 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan NLP Tackle Hate Speech in the Real World? Stakeholder-Informed Feedback and Survey on Counterspeech
Aug 06, 2025Counterspeech, i.e. the practice of responding to online hate speech, has gained traction in NLP as a promising intervention. While early work emphasised collaboration with non-governmental organisation stakeholders, recent research trends have shifted toward automated pipelines that reuse a small set of legacy datasets, often without input from affected communities. This paper presents a systematic review of 74 NLP studies on counterspeech, analysing the extent to which stakeholder participation influences dataset creation, model development, and evaluation. To complement this analysis, we conducted a participatory case study with five NGOs specialising in online Gender-Based Violence (oGBV), identifying stakeholder-informed practices for counterspeech generation. Our findings reveal a growing disconnect between current NLP research and the needs of communities most impacted by toxic online content. We conclude with concrete recommendations for re-centring stakeholder expertise in counterspeech research.
Reasoning or a Semblance of it? A Diagnostic Study of Transitive Reasoning in LLMs
Oct 26, 2024



Evaluating Large Language Models (LLMs) on reasoning benchmarks demonstrates their ability to solve compositional questions. However, little is known of whether these models engage in genuine logical reasoning or simply rely on implicit cues to generate answers. In this paper, we investigate the transitive reasoning capabilities of two distinct LLM architectures, LLaMA 2 and Flan-T5, by manipulating facts within two compositional datasets: QASC and Bamboogle. We controlled for potential cues that might influence the models' performance, including (a) word/phrase overlaps across sections of test input; (b) models' inherent knowledge during pre-training or fine-tuning; and (c) Named Entities. Our findings reveal that while both models leverage (a), Flan-T5 shows more resilience to experiments (b and c), having less variance than LLaMA 2. This suggests that models may develop an understanding of transitivity through fine-tuning on knowingly relevant datasets, a hypothesis we leave to future work.
CROPE: Evaluating In-Context Adaptation of Vision and Language Models to Culture-Specific Concepts
Oct 20, 2024As Vision and Language models (VLMs) become accessible across the globe, it is important that they demonstrate cultural knowledge. In this paper, we introduce CROPE, a visual question answering benchmark designed to probe the knowledge of culture-specific concepts and evaluate the capacity for cultural adaptation through contextual information. This allows us to distinguish between parametric knowledge acquired during training and contextual knowledge provided during inference via visual and textual descriptions. Our evaluation of several state-of-the-art open VLMs shows large performance disparities between culture-specific and common concepts in the parametric setting. Moreover, experiments with contextual knowledge indicate that models struggle to effectively utilize multimodal information and bind culture-specific concepts to their depictions. Our findings reveal limitations in the cultural understanding and adaptability of current VLMs that need to be addressed toward more culturally inclusive models.
Re-examining Sexism and Misogyny Classification with Annotator Attitudes
Oct 04, 2024



Gender-Based Violence (GBV) is an increasing problem online, but existing datasets fail to capture the plurality of possible annotator perspectives or ensure the representation of affected groups. We revisit two important stages in the moderation pipeline for GBV: (1) manual data labelling; and (2) automated classification. For (1), we examine two datasets to investigate the relationship between annotator identities and attitudes and the responses they give to two GBV labelling tasks. To this end, we collect demographic and attitudinal information from crowd-sourced annotators using three validated surveys from Social Psychology. We find that higher Right Wing Authoritarianism scores are associated with a higher propensity to label text as sexist, while for Social Dominance Orientation and Neosexist Attitudes, higher scores are associated with a negative tendency to do so. For (2), we conduct classification experiments using Large Language Models and five prompting strategies, including infusing prompts with annotator information. We find: (i) annotator attitudes affect the ability of classifiers to predict their labels; (ii) including attitudinal information can boost performance when we use well-structured brief annotator descriptions; and (iii) models struggle to reflect the increased complexity and imbalanced classes of the new label sets.
