 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARSA-Bench: A Comprehensive Persian Audio-Language Model Benchmark
Mar 15, 2026Persian poses unique audio understanding challenges through its classical poetry, traditional music, and pervasive code-switching - none captured by existing benchmarks. We introduce PARSA-Bench (Persian Audio Reasoning and Speech Assessment Benchmark), the first benchmark for evaluating large audio-language models on Persian language and culture, comprising 16 tasks and over 8,000 samples across speech understanding, paralinguistic analysis, and cultural audio understanding. Ten tasks are newly introduced, including poetry meter and style detection, traditional Persian music understanding, and code-switching detection. Text-only baselines consistently outperform audio counterparts, suggesting models may not leverage audio-specific information beyond what transcription alone provides. Culturally-grounded tasks expose a qualitatively distinct failure mode: all models perform near random chance on vazn detection regardless of scale, suggesting prosodic perception remains beyond the reach of current models. The dataset is publicly available at https://huggingface.co/datasets/MohammadJRanjbar/PARSA-Bench
PersianPunc: A Large-Scale Dataset and BERT-Based Approach for Persian Punctuation Restoration
Mar 05, 2026Punctuation restoration is essential for improving the readability and downstream utility of automatic speech recognition (ASR) outputs, yet remains underexplored for Persian despite its importance. We introduce PersianPunc, a large-scale, high-quality dataset of 17 million samples for Persian punctuation restoration, constructed through systematic aggregation and filtering of existing textual resources. We formulate punctuation restoration as a token-level sequence labeling task and fine-tune ParsBERT to achieve strong performance. Through comparative evaluation, we demonstrate that while large language models can perform punctuation restoration, they suffer from critical limitations: over-correction tendencies that introduce undesired edits beyond punctuation insertion (particularly problematic for speech-to-text pipelines) and substantially higher computational requirements. Our lightweight BERT-based approach achieves a macro-averaged F1 score of 91.33% on our test set while maintaining efficiency suitable for real-time applications. We make our dataset (https://huggingface.co/datasets/MohammadJRanjbar/persian-punctuation-restoration) and model (https://huggingface.co/MohammadJRanjbar/parsbert-persian-punctuation) publicly available to facilitate future research in Persian NLP and provide a scalable framework applicable to other morphologically rich, low-resource languages.
PolitiSky24: U.S. Political Bluesky Dataset with User Stance Labels
Jun 09, 2025Stance detection identifies the viewpoint expressed in text toward a specific target, such as a political figure. While previous datasets have focused primarily on tweet-level stances from established platforms, user-level stance resources, especially on emerging platforms like Bluesky remain scarce. User-level stance detection provides a more holistic view by considering a user's complete posting history rather than isolated posts. We present the first stance detection dataset for the 2024 U.S. presidential election, collected from Bluesky and centered on Kamala Harris and Donald Trump. The dataset comprises 16,044 user-target stance pairs enriched with engagement metadata, interaction graphs, and user posting histories. PolitiSky24 was created using a carefully evaluated pipeline combining advanced information retrieval and large language models, which generates stance labels with supporting rationales and text spans for transparency. The labeling approach achieves 81\% accuracy with scalable LLMs. This resource addresses gaps in political stance analysis through its timeliness, open-data nature, and user-level perspective. The dataset is available at https://doi.org/10.5281/zenodo.15616911
From Millions of Tweets to Actionable Insights: Leveraging LLMs for User Profiling
May 09, 2025



Social media user profiling through content analysis is crucial for tasks like misinformation detection, engagement prediction, hate speech monitoring, and user behavior modeling. However, existing profiling techniques, including tweet summarization, attribute-based profiling, and latent representation learning, face significant limitations: they often lack transferability, produce non-interpretable features, require large labeled datasets, or rely on rigid predefined categories that limit adaptability. We introduce a novel large language model (LLM)-based approach that leverages domain-defining statements, which serve as key characteristics outlining the important pillars of a domain as foundations for profiling. Our two-stage method first employs semi-supervised filtering with a domain-specific knowledge base, then generates both abstractive (synthesized descriptions) and extractive (representative tweet selections) user profiles. By harnessing LLMs' inherent knowledge with minimal human validation, our approach is adaptable across domains while reducing the need for large labeled datasets. Our method generates interpretable natural language user profiles, condensing extensive user data into a scale that unlocks LLMs' reasoning and knowledge capabilities for downstream social network tasks. We contribute a Persian political Twitter (X) dataset and an LLM-based evaluation framework with human validation. Experimental results show our method significantly outperforms state-of-the-art LLM-based and traditional methods by 9.8%, demonstrating its effectiveness in creating flexible, adaptable, and interpretable user profiles.
PerCul: A Story-Driven Cultural Evaluation of LLMs in Persian
Feb 11, 2025



