 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInVi: Object Insertion In Videos Using Off-the-Shelf Diffusion Models
Jul 15, 2024

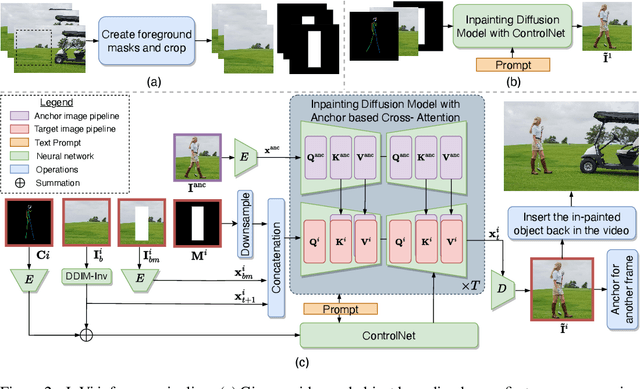

We introduce InVi, an approach for inserting or replacing objects within videos (referred to as inpainting) using off-the-shelf, text-to-image latent diffusion models. InVi targets controlled manipulation of objects and blending them seamlessly into a background video unlike existing video editing methods that focus on comprehensive re-styling or entire scene alterations. To achieve this goal, we tackle two key challenges. Firstly, for high quality control and blending, we employ a two-step process involving inpainting and matching. This process begins with inserting the object into a single frame using a ControlNet-based inpainting diffusion model, and then generating subsequent frames conditioned on features from an inpainted frame as an anchor to minimize the domain gap between the background and the object. Secondly, to ensure temporal coherence, we replace the diffusion model's self-attention layers with extended-attention layers. The anchor frame features serve as the keys and values for these layers, enhancing consistency across frames. Our approach removes the need for video-specific fine-tuning, presenting an efficient and adaptable solution. Experimental results demonstrate that InVi achieves realistic object insertion with consistent blending and coherence across frames, outperforming existing methods.
OutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022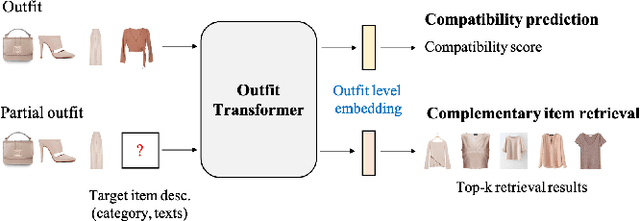

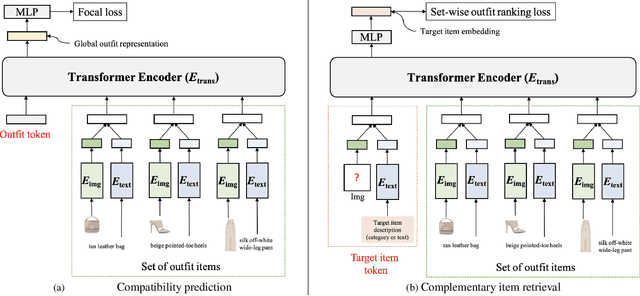
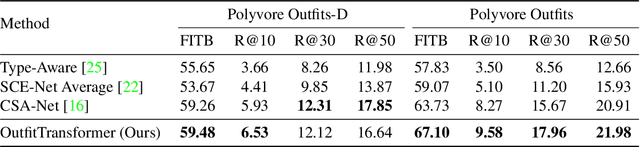
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.