Voices in a Crowd: Searching for Clusters of Unique Perspectives
Jul 19, 2024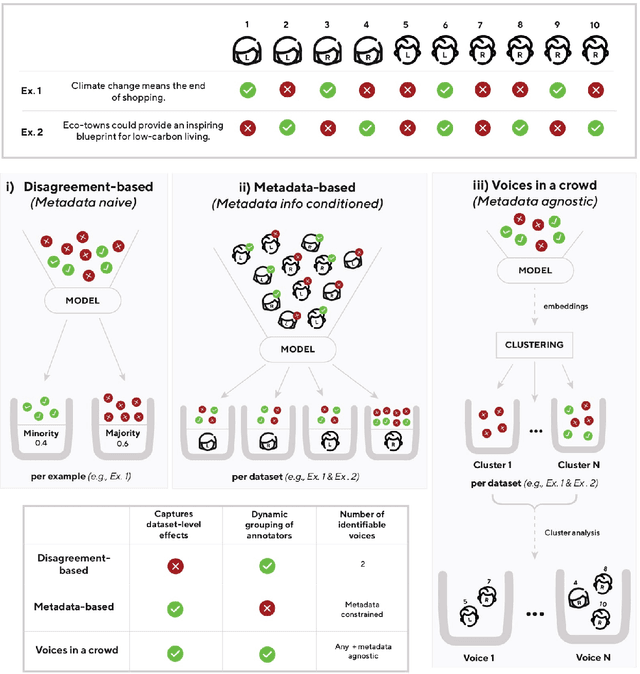
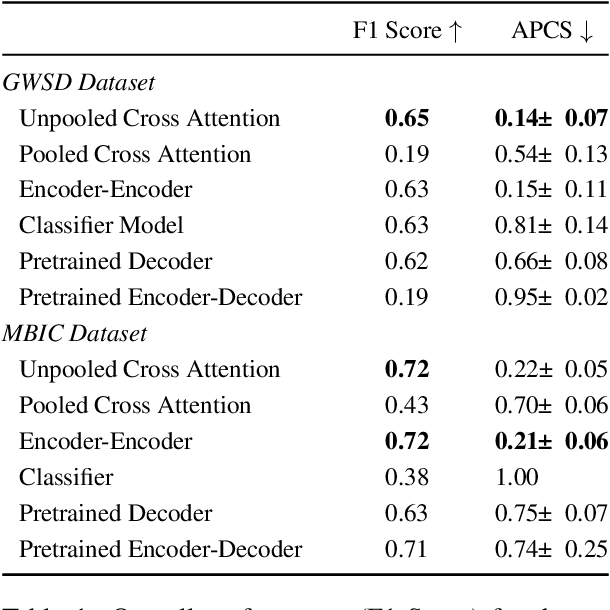
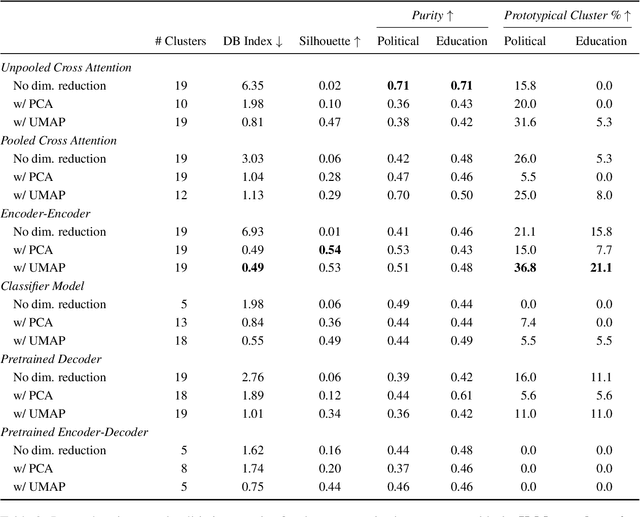
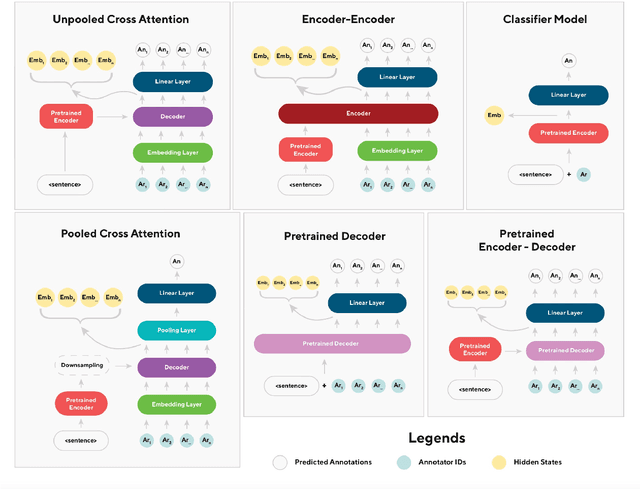
Language models have been shown to reproduce underlying biases existing in their training data, which is the majority perspective by default. Proposed solutions aim to capture minority perspectives by either modelling annotator disagreements or grouping annotators based on shared metadata, both of which face significant challenges. We propose a framework that trains models without encoding annotator metadata, extracts latent embeddings informed by annotator behaviour, and creates clusters of similar opinions, that we refer to as voices. Resulting clusters are validated post-hoc via internal and external quantitative metrics, as well a qualitative analysis to identify the type of voice that each cluster represents. Our results demonstrate the strong generalisation capability of our framework, indicated by resulting clusters being adequately robust, while also capturing minority perspectives based on different demographic factors throughout two distinct datasets.
