 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge#EpiTwitter: Public Health Messaging During the COVID-19 Pandemic
Jun 04, 2024



Effective communication during health crises is critical, with social media serving as a key platform for public health experts (PHEs) to engage with the public. However, it also amplifies pseudo-experts promoting contrarian views. Despite its importance, the role of emotional and moral language in PHEs' communication during COVID-19 remains under explored. This study examines how PHEs and pseudo-experts communicated on Twitter during the pandemic, focusing on emotional and moral language and their engagement with political elites. Analyzing tweets from 489 PHEs and 356 pseudo-experts from January 2020 to January 2021, alongside public responses, we identified key priorities and differences in messaging strategy. PHEs prioritize masking, healthcare, education, and vaccines, using positive emotional language like optimism. In contrast, pseudo-experts discuss therapeutics and lockdowns more frequently, employing negative emotions like pessimism and disgust. Negative emotional and moral language tends to drive engagement, but positive language from PHEs fosters positivity in public responses. PHEs exhibit liberal partisanship, expressing more positivity towards liberals and negativity towards conservative elites, while pseudo-experts show conservative partisanship. These findings shed light on the polarization of COVID-19 discourse and underscore the importance of strategic use of emotional and moral language by experts to mitigate polarization and enhance public trust.
Does Geo-co-location Matter? A Case Study of Public Health Conversations during COVID-19
May 28, 2024Social media platforms like Twitter (now X) have been pivotal in information dissemination and public engagement, especially during COVID-19. A key goal for public health experts was to encourage prosocial behavior that could impact local outcomes such as masking and social distancing. Given the importance of local news and guidance during COVID-19, the objective of our research is to analyze the effect of localized engagement, on social media conversations. This study examines the impact of geographic co-location, as a proxy for localized engagement between public health experts (PHEs) and the public, on social media. We analyze a Twitter conversation dataset from January 2020 to November 2021, comprising over 19 K tweets from nearly five hundred PHEs, along with approximately 800 K replies from 350 K participants. Our findings reveal that geo-co-location is associated with higher engagement rates, especially in conversations on topics including masking, lockdowns, and education, and in conversations with academic and medical professionals. Lexical features associated with emotion and personal experiences were more common in geo-co-located contexts. This research provides insights into how geographic co-location influences social media engagement and can inform strategies to improve public health messaging.
Predicting the Behavior of Dealers in Over-The-Counter Corporate Bond Markets
Mar 12, 2021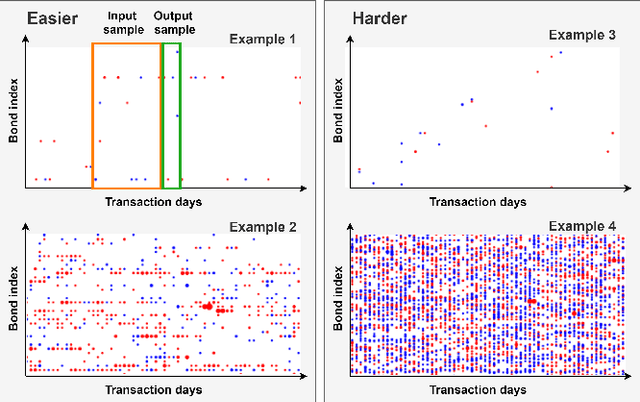
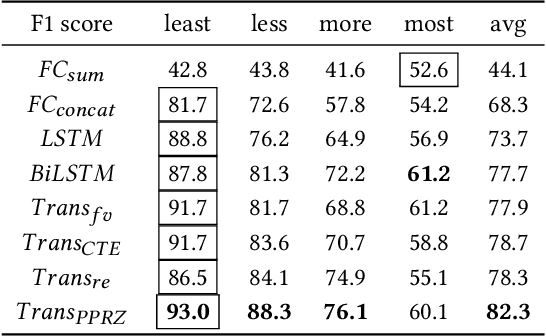

Trading in Over-The-Counter (OTC) markets is facilitated by broker-dealers, in comparison to public exchanges, e.g., the New York Stock Exchange (NYSE). Dealers play an important role in stabilizing prices and providing liquidity in OTC markets. We apply machine learning methods to model and predict the trading behavior of OTC dealers for US corporate bonds. We create sequences of daily historical transaction reports for each dealer over a vocabulary of US corporate bonds. Using this history of dealer activity, we predict the future trading decisions of the dealer. We consider a range of neural network-based prediction models. We propose an extension, the Pointwise-Product ReZero (PPRZ) Transformer model, and demonstrate the improved performance of our model. We show that individual history provides the best predictive model for the most active dealers. For less active dealers, a collective model provides improved performance. Further, clustering dealers based on their similarity can improve performance. Finally, prediction accuracy varies based on the activity level of both the bond and the dealer.