Deep Regionlets for Object Detection
Aug 23, 2018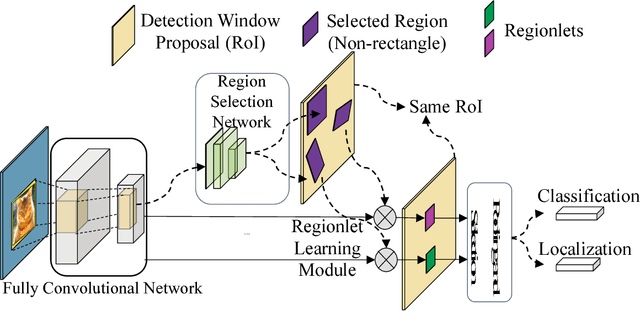
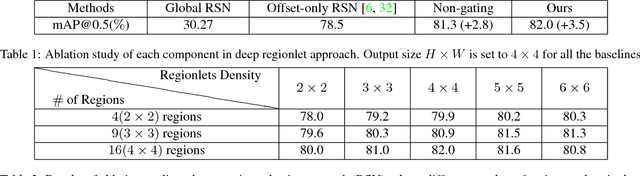
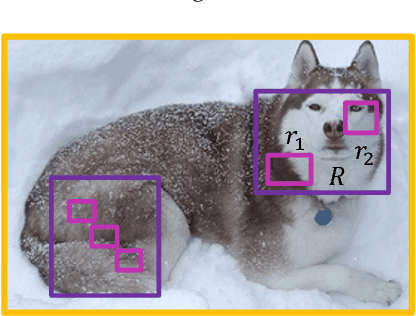
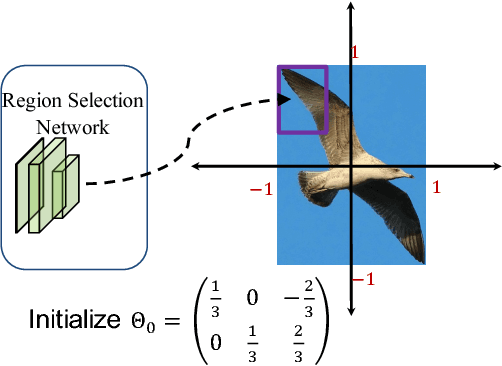
In this paper, we propose a novel object detection framework named "Deep Regionlets" by establishing a bridge between deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the abilities of regionlets for modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions to learn the features from. The regionlet learning module focuses on local feature selection and transformation to alleviate local variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We perform ablation studies and conduct extensive experiments on the PASCAL VOC and Microsoft COCO datasets. The proposed framework outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
Soft Sampling for Robust Object Detection
Jun 18, 2018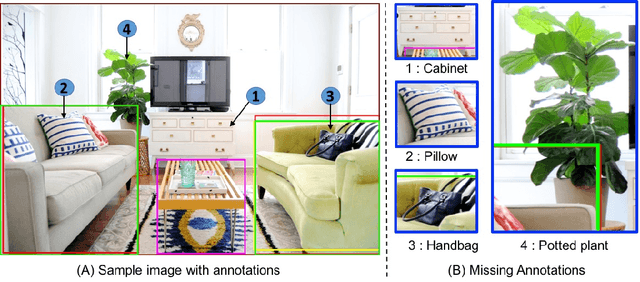
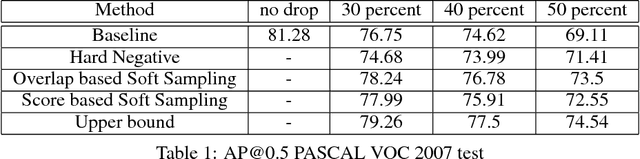
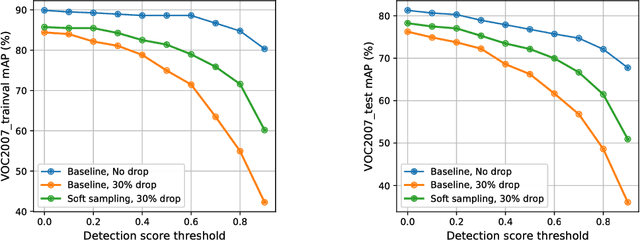
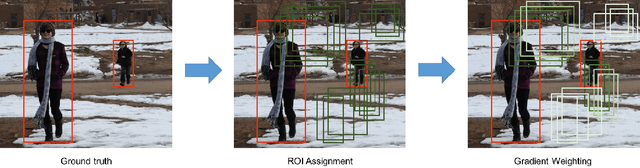
We study the robustness of object detection under the presence of missing annotations. In this setting, the unlabeled object instances will be treated as background, which will generate an incorrect training signal for the detector. Interestingly, we observe that after dropping 30% of the annotations (and labeling them as background), the performance of CNN-based object detectors like Faster-RCNN only drops by 5% on the PASCAL VOC dataset. We provide a detailed explanation for this result. To further bridge the performance gap, we propose a simple yet effective solution, called Soft Sampling. Soft Sampling re-weights the gradients of RoIs as a function of overlap with positive instances. This ensures that the uncertain background regions are given a smaller weight compared to the hardnegatives. Extensive experiments on curated PASCAL VOC datasets demonstrate the effectiveness of the proposed Soft Sampling method at different annotation drop rates. Finally, we show that on OpenImagesV3, which is a real-world dataset with missing annotations, Soft Sampling outperforms standard detection baselines by over 3%.
