 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP for Social Good: A Survey of Challenges, Opportunities, and Responsible Deployment
May 28, 2025



Recent advancements in large language models (LLMs) have unlocked unprecedented possibilities across a range of applications. However, as a community, we believe that the field of Natural Language Processing (NLP) has a growing need to approach deployment with greater intentionality and responsibility. In alignment with the broader vision of AI for Social Good (Toma\v{s}ev et al., 2020), this paper examines the role of NLP in addressing pressing societal challenges. Through a cross-disciplinary analysis of social goals and emerging risks, we highlight promising research directions and outline challenges that must be addressed to ensure responsible and equitable progress in NLP4SG research.
#EpiTwitter: Public Health Messaging During the COVID-19 Pandemic
Jun 04, 2024



Effective communication during health crises is critical, with social media serving as a key platform for public health experts (PHEs) to engage with the public. However, it also amplifies pseudo-experts promoting contrarian views. Despite its importance, the role of emotional and moral language in PHEs' communication during COVID-19 remains under explored. This study examines how PHEs and pseudo-experts communicated on Twitter during the pandemic, focusing on emotional and moral language and their engagement with political elites. Analyzing tweets from 489 PHEs and 356 pseudo-experts from January 2020 to January 2021, alongside public responses, we identified key priorities and differences in messaging strategy. PHEs prioritize masking, healthcare, education, and vaccines, using positive emotional language like optimism. In contrast, pseudo-experts discuss therapeutics and lockdowns more frequently, employing negative emotions like pessimism and disgust. Negative emotional and moral language tends to drive engagement, but positive language from PHEs fosters positivity in public responses. PHEs exhibit liberal partisanship, expressing more positivity towards liberals and negativity towards conservative elites, while pseudo-experts show conservative partisanship. These findings shed light on the polarization of COVID-19 discourse and underscore the importance of strategic use of emotional and moral language by experts to mitigate polarization and enhance public trust.
Crab: Learning Certifiably Fair Predictive Models in the Presence of Selection Bias
Dec 21, 2022A recent explosion of research focuses on developing methods and tools for building fair predictive models. However, most of this work relies on the assumption that the training and testing data are representative of the target population on which the model will be deployed. However, real-world training data often suffer from selection bias and are not representative of the target population for many reasons, including the cost and feasibility of collecting and labeling data, historical discrimination, and individual biases. In this paper, we introduce a new framework for certifying and ensuring the fairness of predictive models trained on biased data. We take inspiration from query answering over incomplete and inconsistent databases to present and formalize the problem of consistent range approximation (CRA) of answers to queries about aggregate information for the target population. We aim to leverage background knowledge about the data collection process, biased data, and limited or no auxiliary data sources to compute a range of answers for aggregate queries over the target population that are consistent with available information. We then develop methods that use CRA of such aggregate queries to build predictive models that are certifiably fair on the target population even when no external information about that population is available during training. We evaluate our methods on real data and demonstrate improvements over state of the art. Significantly, we show that enforcing fairness using our methods can lead to predictive models that are not only fair, but more accurate on the target population.
Persian Emotion Detection using ParsBERT and Imbalanced Data Handling Approaches
Nov 17, 2022



Emotion recognition is one of the machine learning applications which can be done using text, speech, or image data gathered from social media spaces. Detecting emotion can help us in different fields, including opinion mining. With the spread of social media, different platforms like Twitter have become data sources, and the language used in these platforms is informal, making the emotion detection task difficult. EmoPars and ArmanEmo are two new human-labeled emotion datasets for the Persian language. These datasets, especially EmoPars, are suffering from inequality between several samples between two classes. In this paper, we evaluate EmoPars and compare them with ArmanEmo. Throughout this analysis, we use data augmentation techniques, data re-sampling, and class-weights with Transformer-based Pretrained Language Models(PLMs) to handle the imbalance problem of these datasets. Moreover, feature selection is used to enhance the models' performance by emphasizing the text's specific features. In addition, we provide a new policy for selecting data from EmoPars, which selects the high-confidence samples; as a result, the model does not see samples that do not have specific emotion during training. Our model reaches a Macro-averaged F1-score of 0.81 and 0.76 on ArmanEmo and EmoPars, respectively, which are new state-of-the-art results in these benchmarks.
* 14 pages, 5 figures, 9 tables
UTNLP at SemEval-2021 Task 5: A Comparative Analysis of Toxic Span Detection using Attention-based, Named Entity Recognition, and Ensemble Models
Apr 10, 2021
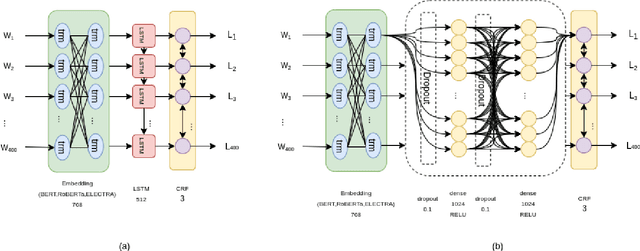
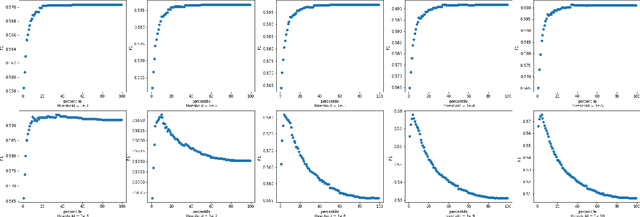
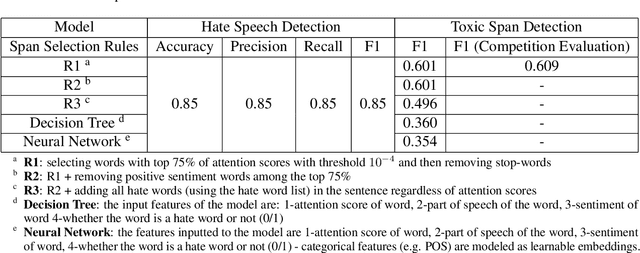
Detecting which parts of a sentence contribute to that sentence's toxicity -- rather than providing a sentence-level verdict of hatefulness -- would increase the interpretability of models and allow human moderators to better understand the outputs of the system. This paper presents our team's, UTNLP, methodology and results in the SemEval-2021 shared task 5 on toxic spans detection. We test multiple models and contextual embeddings and report the best setting out of all. The experiments start with keyword-based models and are followed by attention-based, named entity-based, transformers-based, and ensemble models. Our best approach, an ensemble model, achieves an F1 of 0.684 in the competition's evaluation phase.
Sentiment Analysis of Persian-English Code-mixed Texts
Feb 25, 2021

The rapid production of data on the internet and the need to understand how users are feeling from a business and research perspective has prompted the creation of numerous automatic monolingual sentiment detection systems. More recently however, due to the unstructured nature of data on social media, we are observing more instances of multilingual and code-mixed texts. This development in content type has created a new demand for code-mixed sentiment analysis systems. In this study we collect, label and thus create a dataset of Persian-English code-mixed tweets. We then proceed to introduce a model which uses BERT pretrained embeddings as well as translation models to automatically learn the polarity scores of these Tweets. Our model outperforms the baseline models that use Na\"ive Bayes and Random Forest methods.