Investigating the Role of Instruction Variety and Task Difficulty in Robotic Manipulation Tasks
Jul 04, 2024
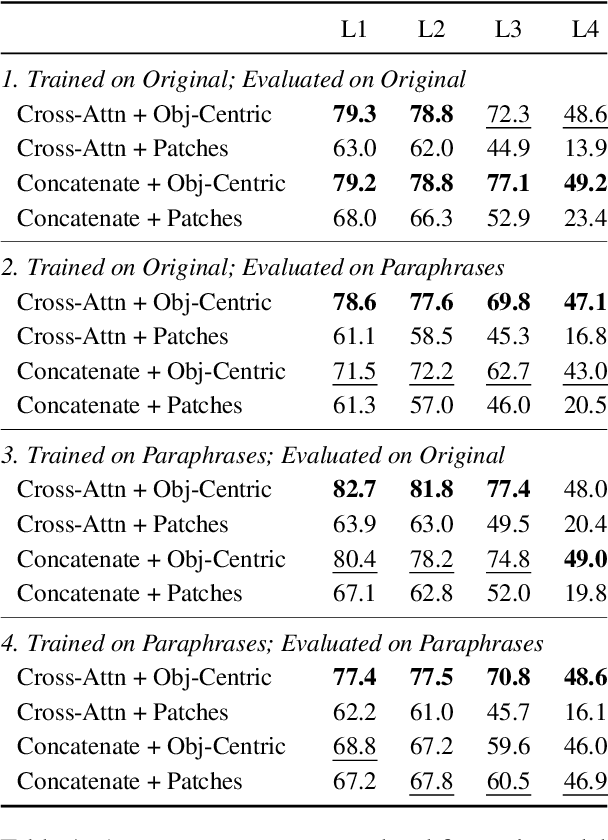
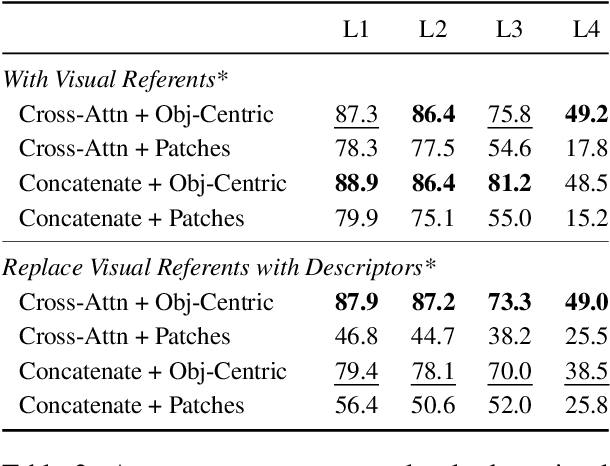

Evaluating the generalisation capabilities of multimodal models based solely on their performance on out-of-distribution data fails to capture their true robustness. This work introduces a comprehensive evaluation framework that systematically examines the role of instructions and inputs in the generalisation abilities of such models, considering architectural design, input perturbations across language and vision modalities, and increased task complexity. The proposed framework uncovers the resilience of multimodal models to extreme instruction perturbations and their vulnerability to observational changes, raising concerns about overfitting to spurious correlations. By employing this evaluation framework on current Transformer-based multimodal models for robotic manipulation tasks, we uncover limitations and suggest future advancements should focus on architectural and training innovations that better integrate multimodal inputs, enhancing a model's generalisation prowess by prioritising sensitivity to input content over incidental correlations.
