 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Composed Image Retrieval Benchmarks Require Multimodal Composition?
May 14, 2026Composed Image Retrieval (CIR) is a multimodal retrieval task where a query consists of a reference image and a textual modification, and the goal is to retrieve a target image satisfying both. In principle, strong performance on CIR benchmarks is assumed to require multimodal composition, i.e., combining complementary information from reference image and textual modification. In this work, we show that this assumption does not always hold. Across four widely used CIR benchmarks and eleven Generalist Multimodal Embedding models, a large fraction of queries can be solved using a single modality (from 32.2% to 83.6%), revealing pervasive unimodal shortcuts. Thus, high CIR performance can arise from unimodal signals rather than true multimodal composition. To better understand this issue, we perform a two-stage audit. First, we identify shortcut-solvable queries through cross-model analysis. Second, we conduct human validation on 4,741 shortcut-free queries, of which only 1,689 are well-formed, with common issues including ambiguous edits and mismatched targets. Re-evaluating models on this validated subset reveals qualitatively different behaviour: queries can no longer be solved with a single modality, and successful retrieval requires combining both inputs. While accuracy decreases, reliance on multimodal information increases. Overall, current CIR benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries, leading to an overestimation of model capability in multimodal composition.
MIXAR: Scaling Autoregressive Pixel-based Language Models to Multiple Languages and Scripts
Apr 13, 2026Pixel-based language models are gaining momentum as alternatives to traditional token-based approaches, promising to circumvent tokenization challenges. However, the inherent perceptual diversity across languages poses a significant hurdle for multilingual generalization in pixel space. This paper introduces MIXAR, the first generative pixel-based language model trained on eight different languages utilizing a range of different scripts. We empirically evaluate MIXAR against previous pixel-based models as well as comparable tokenizer-based models, demonstrating substantial performance improvement on discriminative and generative multilingual tasks. Additionally, we show how MIXAR is robust to languages never seen during the training. These results are further strengthened when scaling the model to 0.5B parameters which not only improves its capabilities in generative tasks like LAMBADA but also its robustness when challenged with input perturbations such as orthographic attacks.
AgriPath: A Systematic Exploration of Architectural Trade-offs for Crop Disease Classification
Mar 17, 2026Reliable crop disease detection requires models that perform consistently across diverse acquisition conditions, yet existing evaluations often focus on single architectural families or lab-generated datasets. This work presents a systematic empirical comparison of three model paradigms for fine-grained crop disease classification: Convolutional Neural Networks (CNNs), contrastive Vision-Language Models (VLMs), and generative VLMs. To enable controlled analysis of domain effects, we introduce AgriPath-LF16, a benchmark containing 111k images spanning 16 crops and 41 diseases with explicit separation between laboratory and field imagery, alongside a balanced 30k subset for standardized training and evaluation. All models are trained and evaluated under unified protocols across full, lab-only, and field-only training regimes using macro-F1 and Parse Success Rate (PSR) to account for generative reliability. The results reveal distinct performance profiles. CNNs achieve the highest accuracy on lab imagery but degrade under domain shift. Contrastive VLMs provide a robust and parameter-efficient alternative with competitive cross-domain performance. Generative VLMs demonstrate the strongest resilience to distributional variation, albeit with additional failure modes stemming from free-text generation. These findings highlight that architectural choice should be guided by deployment context rather than aggregate accuracy alone.
