 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSonata: A Hybrid World Model for Inertial Kinematics under Clinical Data Scarcity
Apr 20, 2026We introduce Sonata, a compact latent world model for six-axis trunk IMU representation learning under clinical data scarcity. Clinical cohorts typically comprise tens to hundreds of patients, making web-scale masked-reconstruction objectives poorly matched to the problem. Sonata is a 3.77 M-parameter hybrid model, pre-trained on a harmonised corpus of nine public datasets (739 subjects, 190k windows) with a latent world-model objective that predicts future state rather than reconstructing raw sensor traces. In a controlled comparison against a matched autoregressive forecasting baseline (MAE) on the same backbone, Sonata yields consistently stronger frozen-probe clinical discrimination, prospective fall-risk prediction, and cross-cohort transfer across a 14-arm evaluation suite, while producing higher-rank, more structured latent representations. At 3.77 M parameters the model is compatible with on-device wearable inference, offering a step toward general kinematic world models for neurological assessment.
The Role of Mixed-Language Documents for Multilingual Large Language Model Pretraining
Jan 01, 2026Multilingual large language models achieve impressive cross-lingual performance despite largely monolingual pretraining. While bilingual data in pretraining corpora is widely believed to enable these abilities, details of its contributions remain unclear. We investigate this question by pretraining models from scratch under controlled conditions, comparing the standard web corpus with a monolingual-only version that removes all multilingual documents. Despite constituting only 2% of the corpus, removing bilingual data causes translation performance to drop 56% in BLEU, while behaviour on cross-lingual QA and general reasoning tasks remains stable, with training curves largely overlapping the baseline. To understand this asymmetry, we categorize bilingual data into parallel (14%), code-switching (72%), and miscellaneous documents (14%) based on the semantic relevance of content in different languages. We then conduct granular ablations by reintroducing parallel or code-switching data into the monolingual-only corpus. Our experiments reveal that parallel data almost fully restores translation performance (91% of the unfiltered baseline), whereas code-switching contributes minimally. Other cross-lingual tasks remain largely unaffected by either type. These findings reveal that translation critically depends on systematic token-level alignments from parallel data, whereas cross-lingual understanding and reasoning appear to be achievable even without bilingual data.
Contrastive Learning for Interactive Recommendation in Fashion
Jul 25, 2022
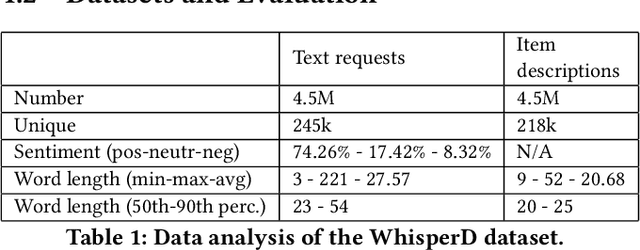
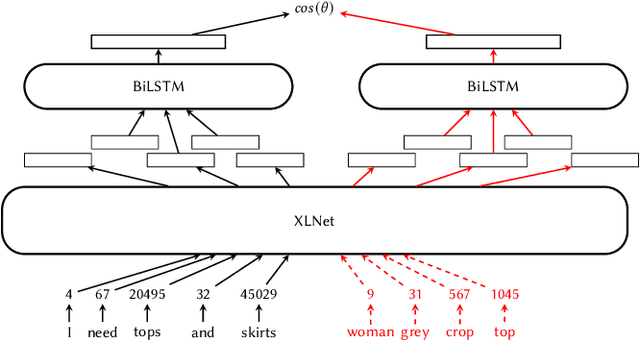
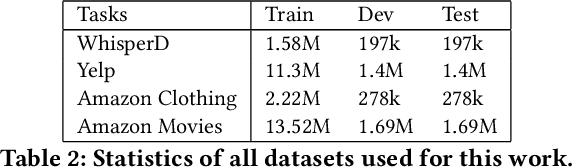
Recommender systems and search are both indispensable in facilitating personalization and ease of browsing in online fashion platforms. However, the two tools often operate independently, failing to combine the strengths of recommender systems to accurately capture user tastes with search systems' ability to process user queries. We propose a novel remedy to this problem by automatically recommending personalized fashion items based on a user-provided text request. Our proposed model, WhisperLite, uses contrastive learning to capture user intent from natural language text and improves the recommendation quality of fashion products. WhisperLite combines the strength of CLIP embeddings with additional neural network layers for personalization, and is trained using a composite loss function based on binary cross entropy and contrastive loss. The model demonstrates a significant improvement in offline recommendation retrieval metrics when tested on a real-world dataset collected from an online retail fashion store, as well as widely used open-source datasets in different e-commerce domains, such as restaurants, movies and TV shows, clothing and shoe reviews. We additionally conduct a user study that captures user judgements on the relevance of the model's recommended items, confirming the relevancy of WhisperLite's recommendations in an online setting.
