 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
Explainable Representations of the Social State: A Model for Social Human-Robot Interactions
Oct 09, 2020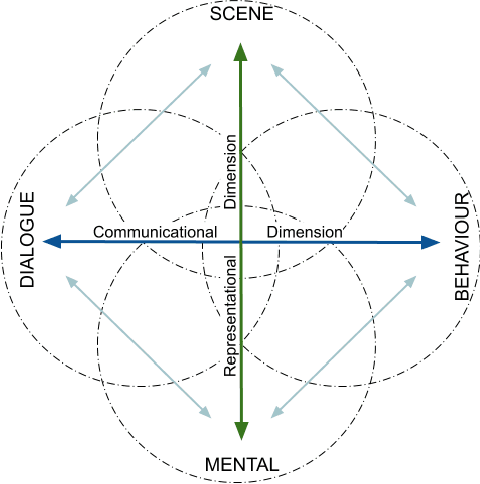
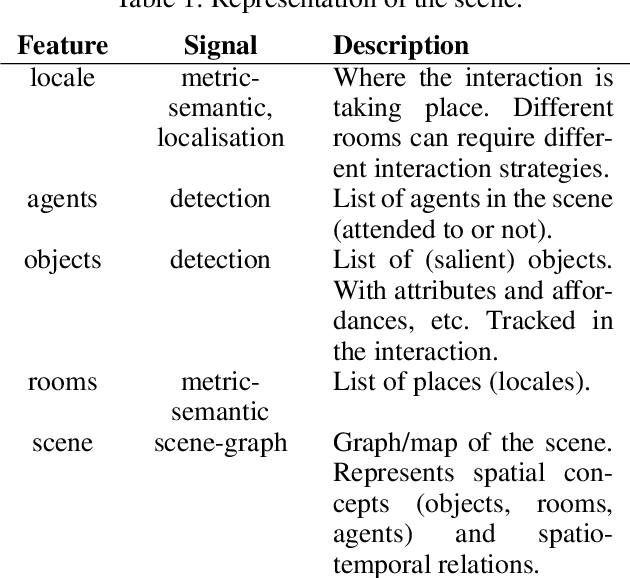


In this paper, we propose a minimum set of concepts and signals needed to track the social state during Human-Robot Interaction. We look into the problem of complex continuous interactions in a social context with multiple humans and robots, and discuss the creation of an explainable and tractable representation/model of their social interaction. We discuss these representations according to their representational and communicational properties, and organize them into four cognitive domains (scene-understanding, behaviour-profiling, mental-state, and dialogue-grounding).
Continual Lifelong Learning with Neural Networks: A Review
Jul 07, 2018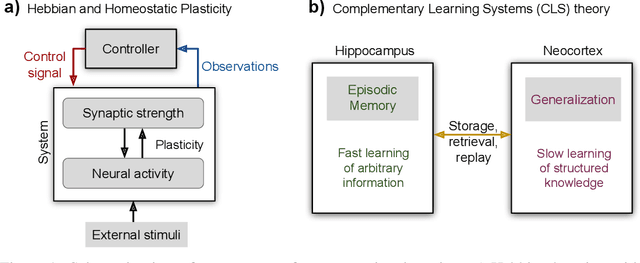
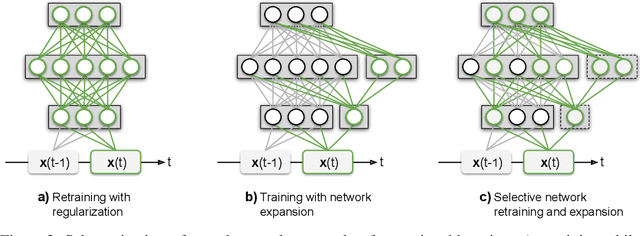

