 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICDAR 2021 Competition on Scientific Literature Parsing
Jun 08, 2021
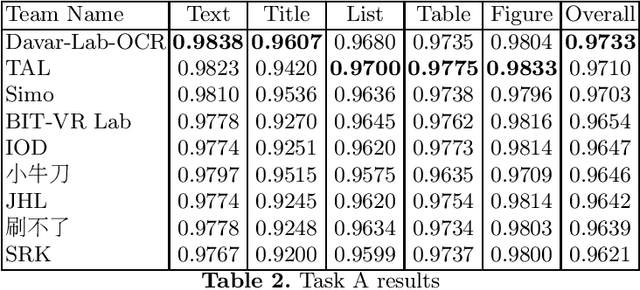
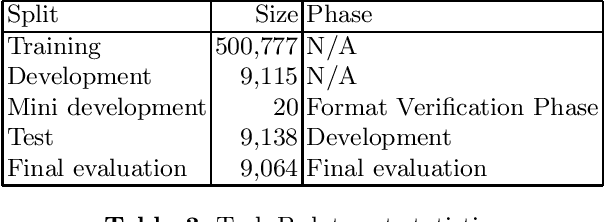
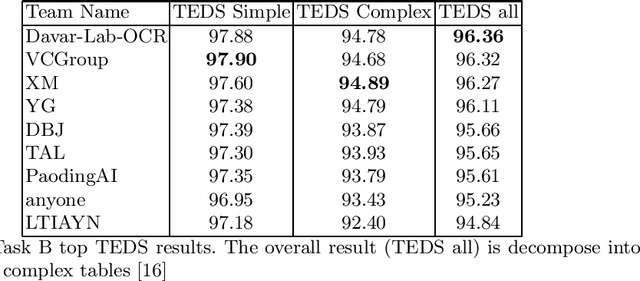
Scientific literature contain important information related to cutting-edge innovations in diverse domains. Advances in natural language processing have been driving the fast development in automated information extraction from scientific literature. However, scientific literature is often available in unstructured PDF format. While PDF is great for preserving basic visual elements, such as characters, lines, shapes, etc., on a canvas for presentation to humans, automatic processing of the PDF format by machines presents many challenges. With over 2.5 trillion PDF documents in existence, these issues are prevalent in many other important application domains as well. Our ICDAR 2021 Scientific Literature Parsing Competition (ICDAR2021-SLP) aims to drive the advances specifically in document understanding. ICDAR2021-SLP leverages the PubLayNet and PubTabNet datasets, which provide hundreds of thousands of training and evaluation examples. In Task A, Document Layout Recognition, submissions with the highest performance combine object detection and specialised solutions for the different categories. In Task B, Table Recognition, top submissions rely on methods to identify table components and post-processing methods to generate the table structure and content. Results from both tasks show an impressive performance and opens the possibility for high performance practical applications.
TableLab: An Interactive Table Extraction System with Adaptive Deep Learning
Feb 16, 2021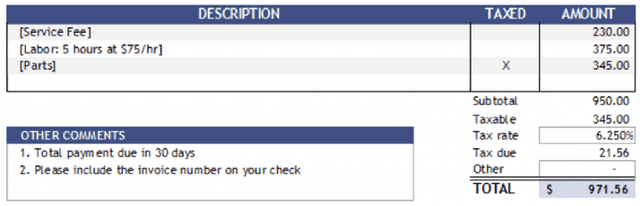
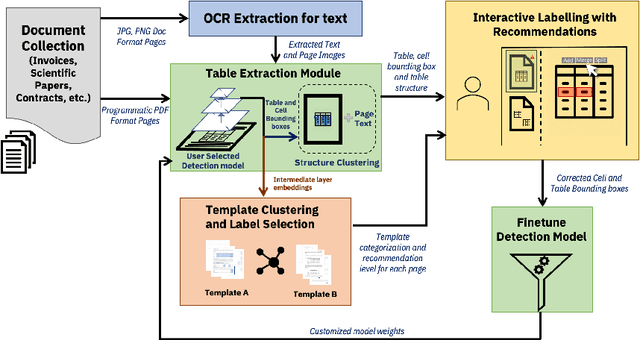

Table extraction from PDF and image documents is a ubiquitous task in the real-world. Perfect extraction quality is difficult to achieve with one single out-of-box model due to (1) the wide variety of table styles, (2) the lack of training data representing this variety and (3) the inherent ambiguity and subjectivity of table definitions between end-users. Meanwhile, building customized models from scratch can be difficult due to the expensive nature of annotating table data. We attempt to solve these challenges with TableLab by providing a system where users and models seamlessly work together to quickly customize high-quality extraction models with a few labelled examples for the user's document collection, which contains pages with tables. Given an input document collection, TableLab first detects tables with similar structures (templates) by clustering embeddings from the extraction model. Document collections often contain tables created with a limited set of templates or similar structures. It then selects a few representative table examples already extracted with a pre-trained base deep learning model. Via an easy-to-use user interface, users provide feedback to these selections without necessarily having to identify every single error. TableLab then applies such feedback to finetune the pre-trained model and returns the results of the finetuned model back to the user. The user can choose to repeat this process iteratively until obtaining a customized model with satisfactory performance.
