 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiFair: A Benchmark for Disentangled Assessment of Gender Knowledge and Bias
Paper and Code

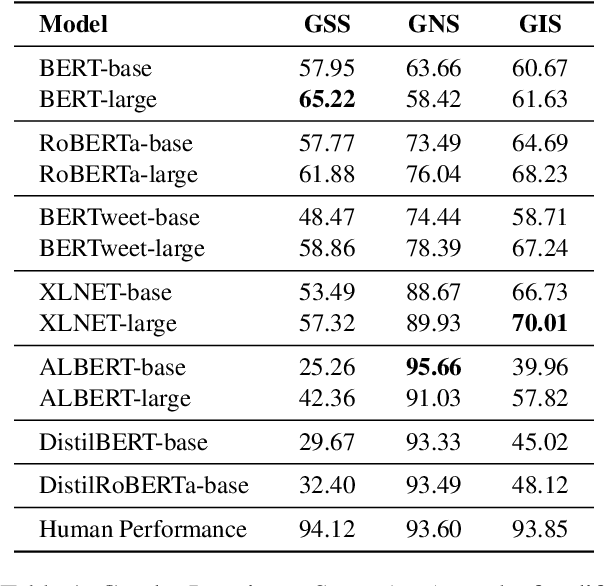


Numerous debiasing techniques have been proposed to mitigate the gender bias that is prevalent in pretrained language models. These are often evaluated on datasets that check the extent to which the model is gender-neutral in its predictions. Importantly, this evaluation protocol overlooks the possible adverse impact of bias mitigation on useful gender knowledge. To fill this gap, we propose DiFair, a manually curated dataset based on masked language modeling objectives. DiFair allows us to introduce a unified metric, gender invariance score, that not only quantifies a model's biased behavior, but also checks if useful gender knowledge is preserved. We use DiFair as a benchmark for a number of widely-used pretained language models and debiasing techniques. Experimental results corroborate previous findings on the existing gender biases, while also demonstrating that although debiasing techniques ameliorate the issue of gender bias, this improvement usually comes at the price of lowering useful gender knowledge of the model.