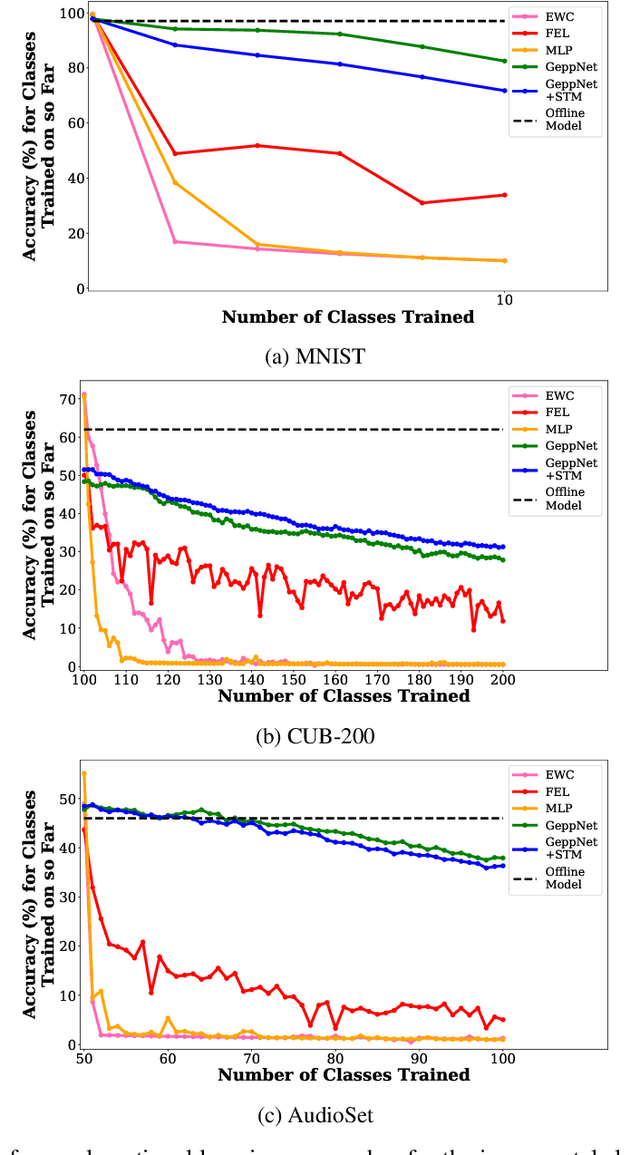
Humans and animals have the ability to continually acquire and fine-tune knowledge throughout their lifespan. This ability, referred to as lifelong learning, is mediated by a rich set of neurocognitive mechanisms that together contribute to the development and specialization of our sensorimotor skills as well as to the long-term memory consolidation and retrieval without catastrophic forgetting. Consequently, lifelong learning capabilities are crucial for computational learning systems and autonomous agents interacting in the real world and processing continuous streams of information. However, lifelong learning remains a long-standing challenge for machine learning and neural network models since the continual acquisition of incrementally available information from non-stationary data distributions generally leads to catastrophic forgetting or interference. This limitation represents a major drawback also for state-of-the-art deep and shallow neural network models that typically learn representations from stationary batches of training data, thus without accounting for situations in which the number of tasks is not known a priori and the information becomes incrementally available over time. In this review, we critically summarize the main challenges linked to lifelong learning for artificial learning systems and compare existing neural network approaches that alleviate, to different extents, catastrophic forgetting. Although significant advances have been made in domain-specific learning with neural networks, extensive research efforts are required for the development of robust lifelong learning on autonomous agents and robots. We discuss well-established and emerging research motivated by lifelong learning factors in biological systems such as neurosynaptic plasticity, multi-task transfer learning, intrinsically motivated exploration, and crossmodal learning.
An Ensemble Model with Ranking for Social Dialogue
Dec 20, 2017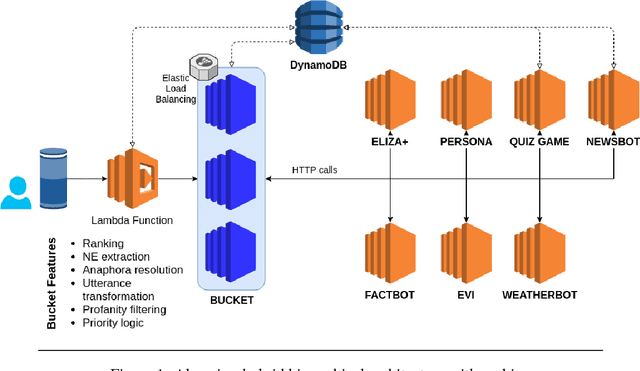

Open-domain social dialogue is one of the long-standing goals of Artificial Intelligence. This year, the Amazon Alexa Prize challenge was announced for the first time, where real customers get to rate systems developed by leading universities worldwide. The aim of the challenge is to converse "coherently and engagingly with humans on popular topics for 20 minutes". We describe our Alexa Prize system (called 'Alana') consisting of an ensemble of bots, combining rule-based and machine learning systems, and using a contextual ranking mechanism to choose a system response. The ranker was trained on real user feedback received during the competition, where we address the problem of how to train on the noisy and sparse feedback obtained during the competition.