 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning or a Semblance of it? A Diagnostic Study of Transitive Reasoning in LLMs
Oct 26, 2024



Evaluating Large Language Models (LLMs) on reasoning benchmarks demonstrates their ability to solve compositional questions. However, little is known of whether these models engage in genuine logical reasoning or simply rely on implicit cues to generate answers. In this paper, we investigate the transitive reasoning capabilities of two distinct LLM architectures, LLaMA 2 and Flan-T5, by manipulating facts within two compositional datasets: QASC and Bamboogle. We controlled for potential cues that might influence the models' performance, including (a) word/phrase overlaps across sections of test input; (b) models' inherent knowledge during pre-training or fine-tuning; and (c) Named Entities. Our findings reveal that while both models leverage (a), Flan-T5 shows more resilience to experiments (b and c), having less variance than LLaMA 2. This suggests that models may develop an understanding of transitivity through fine-tuning on knowingly relevant datasets, a hypothesis we leave to future work.
Repairs in a Block World: A New Benchmark for Handling User Corrections with Multi-Modal Language Models
Sep 21, 2024In dialogue, the addressee may initially misunderstand the speaker and respond erroneously, often prompting the speaker to correct the misunderstanding in the next turn with a Third Position Repair (TPR). The ability to process and respond appropriately to such repair sequences is thus crucial in conversational AI systems. In this paper, we first collect, analyse, and publicly release BlockWorld-Repairs: a dataset of multi-modal TPR sequences in an instruction-following manipulation task that is, by design, rife with referential ambiguity. We employ this dataset to evaluate several state-of-the-art Vision and Language Models (VLM) across multiple settings, focusing on their capability to process and accurately respond to TPRs and thus recover from miscommunication. We find that, compared to humans, all models significantly underperform in this task. We then show that VLMs can benefit from specialised losses targeting relevant tokens during fine-tuning, achieving better performance and generisability. Our results suggest that these models are not yet ready to be deployed in multi-modal collaborative settings where repairs are common, and highlight the need to design training regimes and objectives that facilitate learning from interaction.
Shaking Up VLMs: Comparing Transformers and Structured State Space Models for Vision & Language Modeling
Sep 09, 2024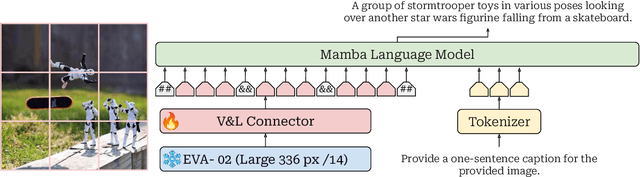
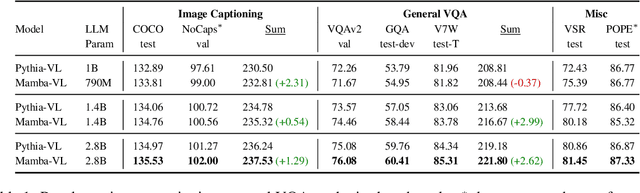
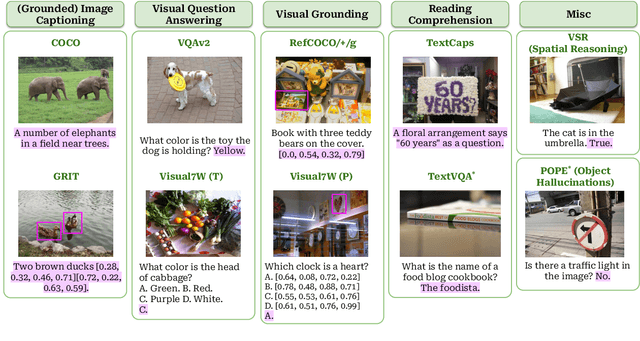
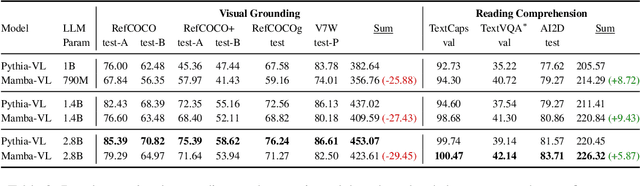
This study explores replacing Transformers in Visual Language Models (VLMs) with Mamba, a recent structured state space model (SSM) that demonstrates promising performance in sequence modeling. We test models up to 3B parameters under controlled conditions, showing that Mamba-based VLMs outperforms Transformers-based VLMs in captioning, question answering, and reading comprehension. However, we find that Transformers achieve greater performance in visual grounding and the performance gap widens with scale. We explore two hypotheses to explain this phenomenon: 1) the effect of task-agnostic visual encoding on the updates of the hidden states, and 2) the difficulty in performing visual grounding from the perspective of in-context multimodal retrieval. Our results indicate that a task-aware encoding yields minimal performance gains on grounding, however, Transformers significantly outperform Mamba at in-context multimodal retrieval. Overall, Mamba shows promising performance on tasks where the correct output relies on a summary of the image but struggles when retrieval of explicit information from the context is required.
AlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
Lost in Space: Probing Fine-grained Spatial Understanding in Vision and Language Resamplers
Apr 21, 2024An effective method for combining frozen large language models (LLM) and visual encoders involves a resampler module that creates a `visual prompt' which is provided to the LLM, along with the textual prompt. While this approach has enabled impressive performance across many coarse-grained tasks like image captioning and visual question answering, more fine-grained tasks that require spatial understanding have not been thoroughly examined. In this paper, we use \textit{diagnostic classifiers} to measure the extent to which the visual prompt produced by the resampler encodes spatial information. Our results show that this information is largely absent from the resampler output when kept frozen during training of the classifiers. However, when the resampler and classifier are trained jointly, we observe a significant performance boost. This shows that the compression achieved by the resamplers can in principle encode the requisite spatial information, but that more object-aware objectives are needed at the pretraining stage to facilitate this capability
Multitask Multimodal Prompted Training for Interactive Embodied Task Completion
Nov 07, 2023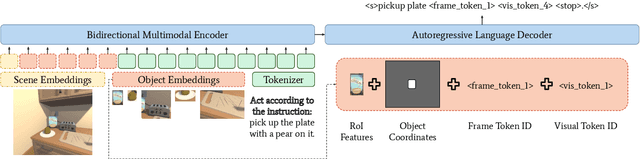
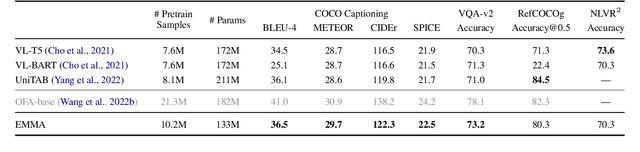
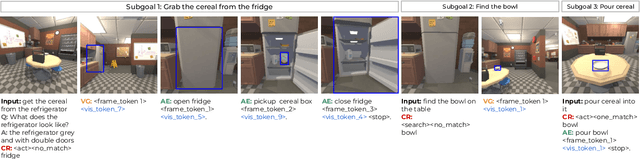
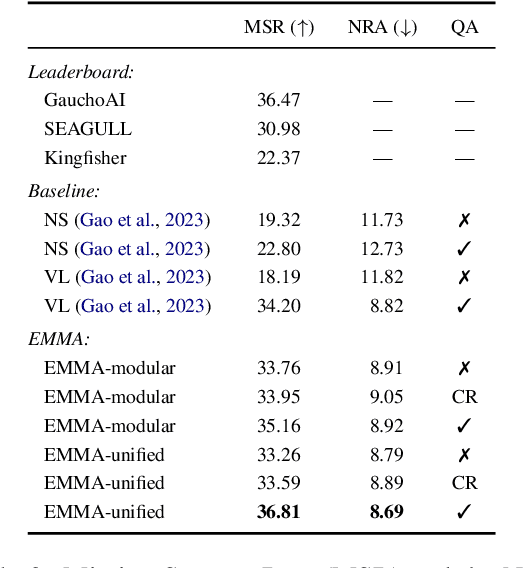
Interactive and embodied tasks pose at least two fundamental challenges to existing Vision & Language (VL) models, including 1) grounding language in trajectories of actions and observations, and 2) referential disambiguation. To tackle these challenges, we propose an Embodied MultiModal Agent (EMMA): a unified encoder-decoder model that reasons over images and trajectories, and casts action prediction as multimodal text generation. By unifying all tasks as text generation, EMMA learns a language of actions which facilitates transfer across tasks. Different to previous modular approaches with independently trained components, we use a single multitask model where each task contributes to goal completion. EMMA performs on par with similar models on several VL benchmarks and sets a new state-of-the-art performance (36.81% success rate) on the Dialog-guided Task Completion (DTC), a benchmark to evaluate dialog-guided agents in the Alexa Arena
Learning to generate and corr- uh I mean repair language in real-time
Aug 22, 2023In conversation, speakers produce language incrementally, word by word, while continuously monitoring the appropriateness of their own contribution in the dynamically unfolding context of the conversation; and this often leads them to repair their own utterance on the fly. This real-time language processing capacity is furthermore crucial to the development of fluent and natural conversational AI. In this paper, we use a previously learned Dynamic Syntax grammar and the CHILDES corpus to develop, train and evaluate a probabilistic model for incremental generation where input to the model is a purely semantic generation goal concept in Type Theory with Records (TTR). We show that the model's output exactly matches the gold candidate in 78% of cases with a ROUGE-l score of 0.86. We further do a zero-shot evaluation of the ability of the same model to generate self-repairs when the generation goal changes mid-utterance. Automatic evaluation shows that the model can generate self-repairs correctly in 85% of cases. A small human evaluation confirms the naturalness and grammaticality of the generated self-repairs. Overall, these results further highlight the generalisation power of grammar-based models and lay the foundations for more controllable, and naturally interactive conversational AI systems.
