 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexVLM2Vec: Adapting LVLM-based embedding models to multilinguality using Self-Knowledge Distillation
Mar 12, 2025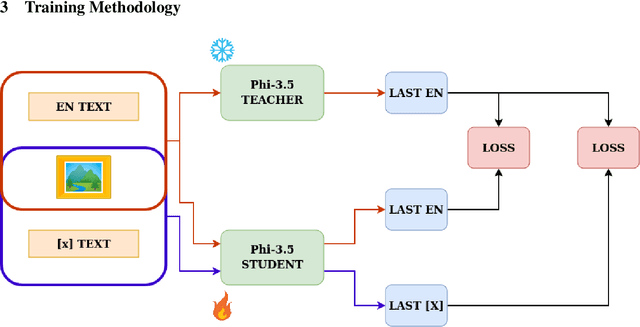
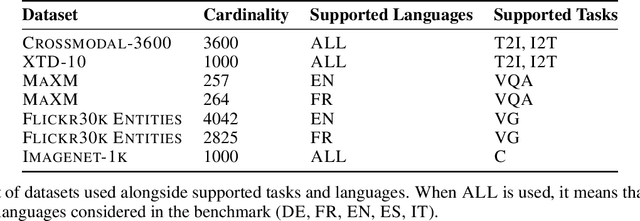
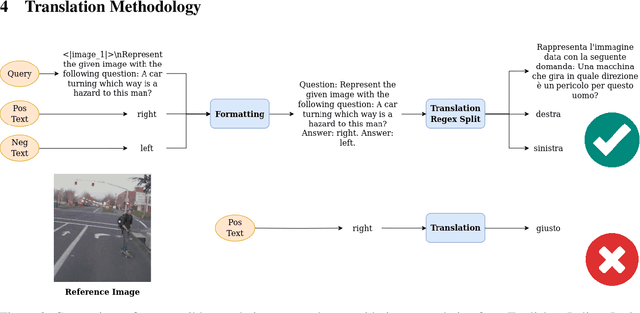
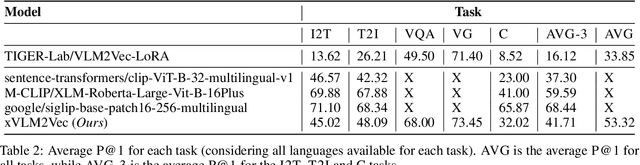
In the current literature, most embedding models are based on the encoder-only transformer architecture to extract a dense and meaningful representation of the given input, which can be a text, an image, and more. With the recent advances in language modeling thanks to the introduction of Large Language Models, the possibility of extracting embeddings from these large and extensively trained models has been explored. However, current studies focus on textual embeddings in English, which is also the main language on which these models have been trained. Furthermore, there are very few models that consider multimodal and multilingual input. In light of this, we propose an adaptation methodology for Large Vision-Language Models trained on English language data to improve their performance in extracting multilingual and multimodal embeddings. Finally, we design and introduce a benchmark to evaluate the effectiveness of multilingual and multimodal embedding models.
Exploring the Word Sense Disambiguation Capabilities of Large Language Models
Mar 11, 2025

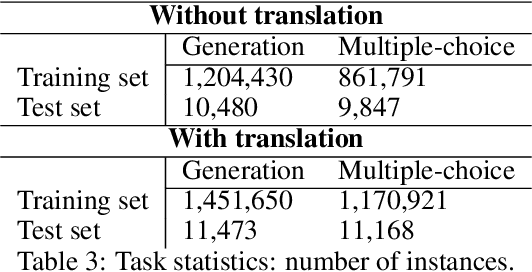
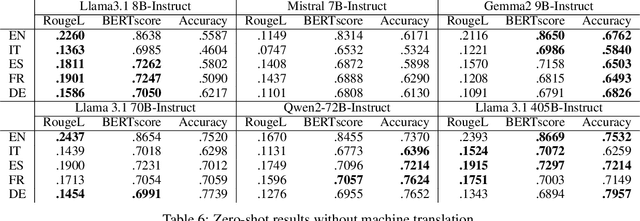
Word Sense Disambiguation (WSD) is a historical task in computational linguistics that has received much attention over the years. However, with the advent of Large Language Models (LLMs), interest in this task (in its classical definition) has decreased. In this study, we evaluate the performance of various LLMs on the WSD task. We extend a previous benchmark (XL-WSD) to re-design two subtasks suitable for LLM: 1) given a word in a sentence, the LLM must generate the correct definition; 2) given a word in a sentence and a set of predefined meanings, the LLM must select the correct one. The extended benchmark is built using the XL-WSD and BabelNet. The results indicate that LLMs perform well in zero-shot learning but cannot surpass current state-of-the-art methods. However, a fine-tuned model with a medium number of parameters outperforms all other models, including the state-of-the-art.
Advanced Natural-based interaction for the ITAlian language: LLaMAntino-3-ANITA
May 11, 2024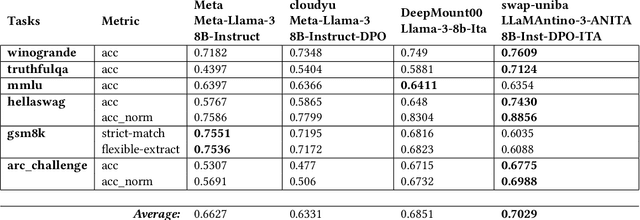

