 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Greedy and Recursive Search for Morphological Productivity
May 12, 2021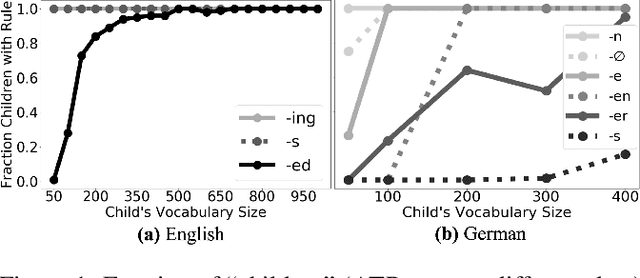
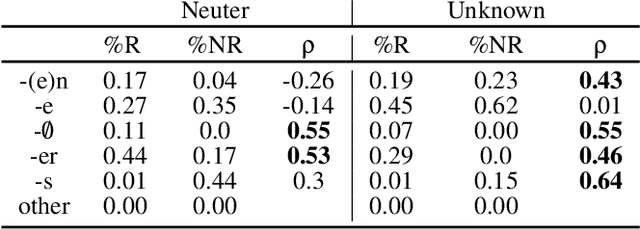
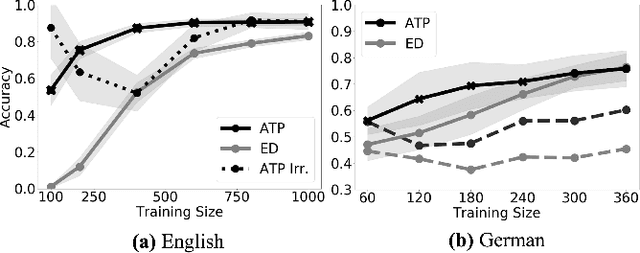
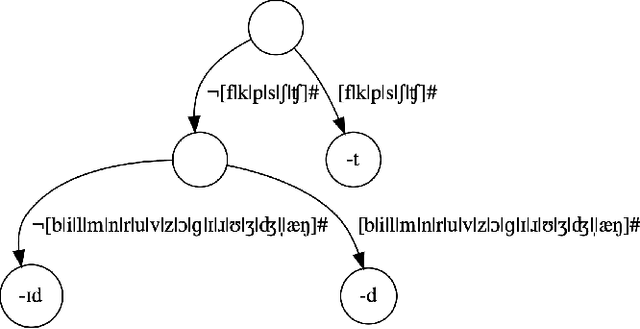
As children acquire the knowledge of their language's morphology, they invariably discover the productive processes that can generalize to new words. Morphological learning is made challenging by the fact that even fully productive rules have exceptions, as in the well-known case of English past tense verbs, which features the -ed rule against the irregular verbs. The Tolerance Principle is a recent proposal that provides a precise threshold of exceptions that a productive rule can withstand. Its empirical application so far, however, requires the researcher to fully specify rules defined over a set of words. We propose a greedy search model that automatically hypothesizes rules and evaluates their productivity over a vocabulary. When the search for broader productivity fails, the model recursively subdivides the vocabulary and continues the search for productivity over narrower rules. Trained on psychologically realistic data from child-directed input, our model displays developmental patterns observed in child morphology acquisition, including the notoriously complex case of German noun pluralization. It also produces responses to nonce words that, despite receiving only a fraction of the training data, are more similar to those of human subjects than current neural network models' responses are.
A Hidden Challenge of Link Prediction: Which Pairs to Check?
