 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
Psycholinguistics meets Continual Learning: Measuring Catastrophic Forgetting in Visual Question Answering
Jun 10, 2019

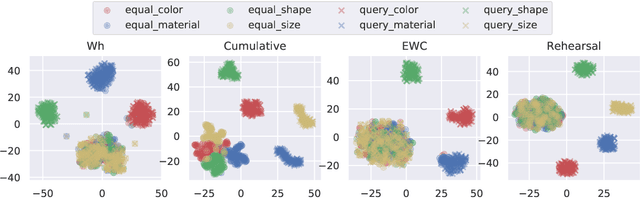
We study the issue of catastrophic forgetting in the context of neural multimodal approaches to Visual Question Answering (VQA). Motivated by evidence from psycholinguistics, we devise a set of linguistically-informed VQA tasks, which differ by the types of questions involved (Wh-questions and polar questions). We test what impact task difficulty has on continual learning, and whether the order in which a child acquires question types facilitates computational models. Our results show that dramatic forgetting is at play and that task difficulty and order matter. Two well-known current continual learning methods mitigate the problem only to a limiting degree.
Grounded Textual Entailment
Jun 14, 2018
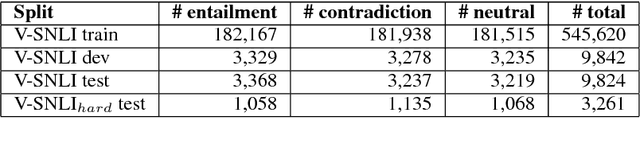

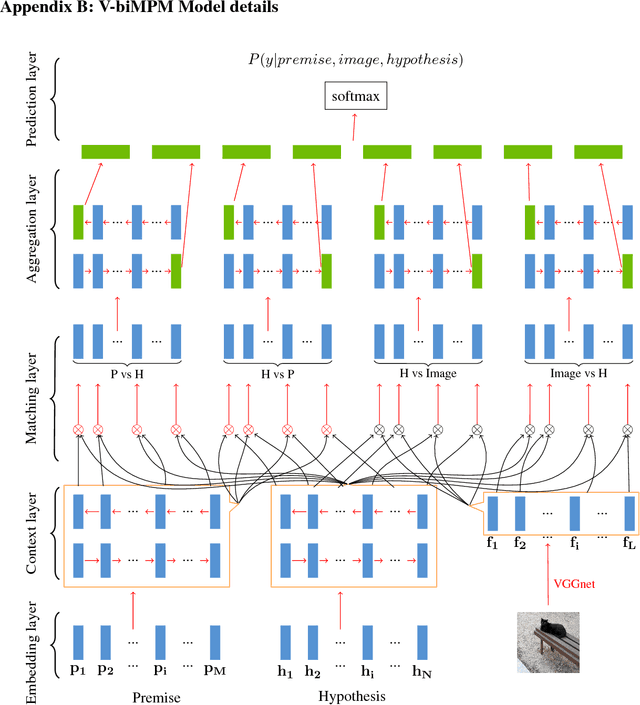
Capturing semantic relations between sentences, such as entailment, is a long-standing challenge for computational semantics. Logic-based models analyse entailment in terms of possible worlds (interpretations, or situations) where a premise P entails a hypothesis H iff in all worlds where P is true, H is also true. Statistical models view this relationship probabilistically, addressing it in terms of whether a human would likely infer H from P. In this paper, we wish to bridge these two perspectives, by arguing for a visually-grounded version of the Textual Entailment task. Specifically, we ask whether models can perform better if, in addition to P and H, there is also an image (corresponding to the relevant "world" or "situation"). We use a multimodal version of the SNLI dataset (Bowman et al., 2015) and we compare "blind" and visually-augmented models of textual entailment. We show that visual information is beneficial, but we also conduct an in-depth error analysis that reveals that current multimodal models are not performing "grounding" in an optimal fashion.
Iterative Multi-document Neural Attention for Multiple Answer Prediction
Feb 08, 2017

People have information needs of varying complexity, which can be solved by an intelligent agent able to answer questions formulated in a proper way, eventually considering user context and preferences. In a scenario in which the user profile can be considered as a question, intelligent agents able to answer questions can be used to find the most relevant answers for a given user. In this work we propose a novel model based on Artificial Neural Networks to answer questions with multiple answers by exploiting multiple facts retrieved from a knowledge base. The model is evaluated on the factoid Question Answering and top-n recommendation tasks of the bAbI Movie Dialog dataset. After assessing the performance of the model on both tasks, we try to define the long-term goal of a conversational recommender system able to interact using natural language and to support users in their information seeking processes in a personalized way.