In the pursuit of advancing natural language processing for the Italian language, we introduce a state-of-the-art Large Language Model (LLM) based on the novel Meta LLaMA-3 model: LLaMAntino-3-ANITA-8B-Inst-DPO-ITA. We fine-tuned the original 8B parameters instruction tuned model using the Supervised Fine-tuning (SFT) technique on the English and Italian language datasets in order to improve the original performance. Consequently, a Dynamic Preference Optimization (DPO) process has been used to align preferences, avoid dangerous and inappropriate answers, and limit biases and prejudices. Our model leverages the efficiency of QLoRA to fine-tune the model on a smaller portion of the original model weights and then adapt the model specifically for the Italian linguistic structure, achieving significant improvements in both performance and computational efficiency. Concurrently, DPO is employed to refine the model's output, ensuring that generated content aligns with quality answers. The synergy between SFT, QLoRA's parameter efficiency and DPO's user-centric optimization results in a robust LLM that excels in a variety of tasks, including but not limited to text completion, zero-shot classification, and contextual understanding. The model has been extensively evaluated over standard benchmarks for the Italian and English languages, showing outstanding results. The model is freely available over the HuggingFace hub and, examples of use can be found in our GitHub repository. https://huggingface.co/swap-uniba/LLaMAntino-3-ANITA-8B-Inst-DPO-ITA
LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language
Dec 15, 2023


Large Language Models represent state-of-the-art linguistic models designed to equip computers with the ability to comprehend natural language. With its exceptional capacity to capture complex contextual relationships, the LLaMA (Large Language Model Meta AI) family represents a novel advancement in the field of natural language processing by releasing foundational models designed to improve the natural language understanding abilities of the transformer architecture thanks to their large amount of trainable parameters (7, 13, and 70 billion parameters). In many natural language understanding tasks, these models obtain the same performances as private company models such as OpenAI Chat-GPT with the advantage to make publicly available weights and code for research and commercial uses. In this work, we investigate the possibility of Language Adaptation for LLaMA models, explicitly focusing on addressing the challenge of Italian Language coverage. Adopting an open science approach, we explore various tuning approaches to ensure a high-quality text generated in Italian suitable for common tasks in this underrepresented language in the original models' datasets. We aim to release effective text generation models with strong linguistic properties for many tasks that seem challenging using multilingual or general-purpose LLMs. By leveraging an open science philosophy, this study contributes to Language Adaptation strategies for the Italian language by introducing the novel LLaMAntino family of Italian LLMs.
DUKweb: Diachronic word representations from the UK Web Archive corpus
Jul 02, 2021



Lexical semantic change (detecting shifts in the meaning and usage of words) is an important task for social and cultural studies as well as for Natural Language Processing applications. Diachronic word embeddings (time-sensitive vector representations of words that preserve their meaning) have become the standard resource for this task. However, given the significant computational resources needed for their generation, very few resources exist that make diachronic word embeddings available to the scientific community. In this paper we present DUKweb, a set of large-scale resources designed for the diachronic analysis of contemporary English. DUKweb was created from the JISC UK Web Domain Dataset (1996-2013), a very large archive which collects resources from the Internet Archive that were hosted on domains ending in `.uk'. DUKweb consists of a series word co-occurrence matrices and two types of word embeddings for each year in the JISC UK Web Domain dataset. We show the reuse potential of DUKweb and its quality standards via a case study on word meaning change detection.
GM-CTSC at SemEval-2020 Task 1: Gaussian Mixtures Cross Temporal Similarity Clustering
May 20, 2020


This paper describes the system proposed for the SemEval-2020 Task 1: Unsupervised Lexical Semantic Change Detection. We focused our approach on the detection problem. Given the semantics of words captured by temporal word embeddings in different time periods, we investigate the use of unsupervised methods to detect when the target word has gained or loosed senses. To this end, we defined a new algorithm based on Gaussian Mixture Models to cluster the target similarities computed over the two periods. We compared the proposed approach with a number of similarity-based thresholds. We found that, although the performance of the detection methods varies across the word embedding algorithms, the combination of Gaussian Mixture with Temporal Referencing resulted in our best system.
Iterative Multi-document Neural Attention for Multiple Answer Prediction
Feb 08, 2017

People have information needs of varying complexity, which can be solved by an intelligent agent able to answer questions formulated in a proper way, eventually considering user context and preferences. In a scenario in which the user profile can be considered as a question, intelligent agents able to answer questions can be used to find the most relevant answers for a given user. In this work we propose a novel model based on Artificial Neural Networks to answer questions with multiple answers by exploiting multiple facts retrieved from a knowledge base. The model is evaluated on the factoid Question Answering and top-n recommendation tasks of the bAbI Movie Dialog dataset. After assessing the performance of the model on both tasks, we try to define the long-term goal of a conversational recommender system able to interact using natural language and to support users in their information seeking processes in a personalized way.