Feb 15, 2021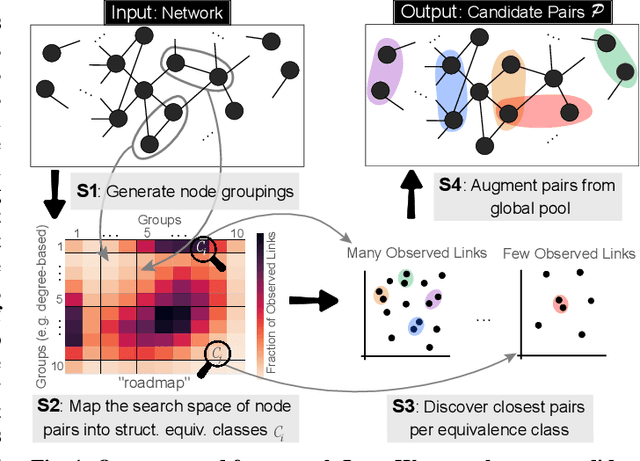
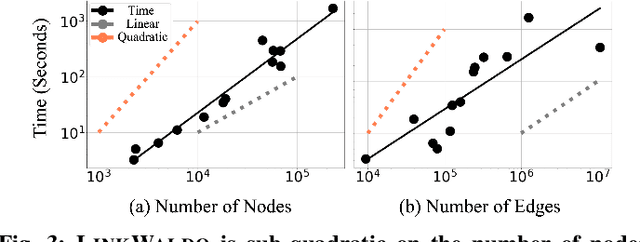

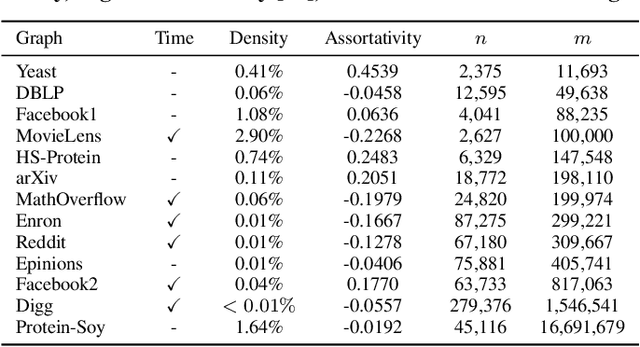
The traditional setup of link prediction in networks assumes that a test set of node pairs, which is usually balanced, is available over which to predict the presence of links. However, in practice, there is no test set: the ground-truth is not known, so the number of possible pairs to predict over is quadratic in the number of nodes in the graph. Moreover, because graphs are sparse, most of these possible pairs will not be links. Thus, link prediction methods, which often rely on proximity-preserving embeddings or heuristic notions of node similarity, face a vast search space, with many pairs that are in close proximity, but that should not be linked. To mitigate this issue, we introduce LinkWaldo, a framework for choosing from this quadratic, massively-skewed search space of node pairs, a concise set of candidate pairs that, in addition to being in close proximity, also structurally resemble the observed edges. This allows it to ignore some high-proximity but low-resemblance pairs, and also identify high-resemblance, lower-proximity pairs. Our framework is built on a model that theoretically combines Stochastic Block Models (SBMs) with node proximity models. The block structure of the SBM maps out where in the search space new links are expected to fall, and the proximity identifies the most plausible links within these blocks, using locality sensitive hashing to avoid expensive exhaustive search. LinkWaldo can use any node representation learning or heuristic definition of proximity, and can generate candidate pairs for any link prediction method, allowing the representation power of current and future methods to be realized for link prediction in practice. We evaluate LinkWaldo on 13 networks across multiple domains, and show that on average it returns candidate sets containing 7-33% more missing and future links than both embedding-based and heuristic baselines' sets.