Retrievit: In-context Retrieval Capabilities of Transformers, State Space Models, and Hybrid Architectures
Mar 03, 2026Transformers excel at in-context retrieval but suffer from quadratic complexity with sequence length, while State Space Models (SSMs) offer efficient linear-time processing but have limited retrieval capabilities. We investigate whether hybrid architectures combining Transformers and SSMs can achieve the best of both worlds on two synthetic in-context retrieval tasks. The first task, n-gram retrieval, requires the model to identify and reproduce an n-gram that succeeds the query within the input sequence. The second task, position retrieval, presents the model with a single query token and requires it to perform a two-hop associative lookup: first locating the corresponding element in the sequence, and then outputting its positional index. Under controlled experimental conditions, we assess data efficiency, length generalization, robustness to out of domain training examples, and learned representations across Transformers, SSMs, and hybrid architectures. We find that hybrid models outperform SSMs and match or exceed Transformers in data efficiency and extrapolation for information-dense context retrieval. However, Transformers maintain superiority in position retrieval tasks. Through representation analysis, we discover that SSM-based models develop locality-aware embeddings where tokens representing adjacent positions become neighbors in embedding space, forming interpretable structures. This emergent property, absent in Transformers, explains both the strengths and limitations of SSMs and hybrids for different retrieval tasks. Our findings provide principled guidance for architecture selection based on task requirements and reveal fundamental differences in how Transformers and SSMs, and hybrid models learn positional associations.
Same Answer, Different Representations: Hidden instability in VLMs
Feb 06, 2026The robustness of Vision Language Models (VLMs) is commonly assessed through output-level invariance, implicitly assuming that stable predictions reflect stable multimodal processing. In this work, we argue that this assumption is insufficient. We introduce a representation-aware and frequency-aware evaluation framework that measures internal embedding drift, spectral sensitivity, and structural smoothness (spatial consistency of vision tokens), alongside standard label-based metrics. Applying this framework to modern VLMs across the SEEDBench, MMMU, and POPE datasets reveals three distinct failure modes. First, models frequently preserve predicted answers while undergoing substantial internal representation drift; for perturbations such as text overlays, this drift approaches the magnitude of inter-image variability, indicating that representations move to regions typically occupied by unrelated inputs despite unchanged outputs. Second, robustness does not improve with scale; larger models achieve higher accuracy but exhibit equal or greater sensitivity, consistent with sharper yet more fragile decision boundaries. Third, we find that perturbations affect tasks differently: they harm reasoning when they disrupt how models combine coarse and fine visual cues, but on the hallucination benchmarks, they can reduce false positives by making models generate more conservative answers.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
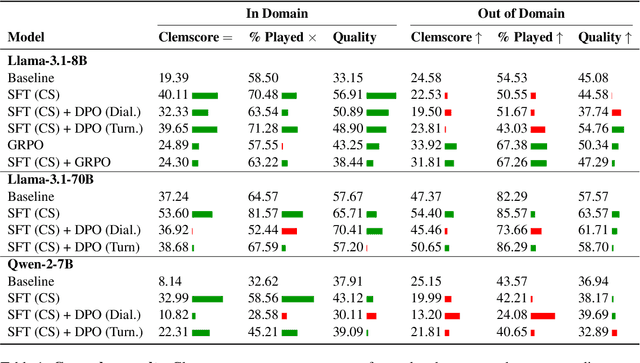


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
Triangulating LLM Progress through Benchmarks, Games, and Cognitive Tests
Feb 20, 2025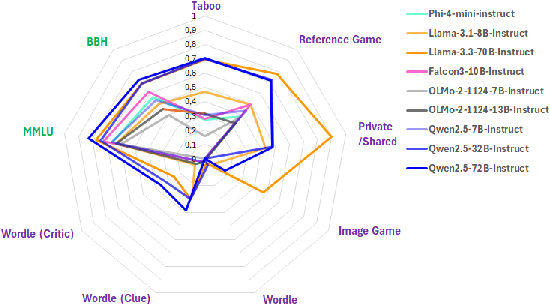
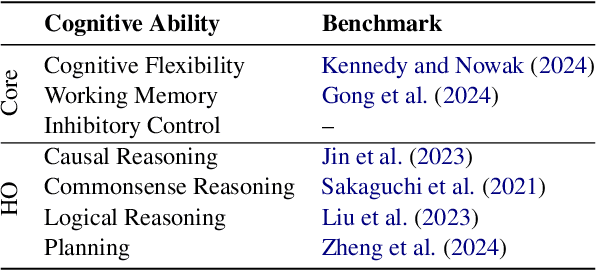
