 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Performance Degradation in Multi-Instance Processing: The Roles of Instance Count and Context Length
Mar 23, 2026Users often rely on Large Language Models (LLMs) for processing multiple documents or performing analysis over a number of instances. For example, analysing the overall sentiment of a number of movie reviews requires an LLM to process the sentiment of each review individually in order to provide a final aggregated answer. While LLM performance on such individual tasks is generally high, there has been little research on how LLMs perform when dealing with multi-instance inputs. In this paper, we perform a comprehensive evaluation of the multi-instance processing (MIP) ability of LLMs for tasks in which they excel individually. The results show that all LLMs follow a pattern of slight performance degradation for small numbers of instances (approximately 20-100), followed by a performance collapse on larger instance counts. Crucially, our analysis shows that while context length is associated with this degradation, the number of instances has a stronger effect on the final results. This finding suggests that when optimising LLM performance for MIP, attention should be paid to both context length and, in particular, instance count.
Exploring State Tracking Capabilities of Large Language Models
Nov 13, 2025Large Language Models (LLMs) have demonstrated impressive capabilities in solving complex tasks, including those requiring a certain level of reasoning. In this paper, we focus on state tracking, a problem where models need to keep track of the state governing a number of entities. To isolate the state tracking component from other factors, we propose a benchmark based on three well-defined state tracking tasks and analyse the performance of LLMs in different scenarios. The results indicate that the recent generation of LLMs (specifically, GPT-4 and Llama3) are capable of tracking state, especially when integrated with mechanisms such as Chain of Thought. However, models from the former generation, while understanding the task and being able to solve it at the initial stages, often fail at this task after a certain number of steps.
MORABLES: A Benchmark for Assessing Abstract Moral Reasoning in LLMs with Fables
Sep 15, 2025As LLMs excel on standard reading comprehension benchmarks, attention is shifting toward evaluating their capacity for complex abstract reasoning and inference. Literature-based benchmarks, with their rich narrative and moral depth, provide a compelling framework for evaluating such deeper comprehension skills. Here, we present MORABLES, a human-verified benchmark built from fables and short stories drawn from historical literature. The main task is structured as multiple-choice questions targeting moral inference, with carefully crafted distractors that challenge models to go beyond shallow, extractive question answering. To further stress-test model robustness, we introduce adversarial variants designed to surface LLM vulnerabilities and shortcuts due to issues such as data contamination. Our findings show that, while larger models outperform smaller ones, they remain susceptible to adversarial manipulation and often rely on superficial patterns rather than true moral reasoning. This brittleness results in significant self-contradiction, with the best models refuting their own answers in roughly 20% of cases depending on the framing of the moral choice. Interestingly, reasoning-enhanced models fail to bridge this gap, suggesting that scale - not reasoning ability - is the primary driver of performance.
Graph of Attacks: Improved Black-Box and Interpretable Jailbreaks for LLMs
Apr 26, 2025The challenge of ensuring Large Language Models (LLMs) align with societal standards is of increasing interest, as these models are still prone to adversarial jailbreaks that bypass their safety mechanisms. Identifying these vulnerabilities is crucial for enhancing the robustness of LLMs against such exploits. We propose Graph of ATtacks (GoAT), a method for generating adversarial prompts to test the robustness of LLM alignment using the Graph of Thoughts framework [Besta et al., 2024]. GoAT excels at generating highly effective jailbreak prompts with fewer queries to the victim model than state-of-the-art attacks, achieving up to five times better jailbreak success rate against robust models like Llama. Notably, GoAT creates high-quality, human-readable prompts without requiring access to the targeted model's parameters, making it a black-box attack. Unlike approaches constrained by tree-based reasoning, GoAT's reasoning is based on a more intricate graph structure. By making simultaneous attack paths aware of each other's progress, this dynamic framework allows a deeper integration and refinement of reasoning paths, significantly enhancing the collaborative exploration of adversarial vulnerabilities in LLMs. At a technical level, GoAT starts with a graph structure and iteratively refines it by combining and improving thoughts, enabling synergy between different thought paths. The code for our implementation can be found at: https://github.com/GoAT-pydev/Graph_of_Attacks.