Semi-supervised FusedGAN for Conditional Image Generation
Jan 17, 2018

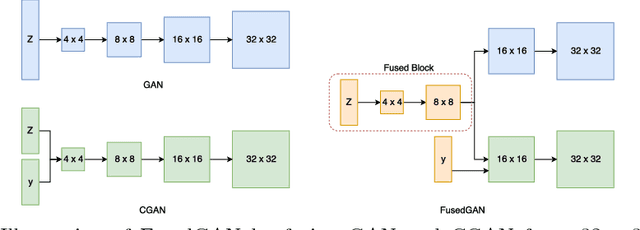

We present FusedGAN, a deep network for conditional image synthesis with controllable sampling of diverse images. Fidelity, diversity and controllable sampling are the main quality measures of a good image generation model. Most existing models are insufficient in all three aspects. The FusedGAN can perform controllable sampling of diverse images with very high fidelity. We argue that controllability can be achieved by disentangling the generation process into various stages. In contrast to stacked GANs, where multiple stages of GANs are trained separately with full supervision of labeled intermediate images, the FusedGAN has a single stage pipeline with a built-in stacking of GANs. Unlike existing methods, which requires full supervision with paired conditions and images, the FusedGAN can effectively leverage more abundant images without corresponding conditions in training, to produce more diverse samples with high fidelity. We achieve this by fusing two generators: one for unconditional image generation, and the other for conditional image generation, where the two partly share a common latent space thereby disentangling the generation. We demonstrate the efficacy of the FusedGAN in fine grained image generation tasks such as text-to-image, and attribute-to-face generation.
Soft-NMS -- Improving Object Detection With One Line of Code
Aug 08, 2017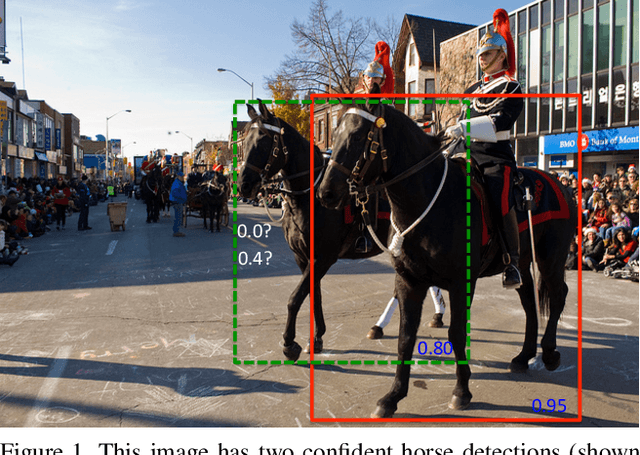



Non-maximum suppression is an integral part of the object detection pipeline. First, it sorts all detection boxes on the basis of their scores. The detection box M with the maximum score is selected and all other detection boxes with a significant overlap (using a pre-defined threshold) with M are suppressed. This process is recursively applied on the remaining boxes. As per the design of the algorithm, if an object lies within the predefined overlap threshold, it leads to a miss. To this end, we propose Soft-NMS, an algorithm which decays the detection scores of all other objects as a continuous function of their overlap with M. Hence, no object is eliminated in this process. Soft-NMS obtains consistent improvements for the coco-style mAP metric on standard datasets like PASCAL VOC 2007 (1.7% for both R-FCN and Faster-RCNN) and MS-COCO (1.3% for R-FCN and 1.1% for Faster-RCNN) by just changing the NMS algorithm without any additional hyper-parameters. Using Deformable-RFCN, Soft-NMS improves state-of-the-art in object detection from 39.8% to 40.9% with a single model. Further, the computational complexity of Soft-NMS is the same as traditional NMS and hence it can be efficiently implemented. Since Soft-NMS does not require any extra training and is simple to implement, it can be easily integrated into any object detection pipeline. Code for Soft-NMS is publicly available on GitHub (http://bit.ly/2nJLNMu).
