 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableLab: An Interactive Table Extraction System with Adaptive Deep Learning
Feb 16, 2021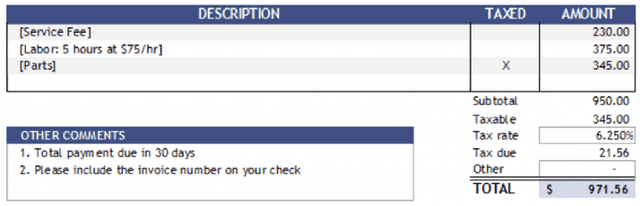
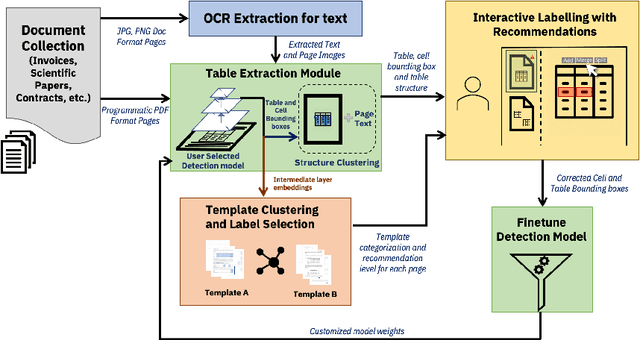

Table extraction from PDF and image documents is a ubiquitous task in the real-world. Perfect extraction quality is difficult to achieve with one single out-of-box model due to (1) the wide variety of table styles, (2) the lack of training data representing this variety and (3) the inherent ambiguity and subjectivity of table definitions between end-users. Meanwhile, building customized models from scratch can be difficult due to the expensive nature of annotating table data. We attempt to solve these challenges with TableLab by providing a system where users and models seamlessly work together to quickly customize high-quality extraction models with a few labelled examples for the user's document collection, which contains pages with tables. Given an input document collection, TableLab first detects tables with similar structures (templates) by clustering embeddings from the extraction model. Document collections often contain tables created with a limited set of templates or similar structures. It then selects a few representative table examples already extracted with a pre-trained base deep learning model. Via an easy-to-use user interface, users provide feedback to these selections without necessarily having to identify every single error. TableLab then applies such feedback to finetune the pre-trained model and returns the results of the finetuned model back to the user. The user can choose to repeat this process iteratively until obtaining a customized model with satisfactory performance.
* Accepted at IUI'21
Global Table Extractor : A Framework for Joint Table Identification and Cell Structure Recognition Using Visual Context
May 01, 2020
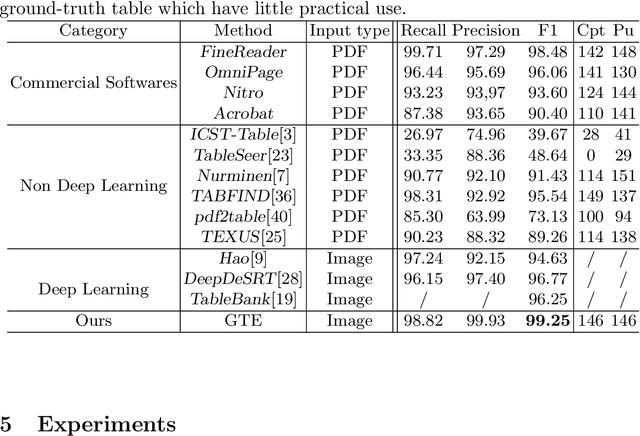
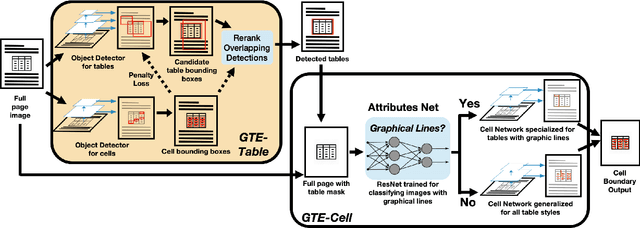

Documents are often the format of choice for knowledge sharing and preservation in business and science. Much of the critical data are captured in tables. Unfortunately, most documents are stored and distributed in PDF or scanned images, which fail to preserve table formatting. Recent vision-based deep learning approaches have been proposed to address this gap, but most still cannot achieve state-of-the-art results. We present Global Table Extractor (GTE), a vision-guided systematic framework for joint table detection and cell structured recognition, which could be built on top of any object detection model. With GTE-Table, we invent a new penalty based on the natural cell containment constraint of tables to train our table network aided by cell location predictions. GTE-Cell is a new hierarchical cell detection network that leverages table styles. Further, we design a method to automatically label table and cell structure in existing documents to cheaply create a large corpus of training and test data. We use this to create SD-tables and SEC-tables, real world and complex scientific and financial datasets with detailed table structure annotations to help train and test structure recognition. Our deep learning framework surpasses previous state-of-the-art results on the ICDAR 2013 table competition test dataset in both table detection and cell structure recognition, with a significant 6.8% improvement in the full table extraction system. We also show more than 30% improvement in cell structure recognition F1-score when compared to a vanilla RetinaNet object detection model in our out-of-domain financial dataset (SEC-Tables).