Mining Persistent Activity in Continually Evolving Networks
Jun 27, 2020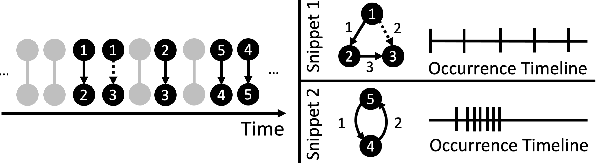

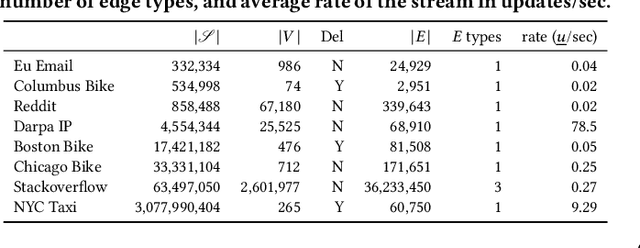
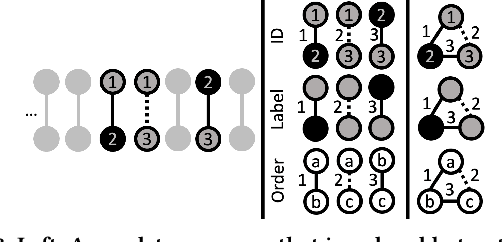
Frequent pattern mining is a key area of study that gives insights into the structure and dynamics of evolving networks, such as social or road networks. However, not only does a network evolve, but often the way that it evolves, itself evolves. Thus, knowing, in addition to patterns' frequencies, for how long and how regularly they have occurred---i.e., their persistence---can add to our understanding of evolving networks. In this work, we propose the problem of mining activity that persists through time in continually evolving networks---i.e., activity that repeatedly and consistently occurs. We extend the notion of temporal motifs to capture activity among specific nodes, in what we call activity snippets, which are small sequences of edge-updates that reoccur. We propose axioms and properties that a measure of persistence should satisfy, and develop such a persistence measure. We also propose PENminer, an efficient framework for mining activity snippets' Persistence in Evolving Networks, and design both offline and streaming algorithms. We apply PENminer to numerous real, large-scale evolving networks and edge streams, and find activity that is surprisingly regular over a long period of time, but too infrequent to be discovered by aggregate count alone, and bursts of activity exposed by their lack of persistence. Our findings with PENminer include neighborhoods in NYC where taxi traffic persisted through Hurricane Sandy, the opening of new bike-stations, characteristics of social network users, and more. Moreover, we use PENminer towards identifying anomalies in multiple networks, outperforming baselines at identifying subtle anomalies by 9.8-48% in AUC.
What is Normal, What is Strange, and What is Missing in a Knowledge Graph: Unified Characterization via Inductive Summarization
Mar 23, 2020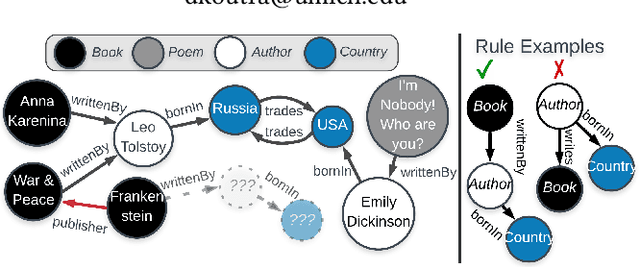


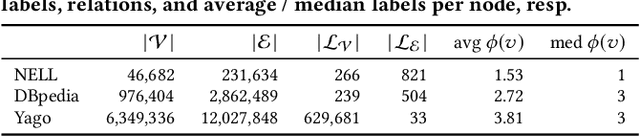
Knowledge graphs (KGs) store highly heterogeneous information about the world in the structure of a graph, and are useful for tasks such as question answering and reasoning. However, they often contain errors and are missing information. Vibrant research in KG refinement has worked to resolve these issues, tailoring techniques to either detect specific types of errors or complete a KG. In this work, we introduce a unified solution to KG characterization by formulating the problem as unsupervised KG summarization with a set of inductive, soft rules, which describe what is normal in a KG, and thus can be used to identify what is abnormal, whether it be strange or missing. Unlike first-order logic rules, our rules are labeled, rooted graphs, i.e., patterns that describe the expected neighborhood around a (seen or unseen) node, based on its type, and information in the KG. Stepping away from the traditional support/confidence-based rule mining techniques, we propose KGist, Knowledge Graph Inductive SummarizaTion, which learns a summary of inductive rules that best compress the KG according to the Minimum Description Length principle---a formulation that we are the first to use in the context of KG rule mining. We apply our rules to three large KGs (NELL, DBpedia, and Yago), and tasks such as compression, various types of error detection, and identification of incomplete information. We show that KGist outperforms task-specific, supervised and unsupervised baselines in error detection and incompleteness identification, (identifying the location of up to 93% of missing entities---over 10% more than baselines), while also being efficient for large knowledge graphs.