No that's not what I meant: Handling Third Position Repair in Conversational Question Answering
Jul 31, 2023


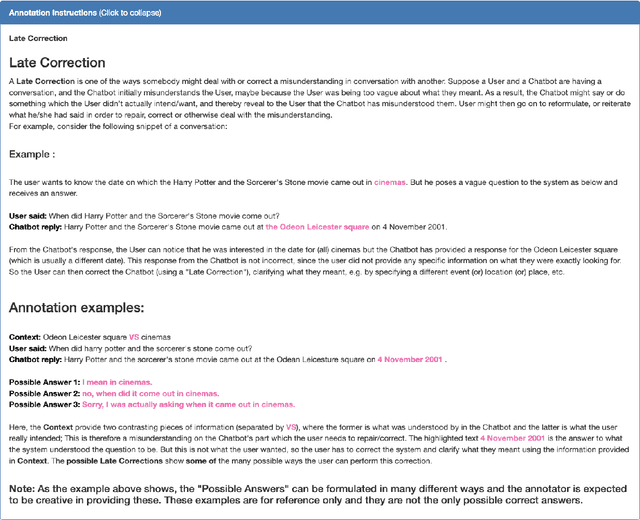
The ability to handle miscommunication is crucial to robust and faithful conversational AI. People usually deal with miscommunication immediately as they detect it, using highly systematic interactional mechanisms called repair. One important type of repair is Third Position Repair (TPR) whereby a speaker is initially misunderstood but then corrects the misunderstanding as it becomes apparent after the addressee's erroneous response. Here, we collect and publicly release Repair-QA, the first large dataset of TPRs in a conversational question answering (QA) setting. The data is comprised of the TPR turns, corresponding dialogue contexts, and candidate repairs of the original turn for execution of TPRs. We demonstrate the usefulness of the data by training and evaluating strong baseline models for executing TPRs. For stand-alone TPR execution, we perform both automatic and human evaluations on a fine-tuned T5 model, as well as OpenAI's GPT-3 LLMs. Additionally, we extrinsically evaluate the LLMs' TPR processing capabilities in the downstream conversational QA task. The results indicate poor out-of-the-box performance on TPR's by the GPT-3 models, which then significantly improves when exposed to Repair-QA.
'What are you referring to?' Evaluating the Ability of Multi-Modal Dialogue Models to Process Clarificational Exchanges
Jul 28, 2023Referential ambiguities arise in dialogue when a referring expression does not uniquely identify the intended referent for the addressee. Addressees usually detect such ambiguities immediately and work with the speaker to repair it using meta-communicative, Clarificational Exchanges (CE): a Clarification Request (CR) and a response. Here, we argue that the ability to generate and respond to CRs imposes specific constraints on the architecture and objective functions of multi-modal, visually grounded dialogue models. We use the SIMMC 2.0 dataset to evaluate the ability of different state-of-the-art model architectures to process CEs, with a metric that probes the contextual updates that arise from them in the model. We find that language-based models are able to encode simple multi-modal semantic information and process some CEs, excelling with those related to the dialogue history, whilst multi-modal models can use additional learning objectives to obtain disentangled object representations, which become crucial to handle complex referential ambiguities across modalities overall.
The Dangers of trusting Stochastic Parrots: Faithfulness and Trust in Open-domain Conversational Question Answering
May 25, 2023



Large language models are known to produce output which sounds fluent and convincing, but is also often wrong, e.g. "unfaithful" with respect to a rationale as retrieved from a knowledge base. In this paper, we show that task-based systems which exhibit certain advanced linguistic dialog behaviors, such as lexical alignment (repeating what the user said), are in fact preferred and trusted more, whereas other phenomena, such as pronouns and ellipsis are dis-preferred. We use open-domain question answering systems as our test-bed for task based dialog generation and compare several open- and closed-book models. Our results highlight the danger of systems that appear to be trustworthy by parroting user input while providing an unfaithful response.