Large language models predominantly reflect Western cultures, largely due to the dominance of English-centric training data. This imbalance presents a significant challenge, as LLMs are increasingly used across diverse contexts without adequate evaluation of their cultural competence in non-English languages, including Persian. To address this gap, we introduce PerCul, a carefully constructed dataset designed to assess the sensitivity of LLMs toward Persian culture. PerCul features story-based, multiple-choice questions that capture culturally nuanced scenarios. Unlike existing benchmarks, PerCul is curated with input from native Persian annotators to ensure authenticity and to prevent the use of translation as a shortcut. We evaluate several state-of-the-art multilingual and Persian-specific LLMs, establishing a foundation for future research in cross-cultural NLP evaluation. Our experiments demonstrate a 11.3% gap between best closed source model and layperson baseline while the gap increases to 21.3% by using the best open-weight model. You can access the dataset from here: https://huggingface.co/datasets/teias-ai/percul
QEQR: An Exploration of Query Expansion Methods for Question Retrieval in CQA Services
Nov 23, 2024CQA services are valuable sources of knowledge that can be used to find answers to users' information needs. In these services, question retrieval aims to help users with their information needs by finding similar questions to theirs. However, finding similar questions is obstructed by the lexical gap that exists between relevant questions. In this work, we target this problem by using query expansion methods. We use word-similarity-based methods, propose a question-similarity-based method and selective expansion of these methods to expand a question that's been submitted and mitigate the lexical gap problem. Our best method achieves a significant relative improvement of 1.8\% compared to the best-performing baseline without query expansion.
PEACH: Pre-Training Sequence-to-Sequence Multilingual Models for Translation with Semi-Supervised Pseudo-Parallel Document Generation
Apr 14, 2023

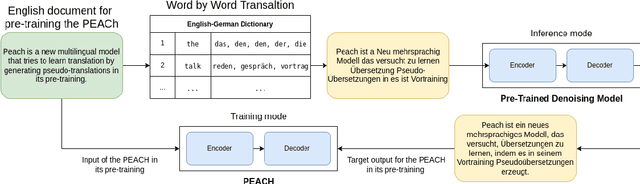

Multilingual pre-training significantly improves many multilingual NLP tasks, including machine translation. Most existing methods are based on some variants of masked language modeling and text-denoising objectives on monolingual data. Multilingual pre-training on monolingual data ignores the availability of parallel data in many language pairs. Also, some other works integrate the available human-generated parallel translation data in their pre-training. This kind of parallel data is definitely helpful, but it is limited even in high-resource language pairs. This paper introduces a novel semi-supervised method, SPDG, that generates high-quality pseudo-parallel data for multilingual pre-training. First, a denoising model is pre-trained on monolingual data to reorder, add, remove, and substitute words, enhancing the pre-training documents' quality. Then, we generate different pseudo-translations for each pre-training document using dictionaries for word-by-word translation and applying the pre-trained denoising model. The resulting pseudo-parallel data is then used to pre-train our multilingual sequence-to-sequence model, PEACH. Our experiments show that PEACH outperforms existing approaches used in training mT5 and mBART on various translation tasks, including supervised, zero- and few-shot scenarios. Moreover, PEACH's ability to transfer knowledge between similar languages makes it particularly useful for low-resource languages. Our results demonstrate that with high-quality dictionaries for generating accurate pseudo-parallel, PEACH can be valuable for low-resource languages.
Generative Adversarial Training Can Improve Neural Language Models
Nov 02, 2022
While deep learning in the form of recurrent neural networks (RNNs) has caused a significant improvement in neural language modeling, the fact that they are extremely prone to overfitting is still a mainly unresolved issue. In this paper we propose a regularization method based on generative adversarial networks (GANs) and adversarial training (AT), that can prevent overfitting in neural language models. Unlike common adversarial training methods such as the fast gradient sign method (FGSM) that require a second back-propagation through time, and therefore effectively require at least twice the amount of time for regular training, the overhead of our method does not exceed more than 20% of the training of the baselines.
$Λ$-DARTS: Mitigating Performance Collapse by Harmonizing Operation Selection among Cells
Oct 14, 2022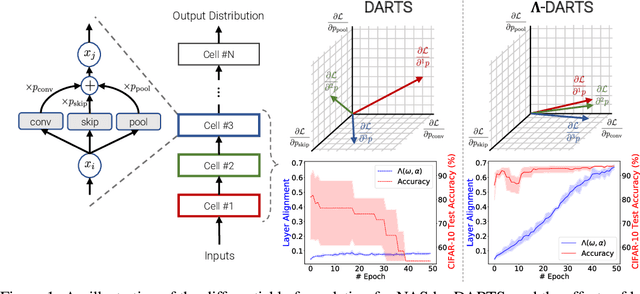
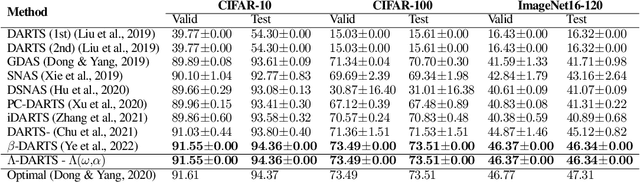

