the target objects, which hinders the further analysis (e.g., high-level understanding and fine-grained classification). In addition, most of prior work mainly focus on counting objects in static environments with fixed cameras. Motivated by the advent of unmanned flying vehicles (i.e., drones), we are interested in detecting and counting objects in such dynamic environments. We propose Layout Proposal Networks (LPNs) and spatial kernels to simultaneously count and localize target objects (e.g., cars) in videos recorded by the drone. Different from the conventional region proposal methods, we leverage the spatial layout information (e.g., cars often park regularly) and introduce these spatially regularized constraints into our network to improve the localization accuracy. To evaluate our counting method, we present a new large-scale car parking lot dataset (CARPK) that contains nearly 90,000 cars captured from different parking lots. To the best of our knowledge, it is the first and the largest drone view dataset that supports object counting, and provides the bounding box annotations.
Joint Sequence Learning and Cross-Modality Convolution for 3D Biomedical Segmentation
Apr 25, 2017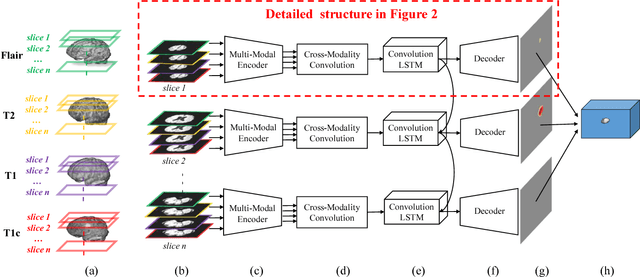

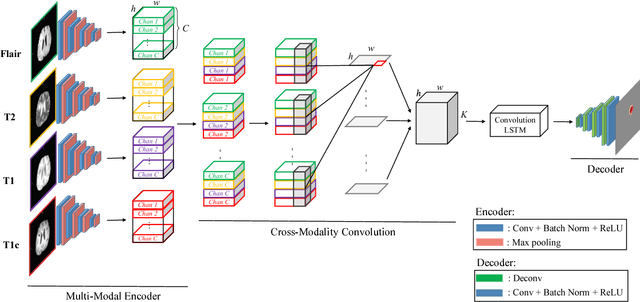
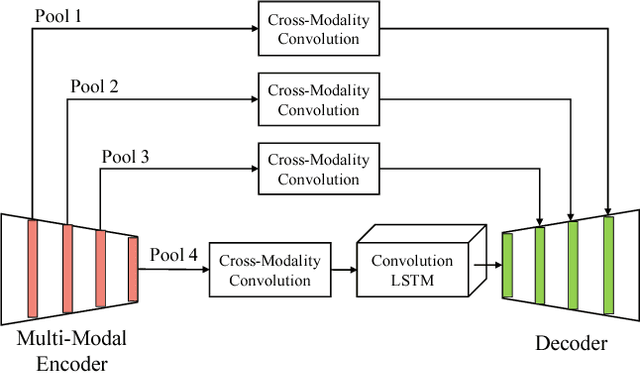
Deep learning models such as convolutional neural net- work have been widely used in 3D biomedical segmentation and achieve state-of-the-art performance. However, most of them often adapt a single modality or stack multiple modalities as different input channels. To better leverage the multi- modalities, we propose a deep encoder-decoder structure with cross-modality convolution layers to incorporate different modalities of MRI data. In addition, we exploit convolutional LSTM to model a sequence of 2D slices, and jointly learn the multi-modalities and convolutional LSTM in an end-to-end manner. To avoid converging to the certain labels, we adopt a re-weighting scheme and two-phase training to handle the label imbalance. Experimental results on BRATS-2015 show that our method outperforms state-of-the-art biomedical segmentation approaches.