 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Encoding Patterns in Pretrained Language Model Representations
Mar 09, 2025



Gender bias in pretrained language models (PLMs) poses significant social and ethical challenges. Despite growing awareness, there is a lack of comprehensive investigation into how different models internally represent and propagate such biases. This study adopts an information-theoretic approach to analyze how gender biases are encoded within various encoder-based architectures. We focus on three key aspects: identifying how models encode gender information and biases, examining the impact of bias mitigation techniques and fine-tuning on the encoded biases and their effectiveness, and exploring how model design differences influence the encoding of biases. Through rigorous and systematic investigation, our findings reveal a consistent pattern of gender encoding across diverse models. Surprisingly, debiasing techniques often exhibit limited efficacy, sometimes inadvertently increasing the encoded bias in internal representations while reducing bias in model output distributions. This highlights a disconnect between mitigating bias in output distributions and addressing its internal representations. This work provides valuable guidance for advancing bias mitigation strategies and fostering the development of more equitable language models.
Blind Men and the Elephant: Diverse Perspectives on Gender Stereotypes in Benchmark Datasets
Jan 02, 2025


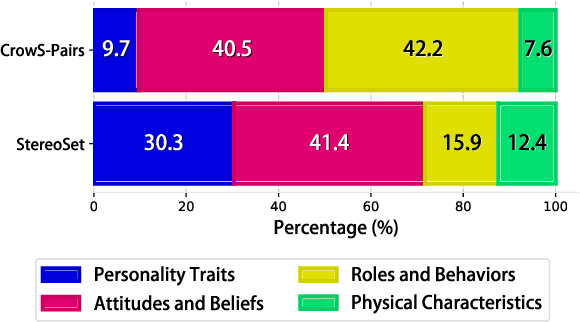
The multifaceted challenge of accurately measuring gender stereotypical bias in language models is akin to discerning different segments of a broader, unseen entity. This short paper primarily focuses on intrinsic bias mitigation and measurement strategies for language models, building on prior research that demonstrates a lack of correlation between intrinsic and extrinsic approaches. We delve deeper into intrinsic measurements, identifying inconsistencies and suggesting that these benchmarks may reflect different facets of gender stereotype. Our methodology involves analyzing data distributions across datasets and integrating gender stereotype components informed by social psychology. By adjusting the distribution of two datasets, we achieve a better alignment of outcomes. Our findings underscore the complexity of gender stereotyping in language models and point to new directions for developing more refined techniques to detect and reduce bias.
DiFair: A Benchmark for Disentangled Assessment of Gender Knowledge and Bias
Oct 22, 2023
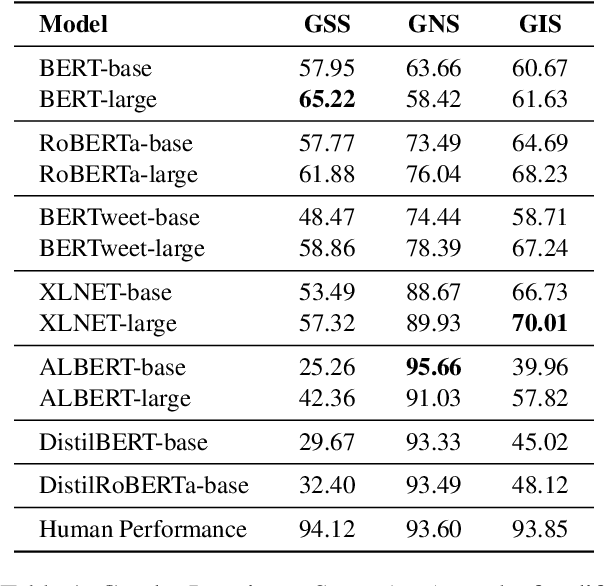


Numerous debiasing techniques have been proposed to mitigate the gender bias that is prevalent in pretrained language models. These are often evaluated on datasets that check the extent to which the model is gender-neutral in its predictions. Importantly, this evaluation protocol overlooks the possible adverse impact of bias mitigation on useful gender knowledge. To fill this gap, we propose DiFair, a manually curated dataset based on masked language modeling objectives. DiFair allows us to introduce a unified metric, gender invariance score, that not only quantifies a model's biased behavior, but also checks if useful gender knowledge is preserved. We use DiFair as a benchmark for a number of widely-used pretained language models and debiasing techniques. Experimental results corroborate previous findings on the existing gender biases, while also demonstrating that although debiasing techniques ameliorate the issue of gender bias, this improvement usually comes at the price of lowering useful gender knowledge of the model.