Enhancing Continual Learning in Visual Question Answering with Modality-Aware Feature Distillation
Jun 27, 2024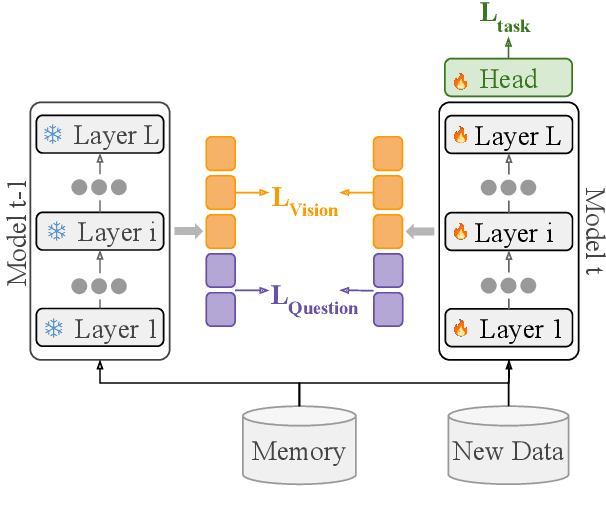
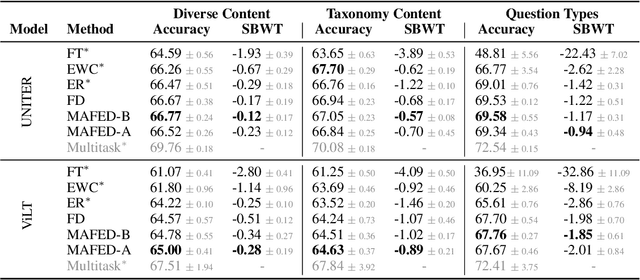
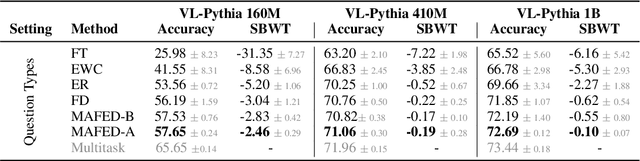
Continual learning focuses on incrementally training a model on a sequence of tasks with the aim of learning new tasks while minimizing performance drop on previous tasks. Existing approaches at the intersection of Continual Learning and Visual Question Answering (VQA) do not study how the multimodal nature of the input affects the learning dynamics of a model. In this paper, we demonstrate that each modality evolves at different rates across a continuum of tasks and that this behavior occurs in established encoder-only models as well as modern recipes for developing Vision & Language (VL) models. Motivated by this observation, we propose a modality-aware feature distillation (MAFED) approach which outperforms existing baselines across models of varying scale in three multimodal continual learning settings. Furthermore, we provide ablations showcasing that modality-aware distillation complements experience replay. Overall, our results emphasize the importance of addressing modality-specific dynamics to prevent forgetting in multimodal continual learning.
AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
Visually Grounded Language Learning: a review of language games, datasets, tasks, and models
Dec 05, 2023
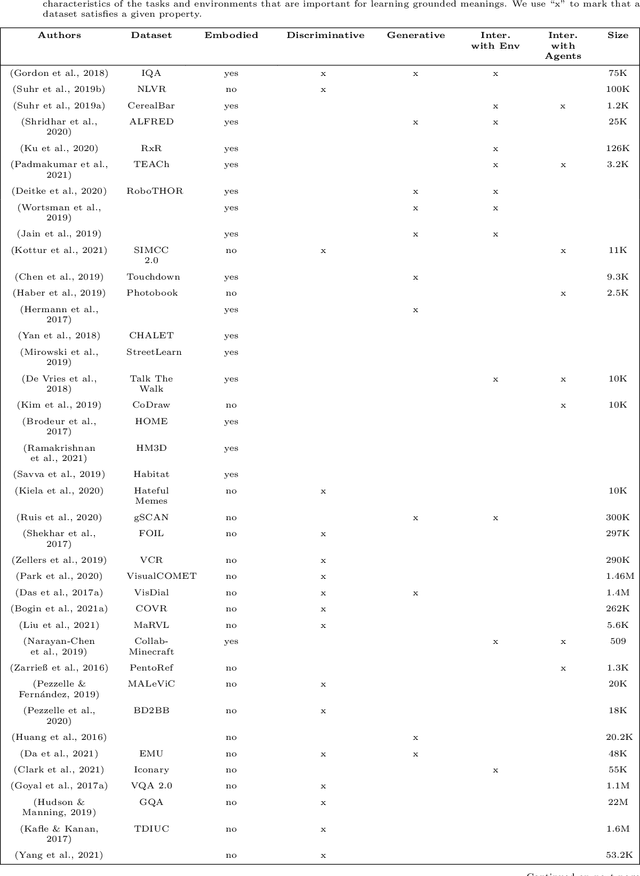
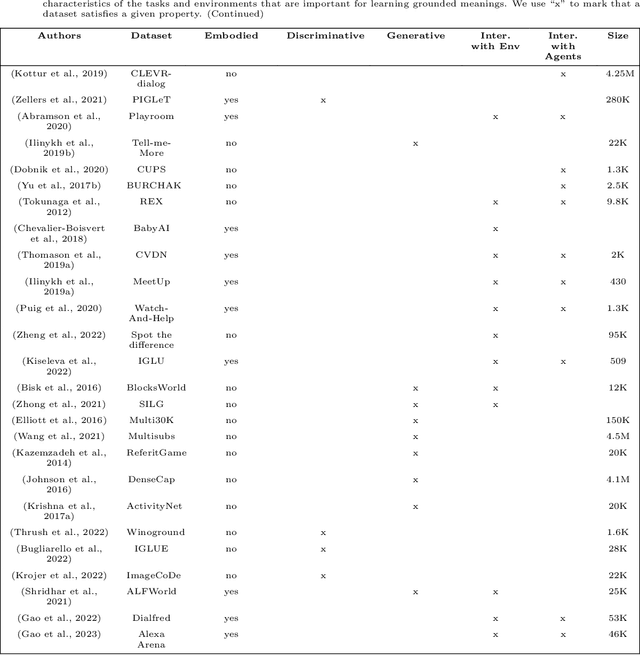
In recent years, several machine learning models have been proposed. They are trained with a language modelling objective on large-scale text-only data. With such pretraining, they can achieve impressive results on many Natural Language Understanding and Generation tasks. However, many facets of meaning cannot be learned by ``listening to the radio" only. In the literature, many Vision+Language (V+L) tasks have been defined with