Deep Heterogeneous Feature Fusion for Template-Based Face Recognition
Feb 15, 2017
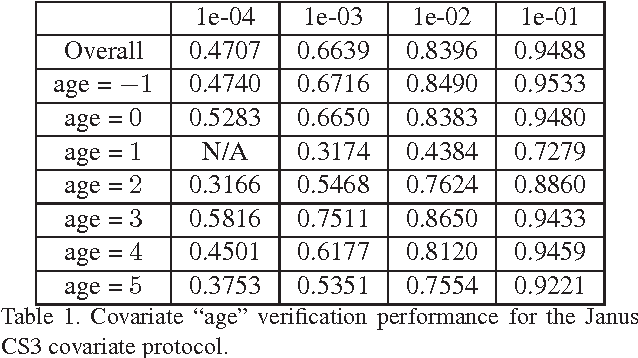
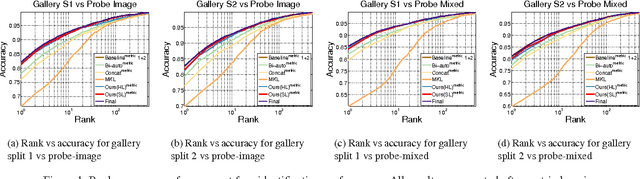
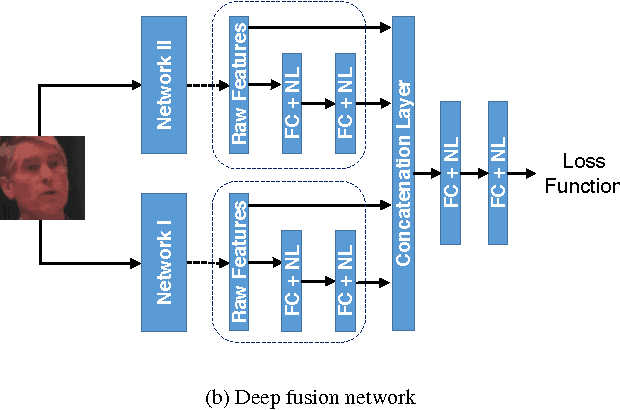
Although deep learning has yielded impressive performance for face recognition, many studies have shown that different networks learn different feature maps: while some networks are more receptive to pose and illumination others appear to capture more local information. Thus, in this work, we propose a deep heterogeneous feature fusion network to exploit the complementary information present in features generated by different deep convolutional neural networks (DCNNs) for template-based face recognition, where a template refers to a set of still face images or video frames from different sources which introduces more blur, pose, illumination and other variations than traditional face datasets. The proposed approach efficiently fuses the discriminative information of different deep features by 1) jointly learning the non-linear high-dimensional projection of the deep features and 2) generating a more discriminative template representation which preserves the inherent geometry of the deep features in the feature space. Experimental results on the IARPA Janus Challenge Set 3 (Janus CS3) dataset demonstrate that the proposed method can effectively improve the recognition performance. In addition, we also present a series of covariate experiments on the face verification task for in-depth qualitative evaluations for the proposed approach.