 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Causal Effects of Text Interventions Leveraging LLMs
Oct 28, 2024Quantifying the effect of textual interventions in social systems, such as reducing anger in social media posts to see its impact on engagement, poses significant challenges. Direct interventions on real-world systems are often infeasible, necessitating reliance on observational data. Traditional causal inference methods, typically designed for binary or discrete treatments, are inadequate for handling the complex, high-dimensional nature of textual data. This paper addresses these challenges by proposing a novel approach, CausalDANN, to estimate causal effects using text transformations facilitated by large language models (LLMs). Unlike existing methods, our approach accommodates arbitrary textual interventions and leverages text-level classifiers with domain adaptation ability to produce robust effect estimates against domain shifts, even when only the control group is observed. This flexibility in handling various text interventions is a key advancement in causal estimation for textual data, offering opportunities to better understand human behaviors and develop effective policies within social systems.
COMMUNITY-CROSS-INSTRUCT: Unsupervised Instruction Generation for Aligning Large Language Models to Online Communities
Jun 17, 2024


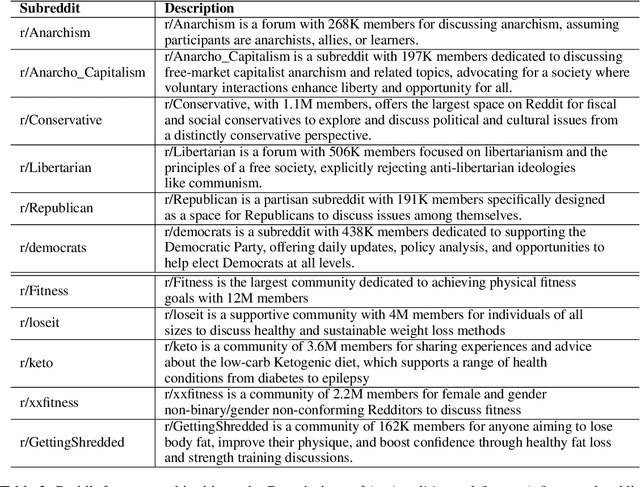
Social scientists use surveys to probe the opinions and beliefs of populations, but these methods are slow, costly, and prone to biases. Recent advances in large language models (LLMs) enable creating computational representations or "digital twins" of populations that generate human-like responses mimicking the population's language, styles, and attitudes. We introduce Community-Cross-Instruct, an unsupervised framework for aligning LLMs to online communities to elicit their beliefs. Given a corpus of a community's online discussions, Community-Cross-Instruct automatically generates instruction-output pairs by an advanced LLM to (1) finetune an foundational LLM to faithfully represent that community, and (2) evaluate the alignment of the finetuned model to the community. We demonstrate the method's utility in accurately representing political and fitness communities on Reddit. Unlike prior methods requiring human-authored instructions, Community-Cross-Instruct generates instructions in a fully unsupervised manner, enhancing scalability and generalization across domains. This work enables cost-effective and automated surveying of diverse online communities.
#EpiTwitter: Public Health Messaging During the COVID-19 Pandemic
Jun 04, 2024



Effective communication during health crises is critical, with social media serving as a key platform for public health experts (PHEs) to engage with the public. However, it also amplifies pseudo-experts promoting contrarian views. Despite its importance, the role of emotional and moral language in PHEs' communication during COVID-19 remains under explored. This study examines how PHEs and pseudo-experts communicated on Twitter during the pandemic, focusing on emotional and moral language and their engagement with political elites. Analyzing tweets from 489 PHEs and 356 pseudo-experts from January 2020 to January 2021, alongside public responses, we identified key priorities and differences in messaging strategy. PHEs prioritize masking, healthcare, education, and vaccines, using positive emotional language like optimism. In contrast, pseudo-experts discuss therapeutics and lockdowns more frequently, employing negative emotions like pessimism and disgust. Negative emotional and moral language tends to drive engagement, but positive language from PHEs fosters positivity in public responses. PHEs exhibit liberal partisanship, expressing more positivity towards liberals and negativity towards conservative elites, while pseudo-experts show conservative partisanship. These findings shed light on the polarization of COVID-19 discourse and underscore the importance of strategic use of emotional and moral language by experts to mitigate polarization and enhance public trust.