the aim of creating models that can ground symbols in the visual modality. In this work, we provide a systematic literature review of several tasks and models proposed in the V+L field. We rely on Wittgenstein's idea of `language games' to categorise such tasks into 3 different families: 1) discriminative games, 2) generative games, and 3) interactive games. Our analysis of the literature provides evidence that future work should be focusing on interactive games where communication in Natural Language is important to resolve ambiguities about object referents and action plans and that physical embodiment is essential to understand the semantics of situations and events. Overall, these represent key requirements for developing grounded meanings in neural models.
Multitask Multimodal Prompted Training for Interactive Embodied Task Completion
Nov 07, 2023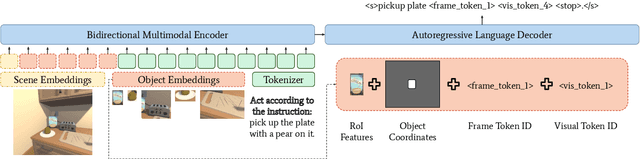
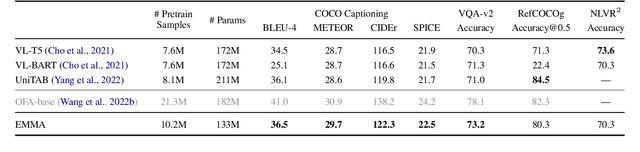
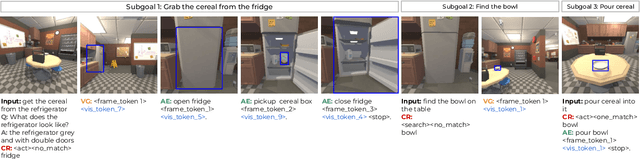
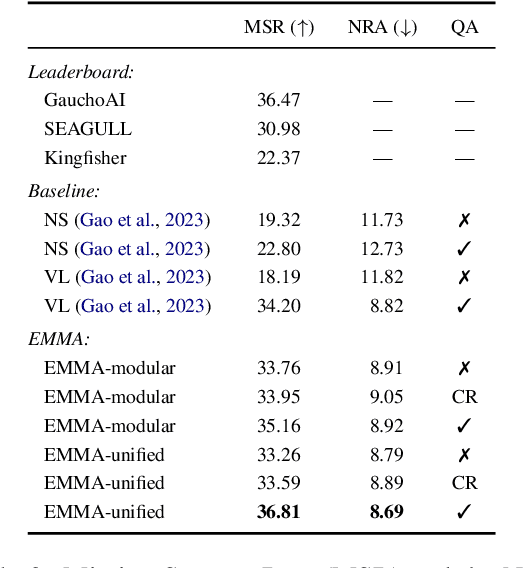
Interactive and embodied tasks pose at least two fundamental challenges to existing Vision & Language (VL) models, including 1) grounding language in trajectories of actions and observations, and 2) referential disambiguation. To tackle these challenges, we propose an Embodied MultiModal Agent (EMMA): a unified encoder-decoder model that reasons over images and trajectories, and casts action prediction as multimodal text generation. By unifying all tasks as text generation, EMMA learns a language of actions which facilitates transfer across tasks. Different to previous modular approaches with independently trained components, we use a single multitask model where each task contributes to goal completion. EMMA performs on par with similar models on several VL benchmarks and sets a new state-of-the-art performance (36.81% success rate) on the Dialog-guided Task Completion (DTC), a benchmark to evaluate dialog-guided agents in the Alexa Arena