 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialMem: Unified 3D Memory with Metric Anchoring and Fast Retrieval
Jan 21, 2026We present SpatialMem, a memory-centric system that unifies 3D geometry, semantics, and language into a single, queryable representation. Starting from casually captured egocentric RGB video, SpatialMem reconstructs metrically scaled indoor environments, detects structural 3D anchors (walls, doors, windows) as the first-layer scaffold, and populates a hierarchical memory with open-vocabulary object nodes -- linking evidence patches, visual embeddings, and two-layer textual descriptions to 3D coordinates -- for compact storage and fast retrieval. This design enables interpretable reasoning over spatial relations (e.g., distance, direction, visibility) and supports downstream tasks such as language-guided navigation and object retrieval without specialized sensors. Experiments across three real-life indoor scenes demonstrate that SpatialMem maintains strong anchor-description-level navigation completion and hierarchical retrieval accuracy under increasing clutter and occlusion, offering an efficient and extensible framework for embodied spatial intelligence.
X-LeBench: A Benchmark for Extremely Long Egocentric Video Understanding
Jan 12, 2025Long-form egocentric video understanding provides rich contextual information and unique insights into long-term human behaviors, holding significant potential for applications in embodied intelligence, long-term activity analysis, and personalized assistive technologies. However, existing benchmark datasets primarily focus on single, short-duration videos or moderately long videos up to dozens of minutes, leaving a substantial gap in evaluating extensive, ultra-long egocentric video recordings. To address this, we introduce X-LeBench, a novel benchmark dataset specifically crafted for evaluating tasks on extremely long egocentric video recordings. Leveraging the advanced text processing capabilities of large language models (LLMs), X-LeBench develops a life-logging simulation pipeline that produces realistic, coherent daily plans aligned with real-world video data. This approach enables the flexible integration of synthetic daily plans with real-world footage from Ego4D-a massive-scale egocentric video dataset covers a wide range of daily life scenarios-resulting in 432 simulated video life logs that mirror realistic daily activities in contextually rich scenarios. The video life-log durations span from 23 minutes to 16.4 hours. The evaluation of several baseline systems and multimodal large language models (MLLMs) reveals their poor performance across the board, highlighting the inherent challenges of long-form egocentric video understanding and underscoring the need for more advanced models.
CULTURE3D: Cultural Landmarks and Terrain Dataset for 3D Applications
Jan 12, 2025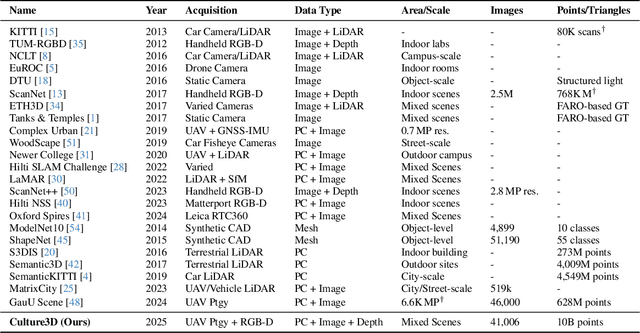
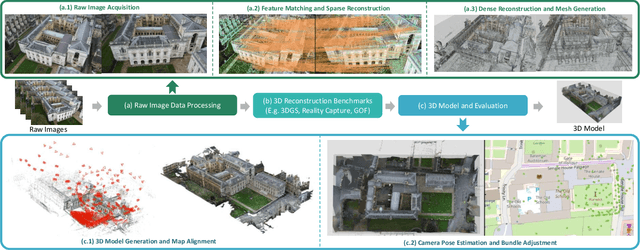
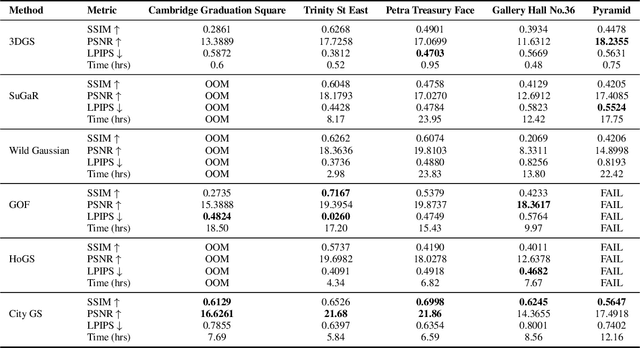

In this paper, we present a large-scale fine-grained dataset using high-resolution images captured from locations worldwide. Compared to existing datasets, our dataset offers a significantly larger size and includes a higher level of detail, making it uniquely suited for fine-grained 3D applications. Notably, our dataset is built using drone-captured aerial imagery, which provides a more accurate perspective for capturing real-world site layouts and architectural structures. By reconstructing environments with these detailed images, our dataset supports applications such as the COLMAP format for Gaussian Splatting and the Structure-from-Motion (SfM) method. It is compatible with widely-used techniques including SLAM, Multi-View Stereo, and Neural Radiance Fields (NeRF), enabling accurate 3D reconstructions and point clouds. This makes it a benchmark for reconstruction and segmentation tasks. The dataset enables seamless integration with multi-modal data, supporting a range of 3D applications, from architectural reconstruction to virtual tourism. Its flexibility promotes innovation, facilitating breakthroughs in 3D modeling and analysis.
Epsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
Building K-Anonymous User Cohorts with\\ Consecutive Consistent Weighted Sampling (CCWS)
Apr 26, 2023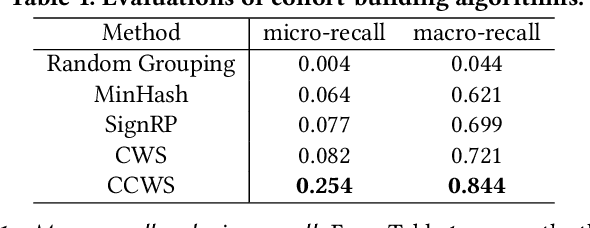
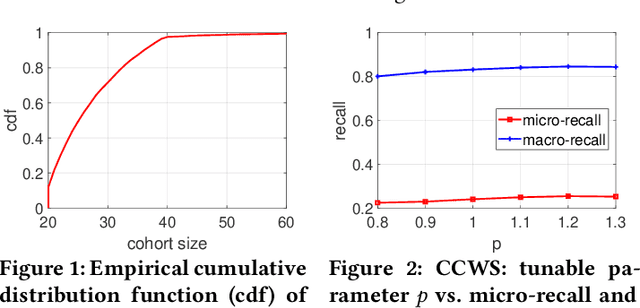
To retrieve personalized campaigns and creatives while protecting user privacy, digital advertising is shifting from member-based identity to cohort-based identity. Under such identity regime, an accurate and efficient cohort building algorithm is desired to group users with similar characteristics. In this paper, we propose a scalable $K$-anonymous cohort building algorithm called {\em consecutive consistent weighted sampling} (CCWS). The proposed method combines the spirit of the ($p$-powered) consistent weighted sampling and hierarchical clustering, so that the $K$-anonymity is ensured by enforcing a lower bound on the size of cohorts. Evaluations on a LinkedIn dataset consisting of $>70$M users and ads campaigns demonstrate that CCWS achieves substantial improvements over several hashing-based methods including sign random projections (SignRP), minwise hashing (MinHash), as well as the vanilla CWS.
Network Report: A Structured Description for Network Datasets
Jun 08, 2022
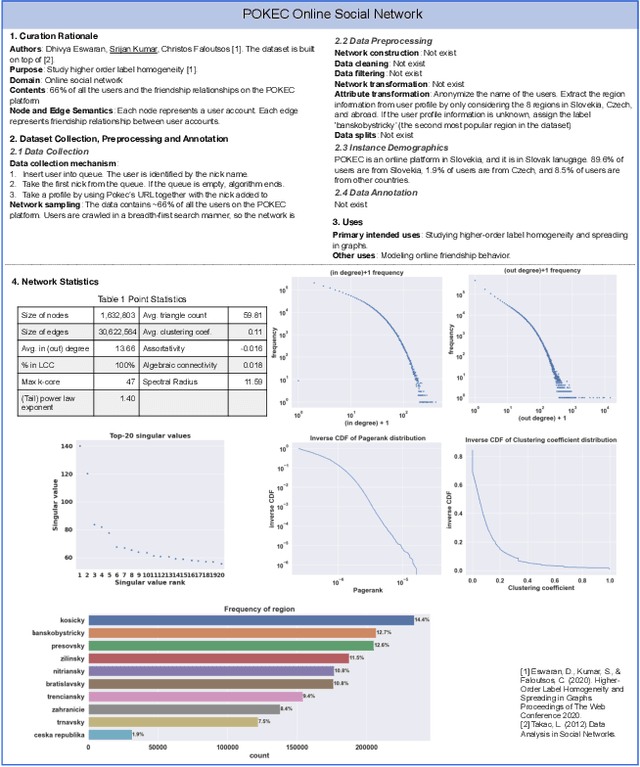

The rapid development of network science and technologies depends on shareable datasets. Currently, there is no standard practice for reporting and sharing network datasets. Some network dataset providers only share links, while others provide some contexts or basic statistics. As a result, critical information may be unintentionally dropped, and network dataset consumers may misunderstand or overlook critical aspects. Inappropriately using a network dataset can lead to severe consequences (e.g., discrimination) especially when machine learning models on networks are deployed in high-stake domains. Challenges arise as networks are often used across different domains (e.g., network science, physics, etc) and have complex structures. To facilitate the communication between network dataset providers and consumers, we propose network report. A network report is a structured description that summarizes and contextualizes a network dataset. Network report extends the idea of dataset reports (e.g., Datasheets for Datasets) from prior work with network-specific descriptions of the non-i.i.d. nature, demographic information, network characteristics, etc. We hope network reports encourage transparency and accountability in network research and development across different fields.