Gender Encoding Patterns in Pretrained Language Model Representations
Mar 09, 2025



Gender bias in pretrained language models (PLMs) poses significant social and ethical challenges. Despite growing awareness, there is a lack of comprehensive investigation into how different models internally represent and propagate such biases. This study adopts an information-theoretic approach to analyze how gender biases are encoded within various encoder-based architectures. We focus on three key aspects: identifying how models encode gender information and biases, examining the impact of bias mitigation techniques and fine-tuning on the encoded biases and their effectiveness, and exploring how model design differences influence the encoding of biases. Through rigorous and systematic investigation, our findings reveal a consistent pattern of gender encoding across diverse models. Surprisingly, debiasing techniques often exhibit limited efficacy, sometimes inadvertently increasing the encoded bias in internal representations while reducing bias in model output distributions. This highlights a disconnect between mitigating bias in output distributions and addressing its internal representations. This work provides valuable guidance for advancing bias mitigation strategies and fostering the development of more equitable language models.
PerCul: A Story-Driven Cultural Evaluation of LLMs in Persian
Feb 11, 2025



Large language models predominantly reflect Western cultures, largely due to the dominance of English-centric training data. This imbalance presents a significant challenge, as LLMs are increasingly used across diverse contexts without adequate evaluation of their cultural competence in non-English languages, including Persian. To address this gap, we introduce PerCul, a carefully constructed dataset designed to assess the sensitivity of LLMs toward Persian culture. PerCul features story-based, multiple-choice questions that capture culturally nuanced scenarios. Unlike existing benchmarks, PerCul is curated with input from native Persian annotators to ensure authenticity and to prevent the use of translation as a shortcut. We evaluate several state-of-the-art multilingual and Persian-specific LLMs, establishing a foundation for future research in cross-cultural NLP evaluation. Our experiments demonstrate a 11.3% gap between best closed source model and layperson baseline while the gap increases to 21.3% by using the best open-weight model. You can access the dataset from here: https://huggingface.co/datasets/teias-ai/percul
Blind Men and the Elephant: Diverse Perspectives on Gender Stereotypes in Benchmark Datasets
Jan 02, 2025


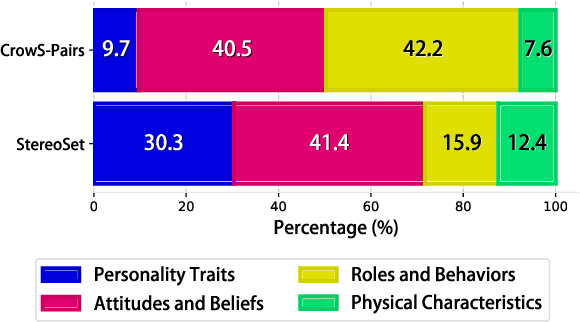
The multifaceted challenge of accurately measuring gender stereotypical bias in language models is akin to discerning different segments of a broader, unseen entity. This short paper primarily focuses on intrinsic bias mitigation and measurement strategies for language models, building on prior research that demonstrates a lack of correlation between intrinsic and extrinsic approaches. We delve deeper into intrinsic measurements, identifying inconsistencies and suggesting that these benchmarks may reflect different facets of gender stereotype. Our methodology involves analyzing data distributions across datasets and integrating gender stereotype components informed by social psychology. By adjusting the distribution of two datasets, we achieve a better alignment of outcomes. Our findings underscore the complexity of gender stereotyping in language models and point to new directions for developing more refined techniques to detect and reduce bias.