AJILE Movement Prediction: Multimodal Deep Learning for Natural Human Neural Recordings and Video
Mar 01, 2018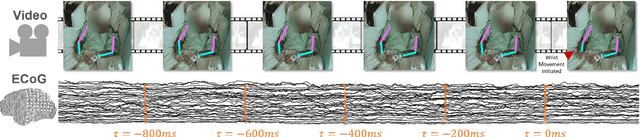
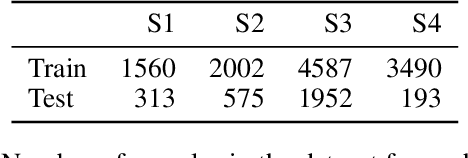
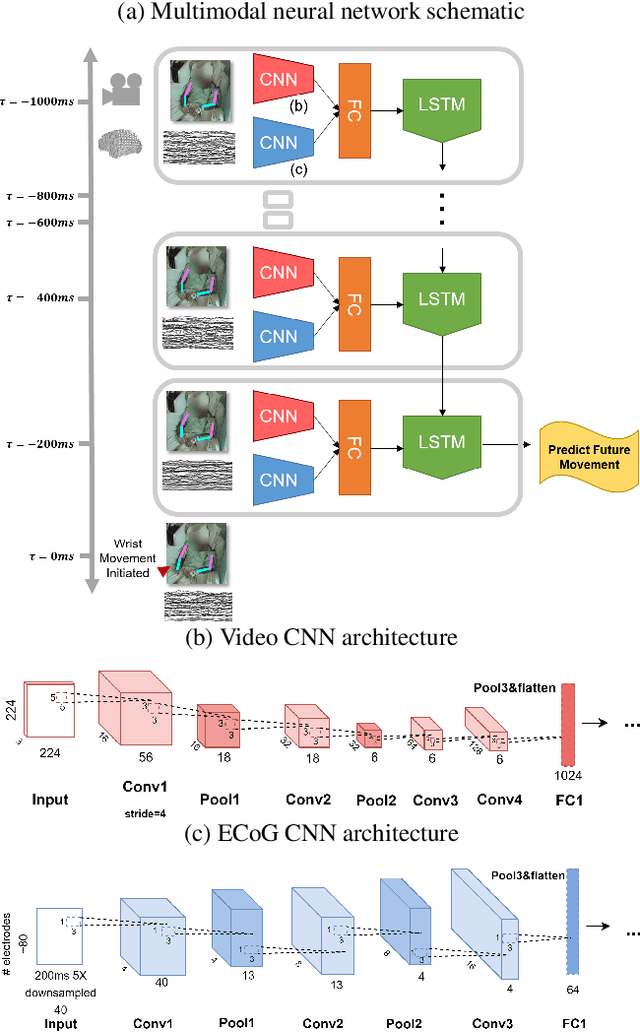
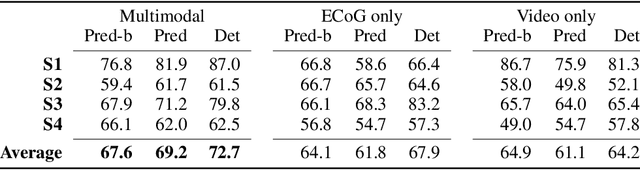
Developing useful interfaces between brains and machines is a grand challenge of neuroengineering. An effective interface has the capacity to not only interpret neural signals, but predict the intentions of the human to perform an action in the near future; prediction is made even more challenging outside well-controlled laboratory experiments. This paper describes our approach to detect and to predict natural human arm movements in the future, a key challenge in brain computer interfacing that has never before been attempted. We introduce the novel Annotated Joints in Long-term ECoG (AJILE) dataset; AJILE includes automatically annotated poses of 7 upper body joints for four human subjects over 670 total hours (more than 72 million frames), along with the corresponding simultaneously acquired intracranial neural recordings. The size and scope of AJILE greatly exceeds all previous datasets with movements and electrocorticography (ECoG), making it possible to take a deep learning approach to movement prediction. We propose a multimodal model that combines deep convolutional neural networks (CNN) with long short-term memory (LSTM) blocks, leveraging both ECoG and video modalities. We demonstrate that our models are able to detect movements and predict future movements up to 800 msec before movement initiation. Further, our multimodal movement prediction models exhibit resilience to simulated ablation of input neural signals. We believe a multimodal approach to natural neural decoding that takes context into account is critical in advancing bioelectronic technologies and human neuroscience.