* Accepted at IUI'21
Exploiting Lists of Names for Named Entity Identification of Financial Institutions from Unstructured Documents
Jun 07, 2016
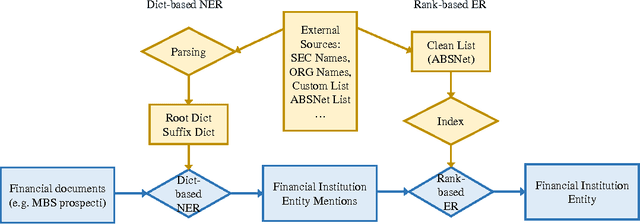
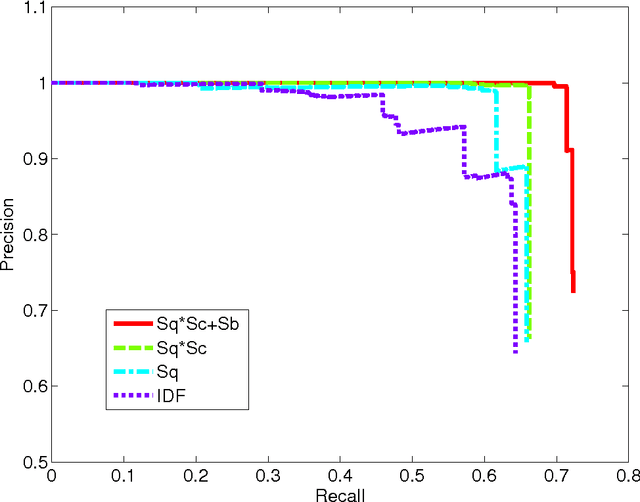
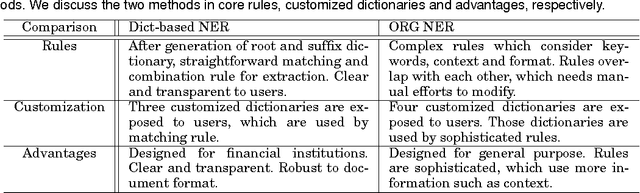
There is a wealth of information about financial systems that is embedded in document collections. In this paper, we focus on a specialized text extraction task for this domain. The objective is to extract mentions of names of financial institutions, or FI names, from financial prospectus documents, and to identify the corresponding real world entities, e.g., by matching against a corpus of such entities. The tasks are Named Entity Recognition (NER) and Entity Resolution (ER); both are well studied in the literature. Our contribution is to develop a rule-based approach that will exploit lists of FI names for both tasks; our solution is labeled Dict-based NER and Rank-based ER. Since the FI names are typically represented by a root, and a suffix that modifies the root, we use these lists of FI names to create specialized root and suffix dictionaries. To evaluate the effectiveness of our specialized solution for extracting FI names, we compare Dict-based NER with a general purpose rule-based NER solution, ORG NER. Our evaluation highlights the benefits and limitations of specialized versus general purpose approaches, and presents additional suggestions for tuning and customization for FI name extraction. To our knowledge, our proposed solutions, Dict-based NER and Rank-based ER, and the root and suffix dictionaries, are the first attempt to exploit specialized knowledge, i.e., lists of FI names, for rule-based NER and ER.