 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning or a Semblance of it? A Diagnostic Study of Transitive Reasoning in LLMs
Oct 26, 2024



Evaluating Large Language Models (LLMs) on reasoning benchmarks demonstrates their ability to solve compositional questions. However, little is known of whether these models engage in genuine logical reasoning or simply rely on implicit cues to generate answers. In this paper, we investigate the transitive reasoning capabilities of two distinct LLM architectures, LLaMA 2 and Flan-T5, by manipulating facts within two compositional datasets: QASC and Bamboogle. We controlled for potential cues that might influence the models' performance, including (a) word/phrase overlaps across sections of test input; (b) models' inherent knowledge during pre-training or fine-tuning; and (c) Named Entities. Our findings reveal that while both models leverage (a), Flan-T5 shows more resilience to experiments (b and c), having less variance than LLaMA 2. This suggests that models may develop an understanding of transitivity through fine-tuning on knowingly relevant datasets, a hypothesis we leave to future work.
On the Importance of Data Size in Probing Fine-tuned Models
Mar 17, 2022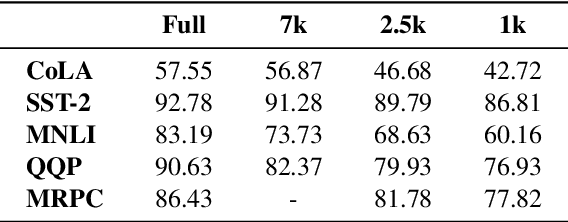
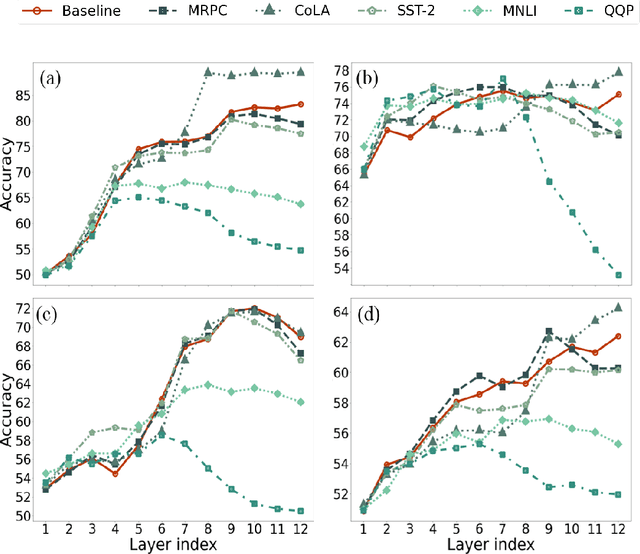
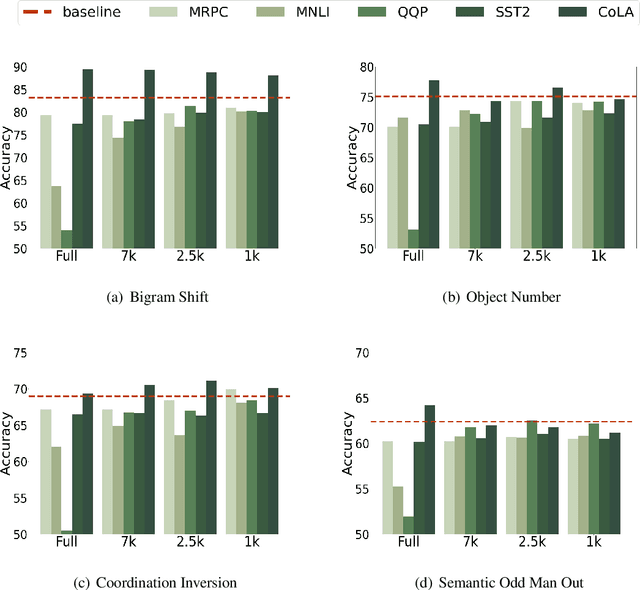
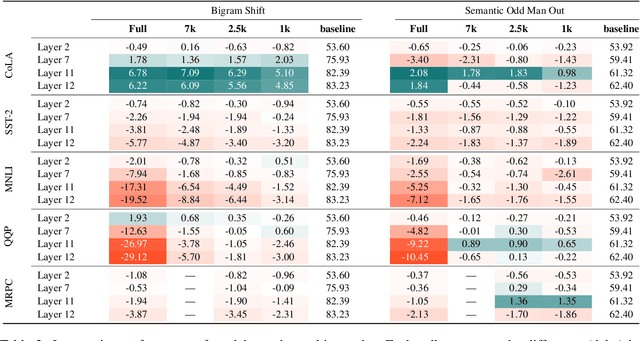
Several studies have investigated the reasons behind the effectiveness of fine-tuning, usually through the lens of probing. However, these studies often neglect the role of the size of the dataset on which the model is fine-tuned. In this paper, we highlight the importance of this factor and its undeniable role in probing performance. We show that the extent of encoded linguistic knowledge depends on the number of fine-tuning samples. The analysis also reveals that larger training data mainly affects higher layers, and that the extent of this change is a factor of the number of iterations updating the model during fine-tuning rather than the diversity of the training samples. Finally, we show through a set of experiments that fine-tuning data size affects the recoverability of the changes made to the model's linguistic knowledge.