SoMeR: Multi-View User Representation Learning for Social Media
May 02, 2024



User representation learning aims to capture user preferences, interests, and behaviors in low-dimensional vector representations. These representations have widespread applications in recommendation systems and advertising; however, existing methods typically rely on specific features like text content, activity patterns, or platform metadata, failing to holistically model user behavior across different modalities. To address this limitation, we propose SoMeR, a Social Media user Representation learning framework that incorporates temporal activities, text content, profile information, and network interactions to learn comprehensive user portraits. SoMeR encodes user post streams as sequences of timestamped textual features, uses transformers to embed this along with profile data, and jointly trains with link prediction and contrastive learning objectives to capture user similarity. We demonstrate SoMeR's versatility through two applications: 1) Identifying inauthentic accounts involved in coordinated influence operations by detecting users posting similar content simultaneously, and 2) Measuring increased polarization in online discussions after major events by quantifying how users with different beliefs moved farther apart in the embedding space. SoMeR's ability to holistically model users enables new solutions to important problems around disinformation, societal tensions, and online behavior understanding.
Whose Emotions and Moral Sentiments Do Language Models Reflect?
Feb 16, 2024Language models (LMs) are known to represent the perspectives of some social groups better than others, which may impact their performance, especially on subjective tasks such as content moderation and hate speech detection. To explore how LMs represent different perspectives, existing research focused on positional alignment, i.e., how closely the models mimic the opinions and stances of different groups, e.g., liberals or conservatives. However, human communication also encompasses emotional and moral dimensions. We define the problem of affective alignment, which measures how LMs' emotional and moral tone represents those of different groups. By comparing the affect of responses generated by 36 LMs to the affect of Twitter messages, we observe significant misalignment of LMs with both ideological groups. This misalignment is larger than the partisan divide in the U.S. Even after steering the LMs towards specific ideological perspectives, the misalignment and liberal tendencies of the model persist, suggesting a systemic bias within LMs.
Reading Between the Tweets: Deciphering Ideological Stances of Interconnected Mixed-Ideology Communities
Feb 02, 2024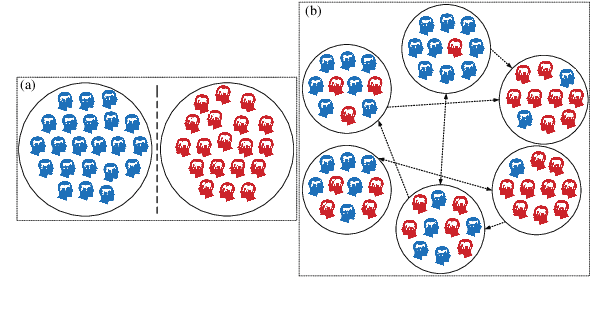
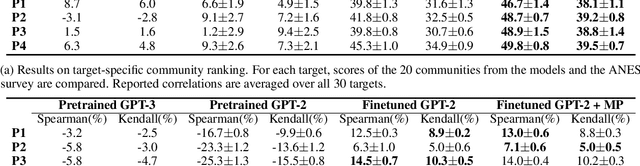
Recent advances in NLP have improved our ability to understand the nuanced worldviews of online communities. Existing research focused on probing ideological stances treats liberals and conservatives as separate groups. However, this fails to account for the nuanced views of the organically formed online communities and the connections between them. In this paper, we study discussions of the 2020 U.S. election on Twitter to identify complex interacting communities. Capitalizing on this interconnectedness, we introduce a novel approach that harnesses message passing when finetuning language models (LMs) to probe the nuanced ideologies of these communities. By comparing the responses generated by LMs and real-world survey results, our method shows higher alignment than existing baselines, highlighting the potential of using LMs in revealing complex ideologies within and across interconnected mixed-ideology communities.
Inducing Political Bias Allows Language Models Anticipate Partisan Reactions to Controversies
Nov 16, 2023



Social media platforms are rife with politically charged discussions. Therefore, accurately deciphering and predicting partisan biases using Large Language Models (LLMs) is increasingly critical. In this study, we address the challenge of understanding political bias in digitized discourse using LLMs. While traditional approaches often rely on finetuning separate models for each political faction, our work innovates by employing a singular, instruction-tuned LLM to reflect a spectrum of political ideologies. We present a comprehensive analytical framework, consisting of Partisan Bias Divergence Assessment and Partisan Class Tendency Prediction, to evaluate the model's alignment with real-world political ideologies in terms of stances, emotions, and moral foundations. Our findings reveal the model's effectiveness in capturing emotional and moral nuances, albeit with some challenges in stance detection, highlighting the intricacies and potential for refinement in NLP tools for politically sensitive contexts. This research contributes significantly to the field by demonstrating the feasibility and importance of nuanced political understanding in LLMs, particularly for applications requiring acute awareness of political bias.