FarExStance: Explainable Stance Detection for Farsi
Dec 18, 2024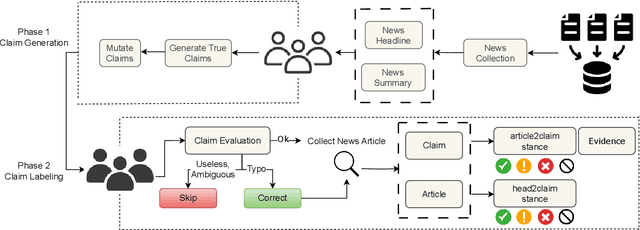
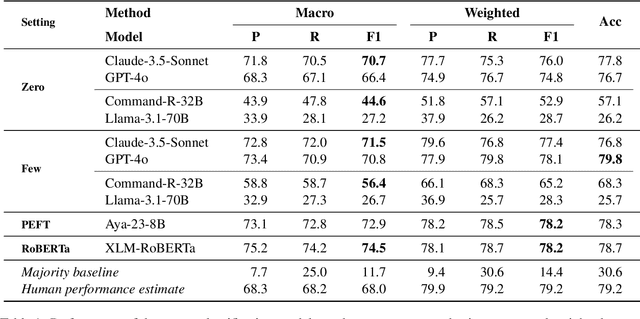

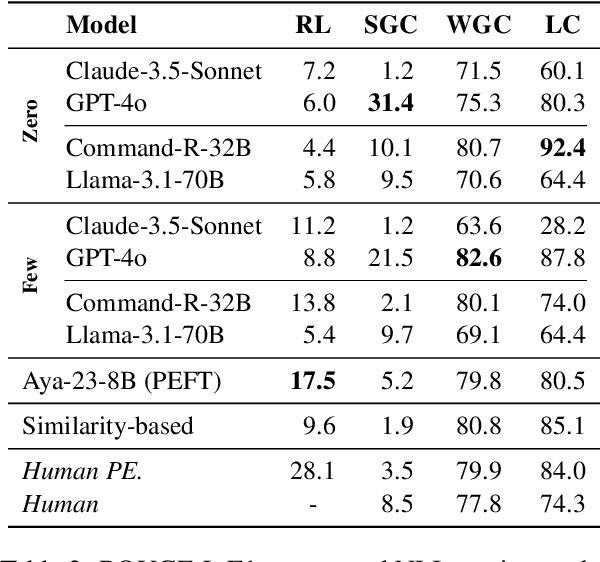
We introduce FarExStance, a new dataset for explainable stance detection in Farsi. Each instance in this dataset contains a claim, the stance of an article or social media post towards that claim, and an extractive explanation which provides evidence for the stance label. We compare the performance of a fine-tuned multilingual RoBERTa model to several large language models in zero-shot, few-shot, and parameter-efficient fine-tuned settings on our new dataset. On stance detection, the most accurate models are the fine-tuned RoBERTa model, the LLM Aya-23-8B which has been fine-tuned using parameter-efficient fine-tuning, and few-shot Claude-3.5-Sonnet. Regarding the quality of the explanations, our automatic evaluation metrics indicate that few-shot GPT-4o generates the most coherent explanations, while our human evaluation reveals that the best Overall Explanation Score (OES) belongs to few-shot Claude-3.5-Sonnet. The fine-tuned Aya-32-8B model produced explanations most closely aligned with the reference explanations.
NormXLogit: The Head-on-Top Never Lies
Nov 25, 2024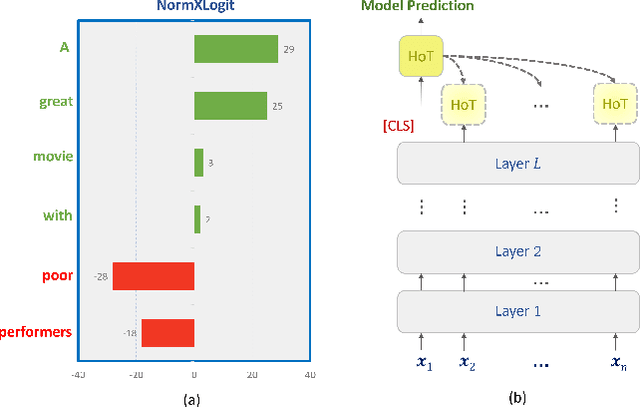
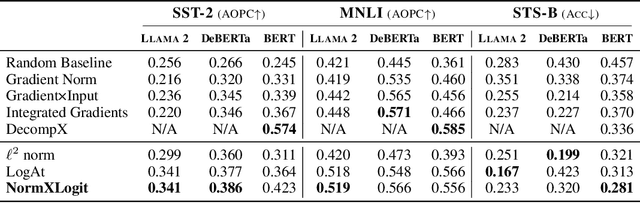
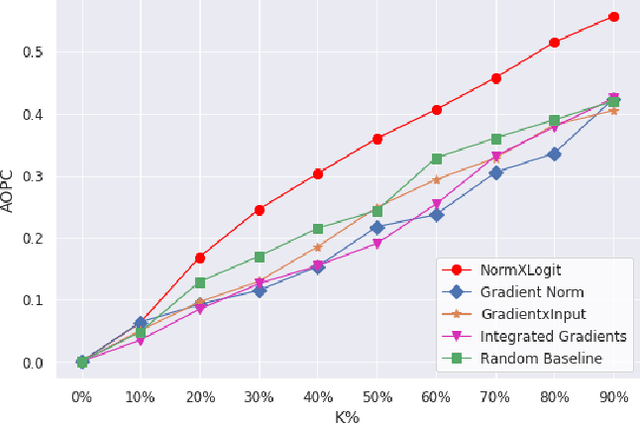

The Transformer architecture has emerged as the dominant choice for building large language models (LLMs). However, with new LLMs emerging on a frequent basis, it is important to consider the potential value of architecture-agnostic approaches that can provide interpretability across a variety of architectures. Despite recent successes in the interpretability of LLMs, many existing approaches rely on complex methods that are often tied to a specific model design and come with a significant computational cost. To address these limitations, we propose a novel technique, called NormXLogit, for assessing the significance of individual input tokens. This method operates based on the input and output representations associated with each token. First, we demonstrate that during the pre-training of LLMs, the norms of word embeddings capture the importance of input tokens. Second, we reveal a significant relationship between a token's importance and the extent to which its representation can resemble the model's final prediction. Through extensive analysis, we show that our approach consistently outperforms existing gradient-based methods in terms of faithfulness. Additionally, our method achieves better performance in layer-wise explanations compared to the most prominent architecture-specific methods.