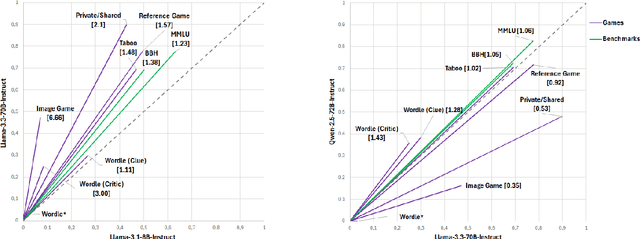
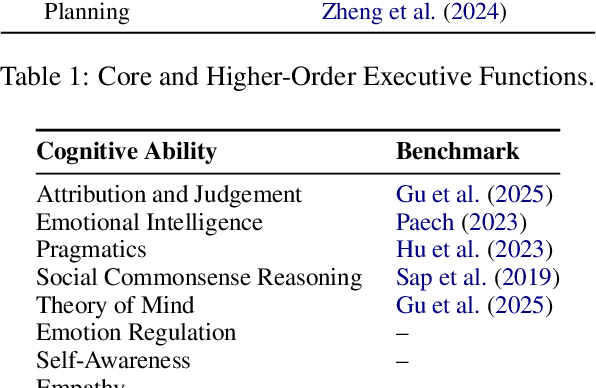
We examine three evaluation paradigms: large question-answering benchmarks (e.g., MMLU and BBH), interactive games (e.g., Signalling Games or Taboo), and cognitive tests (e.g., for working memory or theory of mind). First, we investigate which of the former two-benchmarks or games-is most effective at discriminating LLMs of varying quality. Then, inspired by human cognitive assessments, we compile a suite of targeted tests that measure cognitive abilities deemed essential for effective language use, and we investigate their correlation with model performance in benchmarks and games. Our analyses reveal that interactive games are superior to standard benchmarks in discriminating models. Causal and logical reasoning correlate with both static and interactive tests, while differences emerge regarding core executive functions and social/emotional skills, which correlate more with games. We advocate the development of new interactive benchmarks and targeted cognitive tasks inspired by assessing human abilities but designed specifically for LLMs.
CROPE: Evaluating In-Context Adaptation of Vision and Language Models to Culture-Specific Concepts
Oct 20, 2024As Vision and Language models (VLMs) become accessible across the globe, it is important that they demonstrate cultural knowledge. In this paper, we introduce CROPE, a visual question answering benchmark designed to probe the knowledge of culture-specific concepts and evaluate the capacity for cultural adaptation through contextual information. This allows us to distinguish between parametric knowledge acquired during training and contextual knowledge provided during inference via visual and textual descriptions. Our evaluation of several state-of-the-art open VLMs shows large performance disparities between culture-specific and common concepts in the parametric setting. Moreover, experiments with contextual knowledge indicate that models struggle to effectively utilize multimodal information and bind culture-specific concepts to their depictions. Our findings reveal limitations in the cultural understanding and adaptability of current VLMs that need to be addressed toward more culturally inclusive models.
Repairs in a Block World: A New Benchmark for Handling User Corrections with Multi-Modal Language Models
Sep 21, 2024In dialogue, the addressee may initially misunderstand the speaker and respond erroneously, often prompting the speaker to correct the misunderstanding in the next turn with a Third Position Repair (TPR). The ability to process and respond appropriately to such repair sequences is thus crucial in conversational AI systems. In this paper, we first collect, analyse, and publicly release BlockWorld-Repairs: a dataset of multi-modal TPR sequences in an instruction-following manipulation task that is, by design, rife with referential ambiguity. We employ this dataset to evaluate several state-of-the-art Vision and Language Models (VLM) across multiple settings, focusing on their capability to process and accurately respond to TPRs and thus recover from miscommunication. We find that, compared to humans, all models significantly underperform in this task. We then show that VLMs can benefit from specialised losses targeting relevant tokens during fine-tuning, achieving better performance and generisability. Our results suggest that these models are not yet ready to be deployed in multi-modal collaborative settings where repairs are common, and highlight the need to design training regimes and objectives that facilitate learning from interaction.