A Data Fusion Framework for Multi-Domain Morality Learning
Apr 04, 2023Language models can be trained to recognize the moral sentiment of text, creating new opportunities to study the role of morality in human life. As interest in language and morality has grown, several ground truth datasets with moral annotations have been released. However, these datasets vary in the method of data collection, domain, topics, instructions for annotators, etc. Simply aggregating such heterogeneous datasets during training can yield models that fail to generalize well. We describe a data fusion framework for training on multiple heterogeneous datasets that improve performance and generalizability. The model uses domain adversarial training to align the datasets in feature space and a weighted loss function to deal with label shift. We show that the proposed framework achieves state-of-the-art performance in different datasets compared to prior works in morality inference.
Inherent Trade-offs in the Fair Allocation of Treatments
Oct 30, 2020
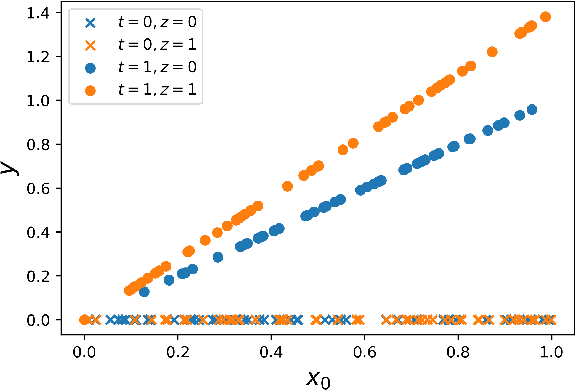
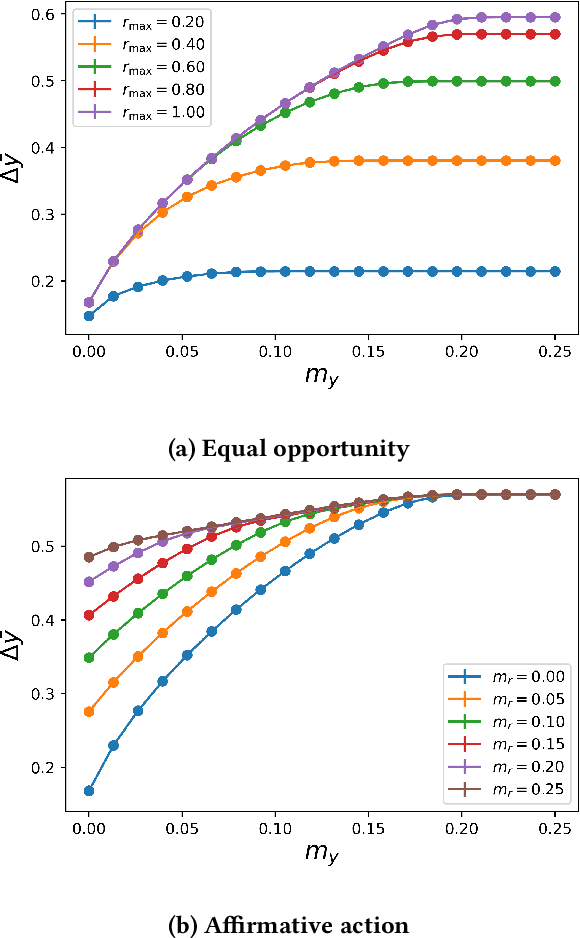
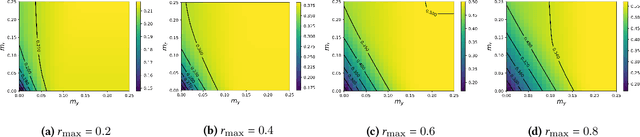
Explicit and implicit bias clouds human judgement, leading to discriminatory treatment of minority groups. A fundamental goal of algorithmic fairness is to avoid the pitfalls in human judgement by learning policies that improve the overall outcomes while providing fair treatment to protected classes. In this paper, we propose a causal framework that learns optimal intervention policies from data subject to fairness constraints. We define two measures of treatment bias and infer best treatment assignment that minimizes the bias while optimizing overall outcome. We demonstrate that there is a dilemma of balancing fairness and overall benefit; however, allowing preferential treatment to protected classes in certain circumstances (affirmative action) can dramatically improve the overall benefit while also preserving fairness. We apply our framework to data containing student outcomes on standardized tests and show how it can be used to design real-world policies that fairly improve student test scores. Our framework provides a principled way to learn fair treatment policies in real-world settings.