OTTers: One-turn Topic Transitions for Open-Domain Dialogue
May 28, 2021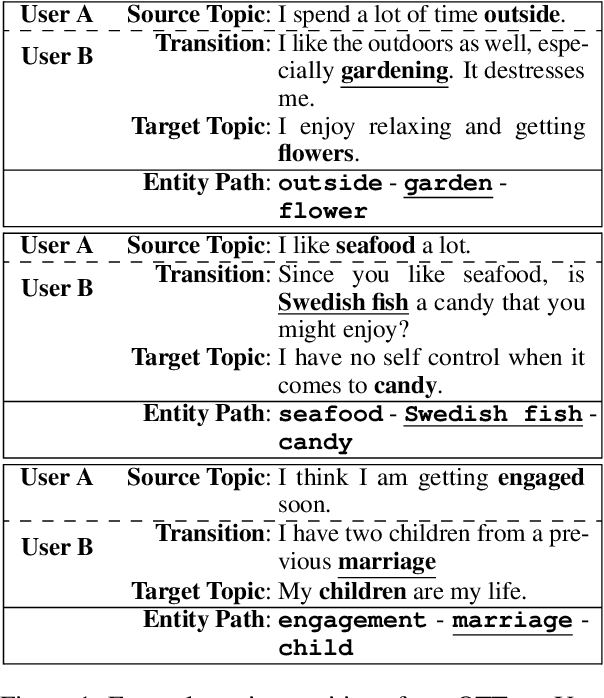



Mixed initiative in open-domain dialogue requires a system to pro-actively introduce new topics. The one-turn topic transition task explores how a system connects two topics in a cooperative and coherent manner. The goal of the task is to generate a "bridging" utterance connecting the new topic to the topic of the previous conversation turn. We are especially interested in commonsense explanations of how a new topic relates to what has been mentioned before. We first collect a new dataset of human one-turn topic transitions, which we call OTTers. We then explore different strategies used by humans when asked to complete such a task, and notice that the use of a bridging utterance to connect the two topics is the approach used the most. We finally show how existing state-of-the-art text generation models can be adapted to this task and examine the performance of these baselines on different splits of the OTTers data.
Automatic Quality Estimation for Natural Language Generation: Ranting (Jointly Rating and Ranking)
Oct 10, 2019
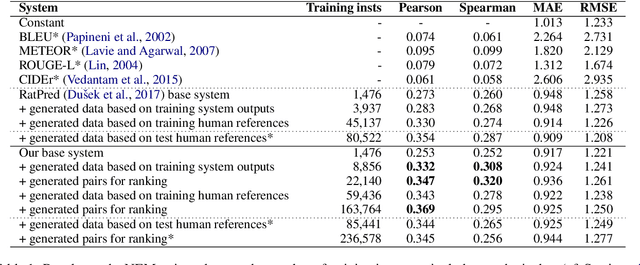
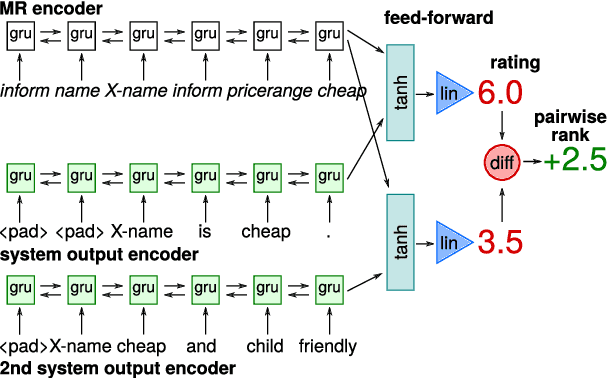

We present a recurrent neural network based system for automatic quality estimation of natural language generation (NLG) outputs, which jointly learns to assign numerical ratings to individual outputs and to provide pairwise rankings of two different outputs. The latter is trained using pairwise hinge loss over scores from two copies of the rating network. We use learning to rank and synthetic data to improve the quality of ratings assigned by our system: we synthesise training pairs of distorted system outputs and train the system to rank the less distorted one higher. This leads to a 12% increase in correlation with human ratings over the previous benchmark. We also establish the state of the art on the dataset of relative rankings from the E2E NLG Challenge (Du\v{s}ek et al., 2019), where synthetic data lead to a 4% accuracy increase over the base model.