Mining Persistent Activity in Continually Evolving Networks
Jun 27, 2020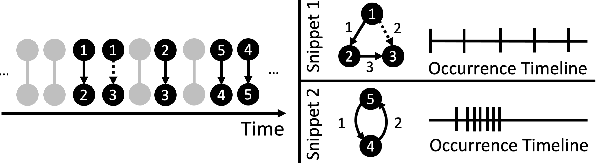

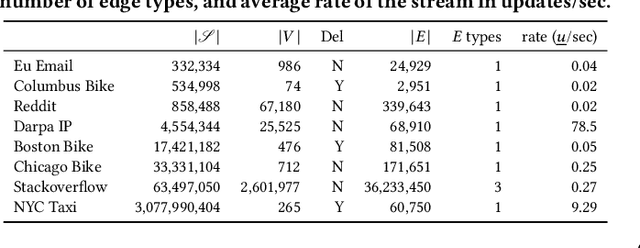
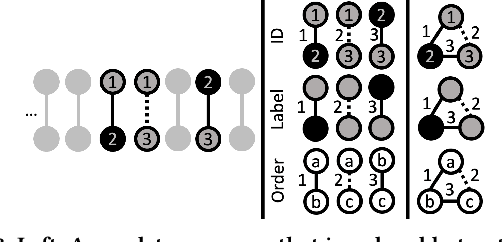
Frequent pattern mining is a key area of study that gives insights into the structure and dynamics of evolving networks, such as social or road networks. However, not only does a network evolve, but often the way that it evolves, itself evolves. Thus, knowing, in addition to patterns' frequencies, for how long and how regularly they have occurred---i.e., their persistence---can add to our understanding of evolving networks. In this work, we propose the problem of mining activity that persists through time in continually evolving networks---i.e., activity that repeatedly and consistently occurs. We extend the notion of temporal motifs to capture activity among specific nodes, in what we call activity snippets, which are small sequences of edge-updates that reoccur. We propose axioms and properties that a measure of persistence should satisfy, and develop such a persistence measure. We also propose PENminer, an efficient framework for mining activity snippets' Persistence in Evolving Networks, and design both offline and streaming algorithms. We apply PENminer to numerous real, large-scale evolving networks and edge streams, and find activity that is surprisingly regular over a long period of time, but too infrequent to be discovered by aggregate count alone, and bursts of activity exposed by their lack of persistence. Our findings with PENminer include neighborhoods in NYC where taxi traffic persisted through Hurricane Sandy, the opening of new bike-stations, characteristics of social network users, and more. Moreover, we use PENminer towards identifying anomalies in multiple networks, outperforming baselines at identifying subtle anomalies by 9.8-48% in AUC.
