 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMAN: Pre-training with Semantically Selecting and Reordering of Sentences for Persian Abstractive Summarization
Sep 09, 2021
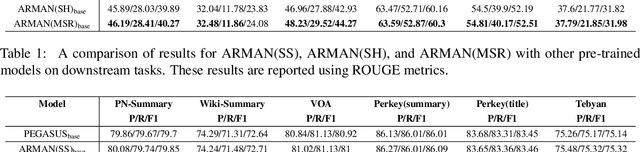


Abstractive text summarization is one of the areas influenced by the emergence of pre-trained language models. Current pre-training works in abstractive summarization give more points to the summaries with more words in common with the main text and pay less attention to the semantic similarity between generated sentences and the original document. We propose ARMAN, a Transformer-based encoder-decoder model pre-trained with three novel objectives to address this issue. In ARMAN, salient sentences from a document are selected according to a modified semantic score to be masked and form a pseudo summary. To summarize more accurately and similar to human writing patterns, we applied modified sentence reordering. We evaluated our proposed models on six downstream Persian summarization tasks. Experimental results show that our proposed model achieves state-of-the-art performance on all six summarization tasks measured by ROUGE and BERTScore. Our models also outperform prior works in textual entailment, question paraphrasing, and multiple choice question answering. Finally, we established a human evaluation and show that using the semantic score significantly improves summarization results.
UTNLP at SemEval-2021 Task 5: A Comparative Analysis of Toxic Span Detection using Attention-based, Named Entity Recognition, and Ensemble Models
Apr 10, 2021
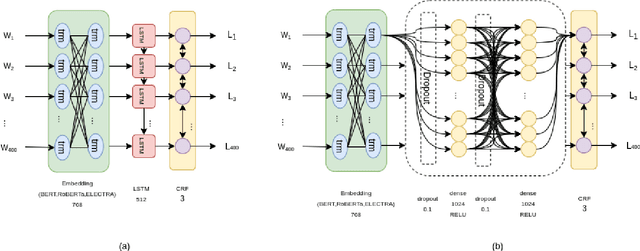
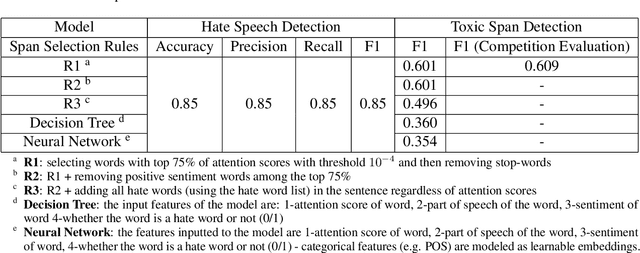
Detecting which parts of a sentence contribute to that sentence's toxicity -- rather than providing a sentence-level verdict of hatefulness -- would increase the interpretability of models and allow human moderators to better understand the outputs of the system. This paper presents our team's, UTNLP, methodology and results in the SemEval-2021 shared task 5 on toxic spans detection. We test multiple models and contextual embeddings and report the best setting out of all. The experiments start with keyword-based models and are followed by attention-based, named entity-based, transformers-based, and ensemble models. Our best approach, an ensemble model, achieves an F1 of 0.684 in the competition's evaluation phase.
Deep Sentiment Analysis using a Graph-based Text Representation
Feb 23, 2019
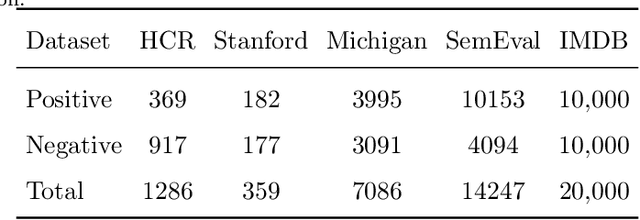
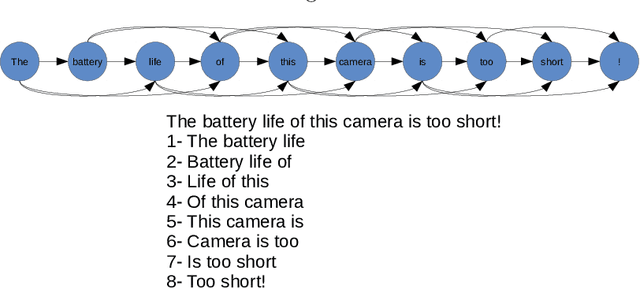

Social media brings about new ways of communication among people and is influencing trading strategies in the market. The popularity of social networks produces a large collection of unstructured data such as text and image in a variety of disciplines like business and health. The main element of social media arises as text which provokes a set of challenges for traditional information retrieval and natural language processing tools. Informal language, spelling errors, abbreviations, and special characters are typical in social media posts. These features lead to a prohibitively large vocabulary size for text mining methods. Another problem with traditional social text mining techniques is that they fail to take semantic relations into account, which is essential in a domain of applications such as event detection, opinion mining, and news recommendation. This paper set out to employ a network-based viewpoint on text documents and investigate the usefulness of graph representation to exploit word relations and semantics of the textual data. Moreover, the proposed approach makes use of a random walker to extract deep features of a graph to facilitate the task of document classification. The experimental results indicate that the proposed approach defeats the earlier sentiment analysis methods based on several benchmark datasets, and it generalizes well on different datasets without dependency for pre-trained word embeddings.