 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Quality Estimation for Natural Language Generation: Ranting (Jointly Rating and Ranking)
Paper and Code

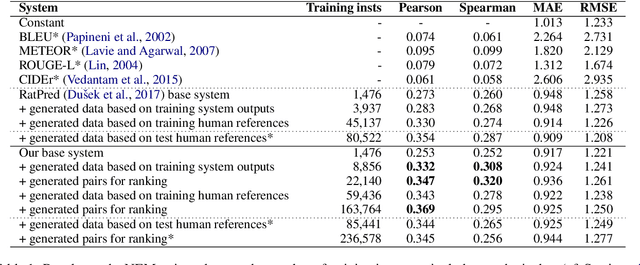
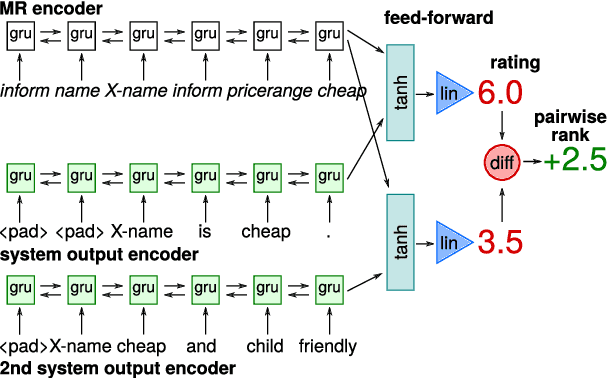

We present a recurrent neural network based system for automatic quality estimation of natural language generation (NLG) outputs, which jointly learns to assign numerical ratings to individual outputs and to provide pairwise rankings of two different outputs. The latter is trained using pairwise hinge loss over scores from two copies of the rating network. We use learning to rank and synthetic data to improve the quality of ratings assigned by our system: we synthesise training pairs of distorted system outputs and train the system to rank the less distorted one higher. This leads to a 12% increase in correlation with human ratings over the previous benchmark. We also establish the state of the art on the dataset of relative rankings from the E2E NLG Challenge (Du\v{s}ek et al., 2019), where synthetic data lead to a 4% accuracy increase over the base model.