COVID-19 Public Opinion and Emotion Monitoring System Based on Time Series Thermal New Word Mining
May 23, 2020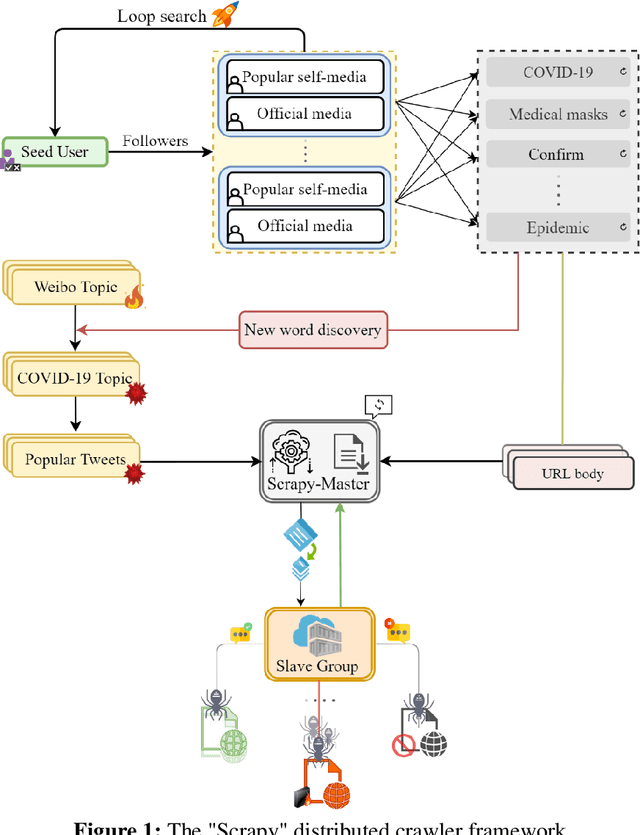
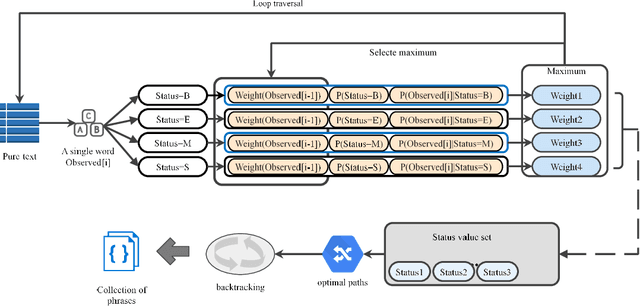
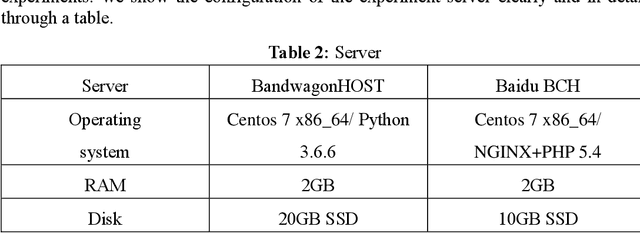
With the spread and development of new epidemics, it is of great reference value to identify the changing trends of epidemics in public emotions. We designed and implemented the COVID-19 public opinion monitoring system based on time series thermal new word mining. A new word structure discovery scheme based on the timing explosion of network topics and a Chinese sentiment analysis method for the COVID-19 public opinion environment is proposed. Establish a "Scrapy-Redis-Bloomfilter" distributed crawler framework to collect data. The system can judge the positive and negative emotions of the reviewer based on the comments, and can also reflect the depth of the seven emotions such as Hopeful, Happy, and Depressed. Finally, we improved the sentiment discriminant model of this system and compared the sentiment discriminant error of COVID-19 related comments with the Jiagu deep learning model. The results show that our model has better generalization ability and smaller discriminant error. We designed a large data visualization screen, which can clearly show the trend of public emotions, the proportion of various emotion categories, keywords, hot topics, etc., and fully and intuitively reflect the development of public opinion.