Modeling Complex Financial Products
Feb 03, 2021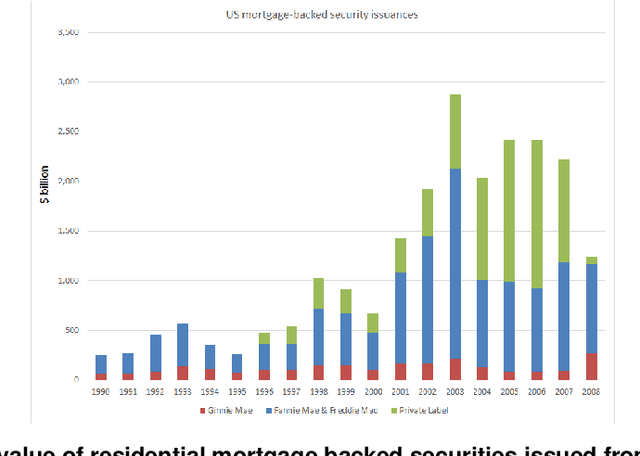
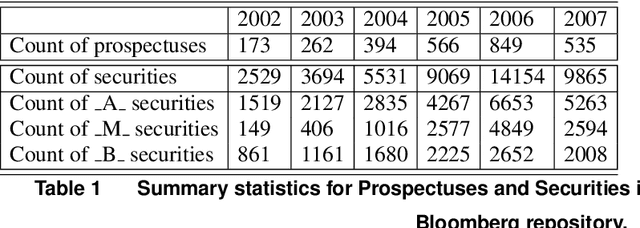
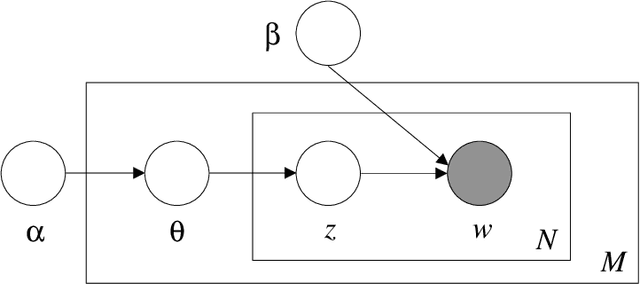
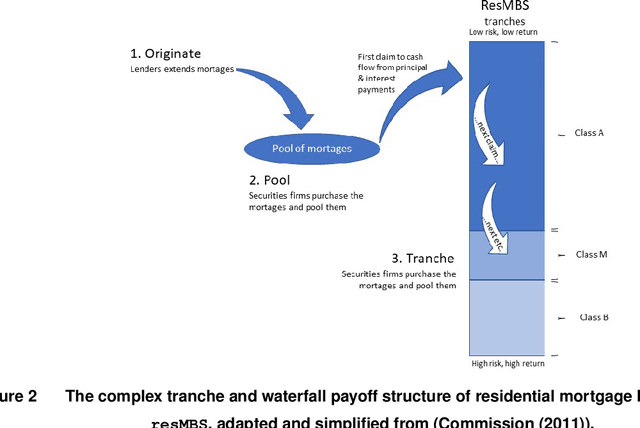
The objective of this paper is to explore how financial big data and machine learning methods can be applied to model and understand complex financial products. We focus on residential mortgage backed securities, resMBS, that were at the heart of the 2008 US financial crisis. The securities are contained within a prospectus and have a complex payoff structure. Multiple financial institutions form a supply chain to create the prospectuses. We provide insight into the performance of the resMBS securities through a series of increasingly complex models. First, models at the security level directly identify salient features of resMBS securities that impact their performance. Second, we extend the model to include prospectus level features. We are the first to demonstrate that the composition of the prospectus is associated with the performance of securities. Finally, to develop a deeper understanding of the role of the supply chain, we use unsupervised probabilistic methods, in particular, dynamic topics models (DTM), to understand community formation and temporal evolution along the chain. A comprehensive model provides insight into the impact of DTM communities on the issuance and evolution of prospectuses, and eventually the performance of resMBS securities.
