 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
Apr 08, 2023Recent advancements in Natural Language Processing (NLP) have led to the development of NLP-based recommender systems that have shown superior performance. However, current models commonly treat items as mere IDs and adopt discriminative modeling, resulting in limitations of (1) fully leveraging the content information of items and the language modeling capabilities of NLP models; (2) interpreting user interests to improve relevance and diversity; and (3) adapting practical circumstances such as growing item inventories. To address these limitations, we present GPT4Rec, a novel and flexible generative framework inspired by search engines. It first generates hypothetical "search queries" given item titles in a user's history, and then retrieves items for recommendation by searching these queries. The framework overcomes previous limitations by learning both user and item embeddings in the language space. To well-capture user interests with different aspects and granularity for improving relevance and diversity, we propose a multi-query generation technique with beam search. The generated queries naturally serve as interpretable representations of user interests and can be searched to recommend cold-start items. With GPT-2 language model and BM25 search engine, our framework outperforms state-of-the-art methods by $75.7\%$ and $22.2\%$ in Recall@K on two public datasets. Experiments further revealed that multi-query generation with beam search improves both the diversity of retrieved items and the coverage of a user's multi-interests. The adaptiveness and interpretability of generated queries are discussed with qualitative case studies.
Contrastive Learning for Interactive Recommendation in Fashion
Jul 25, 2022
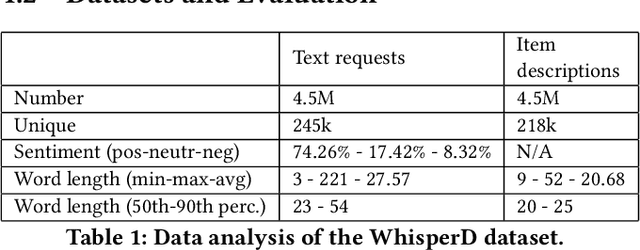
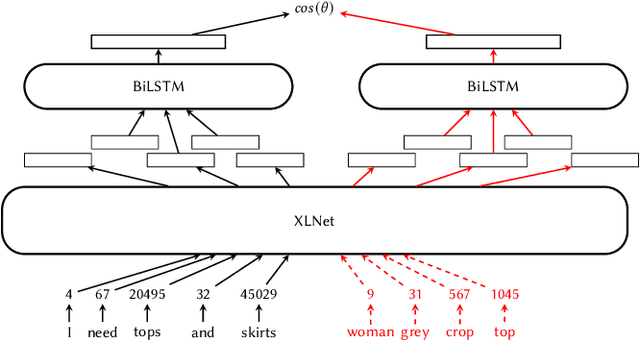
Recommender systems and search are both indispensable in facilitating personalization and ease of browsing in online fashion platforms. However, the two tools often operate independently, failing to combine the strengths of recommender systems to accurately capture user tastes with search systems' ability to process user queries. We propose a novel remedy to this problem by automatically recommending personalized fashion items based on a user-provided text request. Our proposed model, WhisperLite, uses contrastive learning to capture user intent from natural language text and improves the recommendation quality of fashion products. WhisperLite combines the strength of CLIP embeddings with additional neural network layers for personalization, and is trained using a composite loss function based on binary cross entropy and contrastive loss. The model demonstrates a significant improvement in offline recommendation retrieval metrics when tested on a real-world dataset collected from an online retail fashion store, as well as widely used open-source datasets in different e-commerce domains, such as restaurants, movies and TV shows, clothing and shoe reviews. We additionally conduct a user study that captures user judgements on the relevance of the model's recommended items, confirming the relevancy of WhisperLite's recommendations in an online setting.
OutfitTransformer: Learning Outfit Representations for Fashion Recommendation
Apr 15, 2022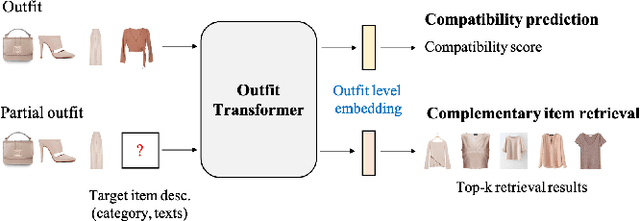

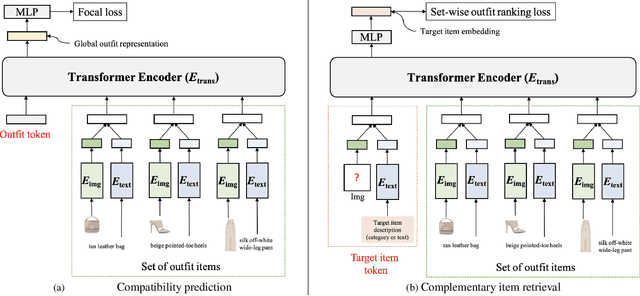
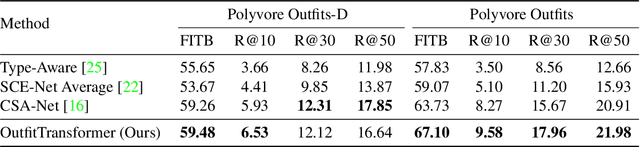
Learning an effective outfit-level representation is critical for predicting the compatibility of items in an outfit, and retrieving complementary items for a partial outfit. We present a framework, OutfitTransformer, that uses the proposed task-specific tokens and leverages the self-attention mechanism to learn effective outfit-level representations encoding the compatibility relationships between all items in the entire outfit for addressing both compatibility prediction and complementary item retrieval tasks. For compatibility prediction, we design an outfit token to capture a global outfit representation and train the framework using a classification loss. For complementary item retrieval, we design a target item token that additionally takes the target item specification (in the form of a category or text description) into consideration. We train our framework using a proposed set-wise outfit ranking loss to generate a target item embedding given an outfit, and a target item specification as inputs. The generated target item embedding is then used to retrieve compatible items that match the rest of the outfit. Additionally, we adopt a pre-training approach and a curriculum learning strategy to improve retrieval performance. Since our framework learns at an outfit-level, it allows us to learn a single embedding capturing higher-order relations among multiple items in the outfit more effectively than pairwise methods. Experiments demonstrate that our approach outperforms state-of-the-art methods on compatibility prediction, fill-in-the-blank, and complementary item retrieval tasks. We further validate the quality of our retrieval results with a user study.