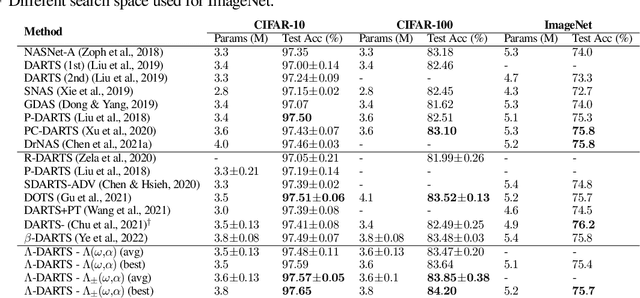
Differentiable neural architecture search (DARTS) is a popular method for neural architecture search (NAS), which performs cell-search and utilizes continuous relaxation to improve the search efficiency via gradient-based optimization. The main shortcoming of DARTS is performance collapse, where the discovered architecture suffers from a pattern of declining quality during search. Performance collapse has become an important topic of research, with many methods trying to solve the issue through either regularization or fundamental changes to DARTS. However, the weight-sharing framework used for cell-search in DARTS and the convergence of architecture parameters has not been analyzed yet. In this paper, we provide a thorough and novel theoretical and empirical analysis on DARTS and its point of convergence. We show that DARTS suffers from a specific structural flaw due to its weight-sharing framework that limits the convergence of DARTS to saturation points of the softmax function. This point of convergence gives an unfair advantage to layers closer to the output in choosing the optimal architecture, causing performance collapse. We then propose two new regularization terms that aim to prevent performance collapse by harmonizing operation selection via aligning gradients of layers. Experimental results on six different search spaces and three different datasets show that our method ($\Lambda$-DARTS) does indeed prevent performance collapse, providing justification for our theoretical analysis and the proposed remedy.
ARMAN: Pre-training with Semantically Selecting and Reordering of Sentences for Persian Abstractive Summarization
Sep 09, 2021
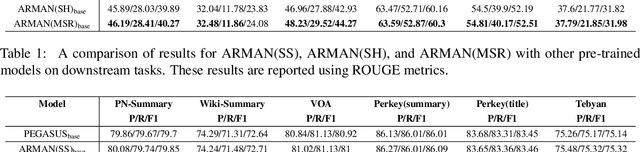


Abstractive text summarization is one of the areas influenced by the emergence of pre-trained language models. Current pre-training works in abstractive summarization give more points to the summaries with more words in common with the main text and pay less attention to the semantic similarity between generated sentences and the original document. We propose ARMAN, a Transformer-based encoder-decoder model pre-trained with three novel objectives to address this issue. In ARMAN, salient sentences from a document are selected according to a modified semantic score to be masked and form a pseudo summary. To summarize more accurately and similar to human writing patterns, we applied modified sentence reordering. We evaluated our proposed models on six downstream Persian summarization tasks. Experimental results show that our proposed model achieves state-of-the-art performance on all six summarization tasks measured by ROUGE and BERTScore. Our models also outperform prior works in textual entailment, question paraphrasing, and multiple choice question answering. Finally, we established a human evaluation and show that using the semantic score significantly improves summarization results.