Non-negative Factorization of the Occurrence Tensor from Financial Contracts
Dec 10, 2016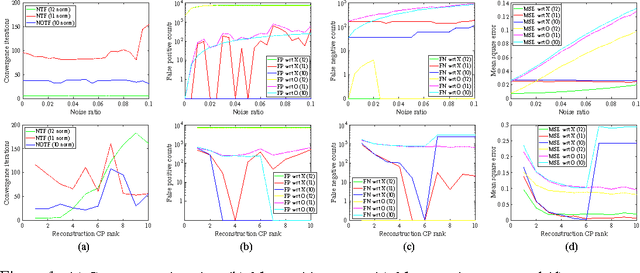
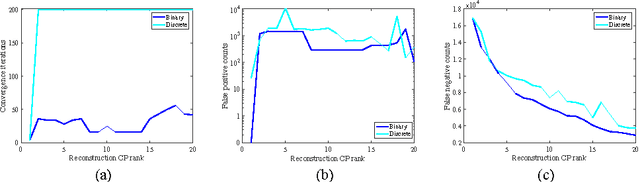
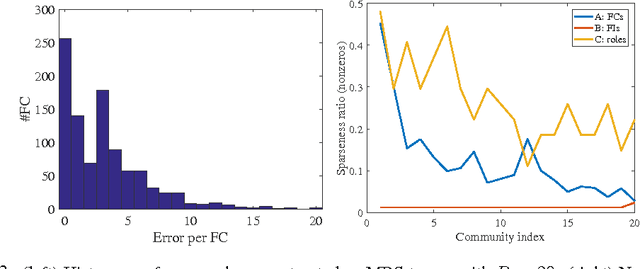
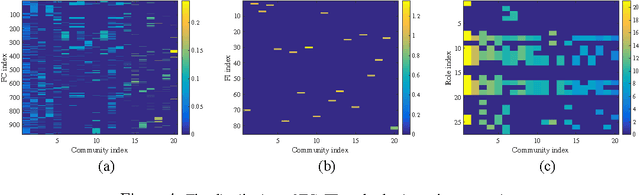
We propose an algorithm for the non-negative factorization of an occurrence tensor built from heterogeneous networks. We use l0 norm to model sparse errors over discrete values (occurrences), and use decomposed factors to model the embedded groups of nodes. An efficient splitting method is developed to optimize the nonconvex and nonsmooth objective. We study both synthetic problems and a new dataset built from financial documents, resMBS.
Exploiting Lists of Names for Named Entity Identification of Financial Institutions from Unstructured Documents
Jun 07, 2016
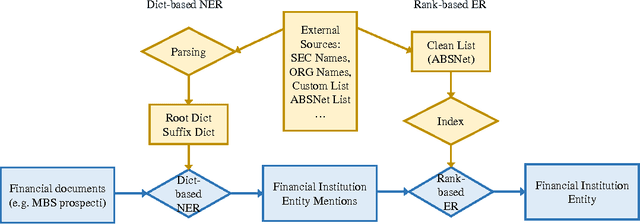
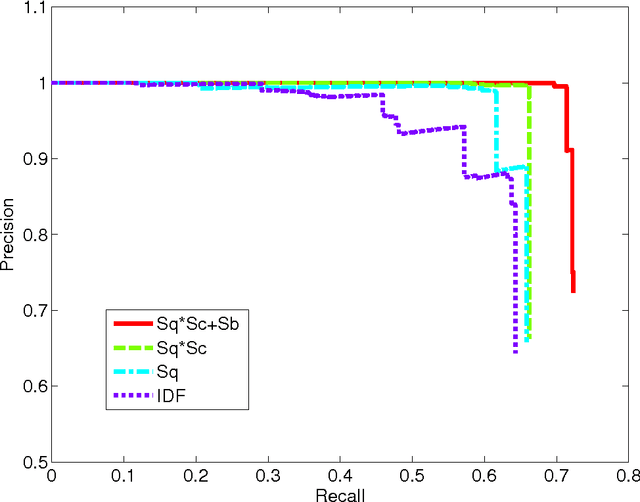
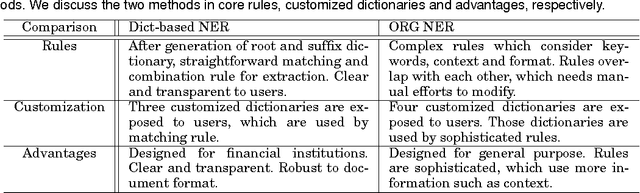
There is a wealth of information about financial systems that is embedded in document collections. In this paper, we focus on a specialized text extraction task for this domain. The objective is to extract mentions of names of financial institutions, or FI names, from financial prospectus documents, and to identify the corresponding real world entities, e.g., by matching against a corpus of such entities. The tasks are Named Entity Recognition (NER) and Entity Resolution (ER); both are well studied in the literature. Our contribution is to develop a rule-based approach that will exploit lists of FI names for both tasks; our solution is labeled Dict-based NER and Rank-based ER. Since the FI names are typically represented by a root, and a suffix that modifies the root, we use these lists of FI names to create specialized root and suffix dictionaries. To evaluate the effectiveness of our specialized solution for extracting FI names, we compare Dict-based NER with a general purpose rule-based NER solution, ORG NER. Our evaluation highlights the benefits and limitations of specialized versus general purpose approaches, and presents additional suggestions for tuning and customization for FI name extraction. To our knowledge, our proposed solutions, Dict-based NER and Rank-based ER, and the root and suffix dictionaries, are the first attempt to exploit specialized knowledge, i.e., lists of FI names, for rule-based NER and ER.