Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTNLP at SemEval-2021 Task 5: A Comparative Analysis of Toxic Span Detection using Attention-based, Named Entity Recognition, and Ensemble Models
Paper and Code

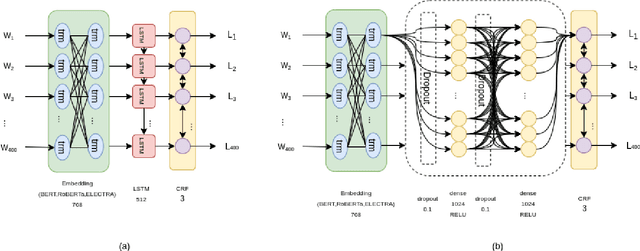
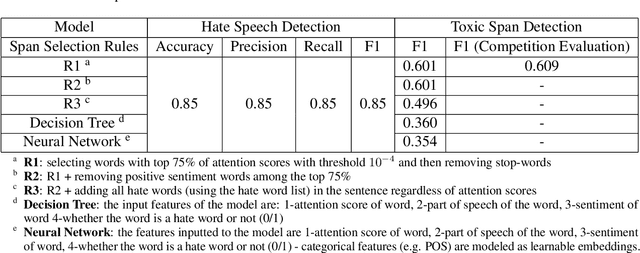
Detecting which parts of a sentence contribute to that sentence's toxicity -- rather than providing a sentence-level verdict of hatefulness -- would increase the interpretability of models and allow human moderators to better understand the outputs of the system. This paper presents our team's, UTNLP, methodology and results in the SemEval-2021 shared task 5 on toxic spans detection. We test multiple models and contextual embeddings and report the best setting out of all. The experiments start with keyword-based models and are followed by attention-based, named entity-based, transformers-based, and ensemble models. Our best approach, an ensemble model, achieves an F1 of 0.684 in the competition's evaluation phase.
View paper on