LibraGrad: Balancing Gradient Flow for Universally Better Vision Transformer Attributions
Nov 24, 2024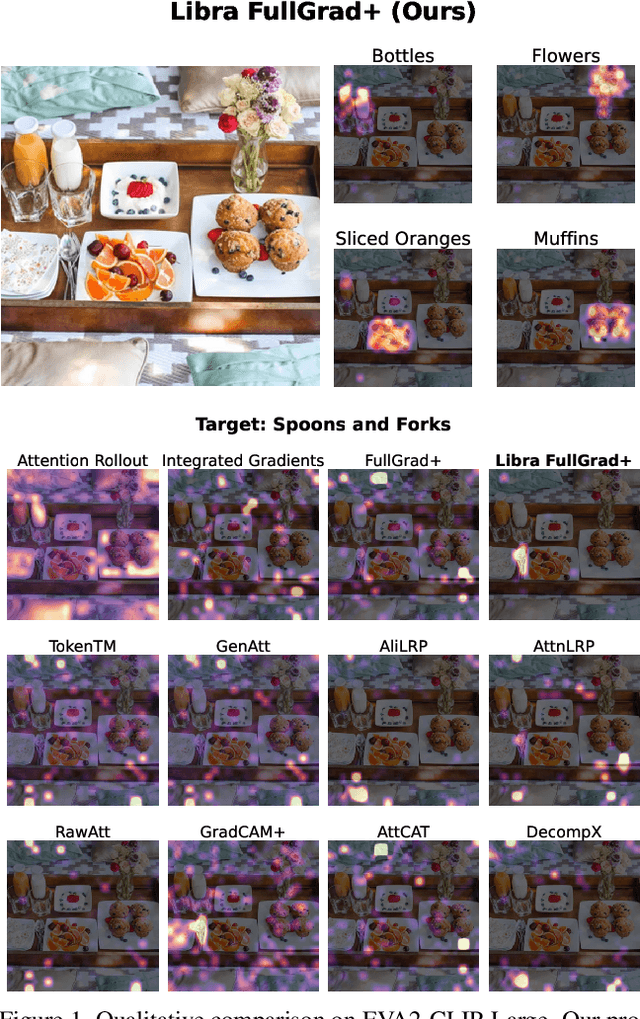



Why do gradient-based explanations struggle with Transformers, and how can we improve them? We identify gradient flow imbalances in Transformers that violate FullGrad-completeness, a critical property for attribution faithfulness that CNNs naturally possess. To address this issue, we introduce LibraGrad -- a theoretically grounded post-hoc approach that corrects gradient imbalances through pruning and scaling of backward paths, without changing the forward pass or adding computational overhead. We evaluate LibraGrad using three metric families: Faithfulness, which quantifies prediction changes under perturbations of the most and least relevant features; Completeness Error, which measures attribution conservation relative to model outputs; and Segmentation AP, which assesses alignment with human perception. Extensive experiments across 8 architectures, 4 model sizes, and 4 datasets show that LibraGrad universally enhances gradient-based methods, outperforming existing white-box methods -- including Transformer-specific approaches -- across all metrics. We demonstrate superior qualitative results through two complementary evaluations: precise text-prompted region highlighting on CLIP models and accurate class discrimination between co-occurring animals on ImageNet-finetuned models -- two settings on which existing methods often struggle. LibraGrad is effective even on the attention-free MLP-Mixer architecture, indicating potential for extension to other modern architectures. Our code is freely available at https://github.com/NightMachinery/LibraGrad.