 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Data Size in Probing Fine-tuned Models
Paper and Code
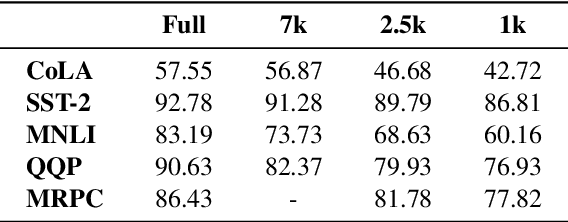
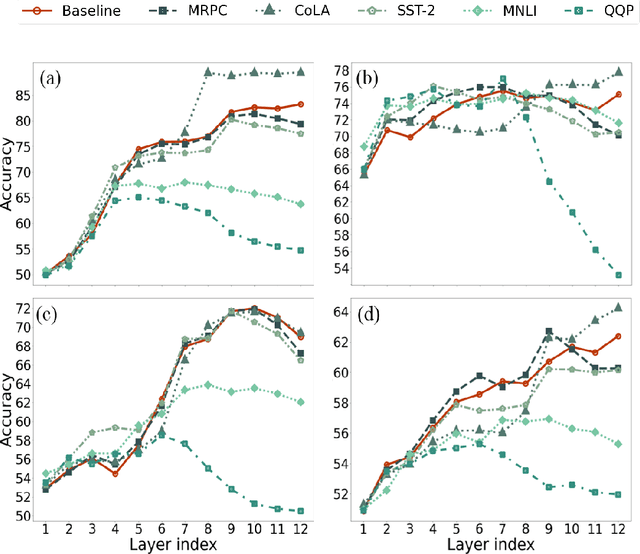
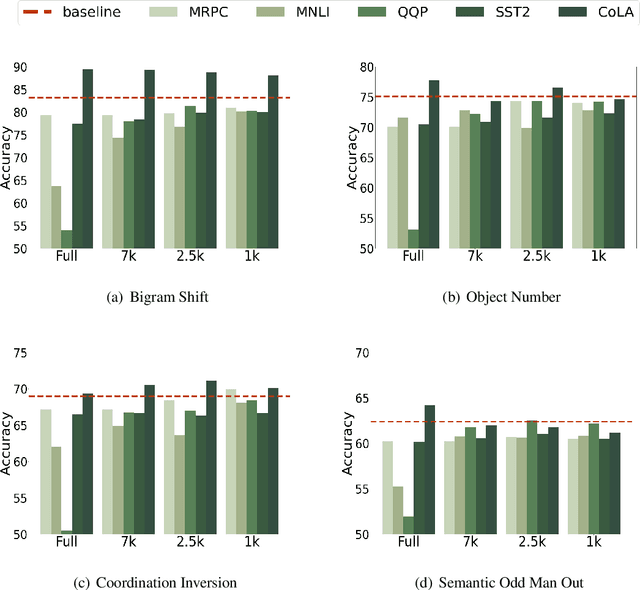
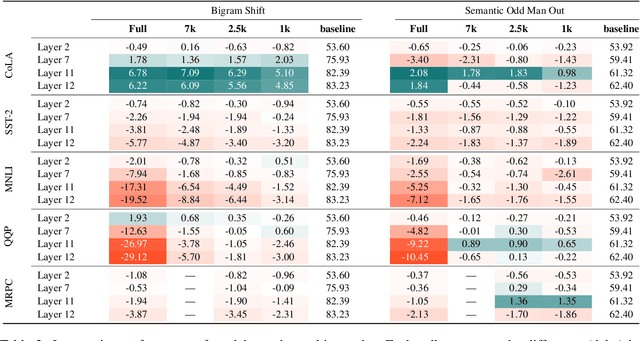
Several studies have investigated the reasons behind the effectiveness of fine-tuning, usually through the lens of probing. However, these studies often neglect the role of the size of the dataset on which the model is fine-tuned. In this paper, we highlight the importance of this factor and its undeniable role in probing performance. We show that the extent of encoded linguistic knowledge depends on the number of fine-tuning samples. The analysis also reveals that larger training data mainly affects higher layers, and that the extent of this change is a factor of the number of iterations updating the model during fine-tuning rather than the diversity of the training samples. Finally, we show through a set of experiments that fine-tuning data size affects the recoverability of the changes made to the model's linguistic knowledge.