Global Table Extractor : A Framework for Joint Table Identification and Cell Structure Recognition Using Visual Context
May 01, 2020
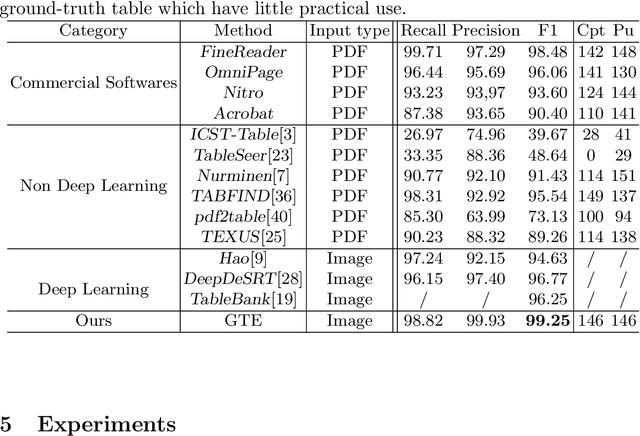
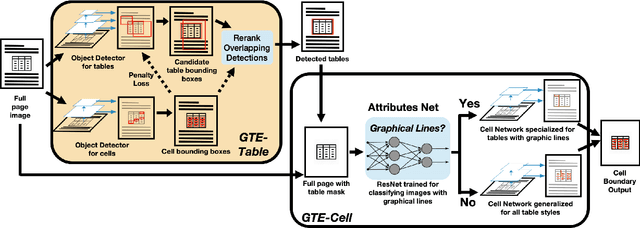

Documents are often the format of choice for knowledge sharing and preservation in business and science. Much of the critical data are captured in tables. Unfortunately, most documents are stored and distributed in PDF or scanned images, which fail to preserve table formatting. Recent vision-based deep learning approaches have been proposed to address this gap, but most still cannot achieve state-of-the-art results. We present Global Table Extractor (GTE), a vision-guided systematic framework for joint table detection and cell structured recognition, which could be built on top of any object detection model. With GTE-Table, we invent a new penalty based on the natural cell containment constraint of tables to train our table network aided by cell location predictions. GTE-Cell is a new hierarchical cell detection network that leverages table styles. Further, we design a method to automatically label table and cell structure in existing documents to cheaply create a large corpus of training and test data. We use this to create SD-tables and SEC-tables, real world and complex scientific and financial datasets with detailed table structure annotations to help train and test structure recognition. Our deep learning framework surpasses previous state-of-the-art results on the ICDAR 2013 table competition test dataset in both table detection and cell structure recognition, with a significant 6.8% improvement in the full table extraction system. We also show more than 30% improvement in cell structure recognition F1-score when compared to a vanilla RetinaNet object detection model in our out-of-domain financial dataset (SEC-Tables).
What is Normal, What is Strange, and What is Missing in a Knowledge Graph: Unified Characterization via Inductive Summarization
Mar 23, 2020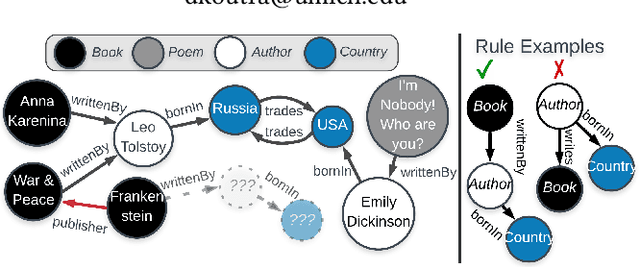


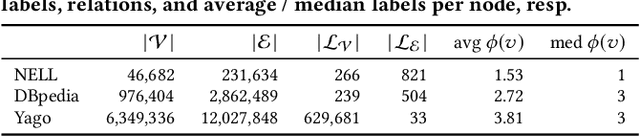
Knowledge graphs (KGs) store highly heterogeneous information about the world in the structure of a graph, and are useful for tasks such as question answering and reasoning. However, they often contain errors and are missing information. Vibrant research in KG refinement has worked to resolve these issues, tailoring techniques to either detect specific types of errors or complete a KG. In this work, we introduce a unified solution to KG characterization by formulating the problem as unsupervised KG summarization with a set of inductive, soft rules, which describe what is normal in a KG, and thus can be used to identify what is abnormal, whether it be strange or missing. Unlike first-order logic rules, our rules are labeled, rooted graphs, i.e., patterns that describe the expected neighborhood around a (seen or unseen) node, based on its type, and information in the KG. Stepping away from the traditional support/confidence-based rule mining techniques, we propose KGist, Knowledge Graph Inductive SummarizaTion, which learns a summary of inductive rules that best compress the KG according to the Minimum Description Length principle---a formulation that we are the first to use in the context of KG rule mining. We apply our rules to three large KGs (NELL, DBpedia, and Yago), and tasks such as compression, various types of error detection, and identification of incomplete information. We show that KGist outperforms task-specific, supervised and unsupervised baselines in error detection and incompleteness identification, (identifying the location of up to 93% of missing entities---over 10% more than baselines), while also being efficient for large knowledge graphs.