 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly Ensemble Pruning in Evolving Data Streams
Sep 15, 2021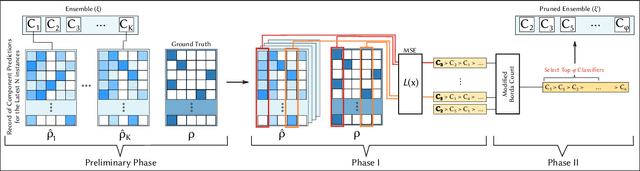
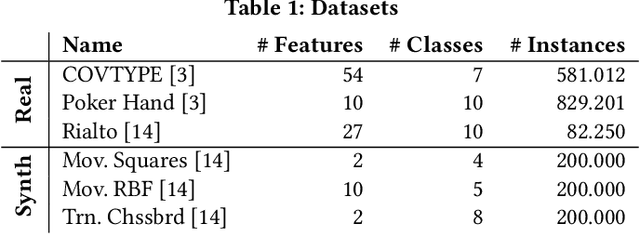
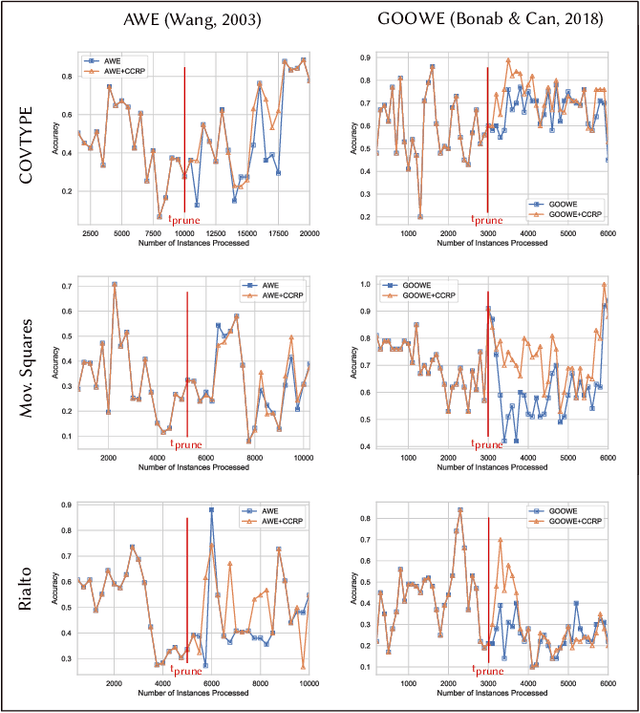
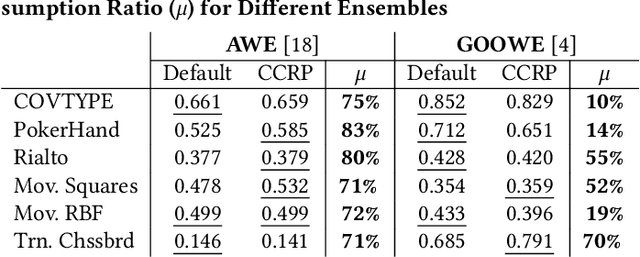
Ensemble pruning is the process of selecting a subset of componentclassifiers from an ensemble which performs at least as well as theoriginal ensemble while reducing storage and computational costs.Ensemble pruning in data streams is a largely unexplored area ofresearch. It requires analysis of ensemble components as they arerunning on the stream, and differentiation of useful classifiers fromredundant ones. We present CCRP, an on-the-fly ensemble prun-ing method for multi-class data stream classification empoweredby an imbalance-aware fusion of class-wise component rankings.CCRP aims that the resulting pruned ensemble contains the bestperforming classifier for each target class and hence, reduces the ef-fects of class imbalance. The conducted experiments on real-worldand synthetic data streams demonstrate that different types of en-sembles that integrate CCRP as their pruning scheme consistentlyyield on par or superior performance with 20% to 90% less averagememory consumption. Lastly, we validate the proposed pruningscheme by comparing our approach against pruning schemes basedon ensemble weights and basic rank fusion methods.
A Hidden Challenge of Link Prediction: Which Pairs to Check?
Feb 15, 2021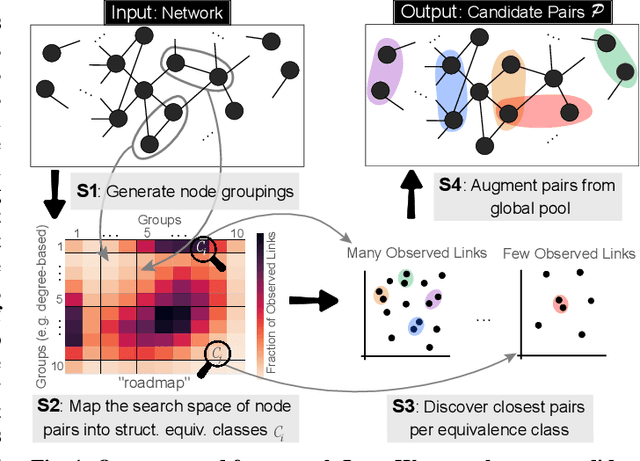
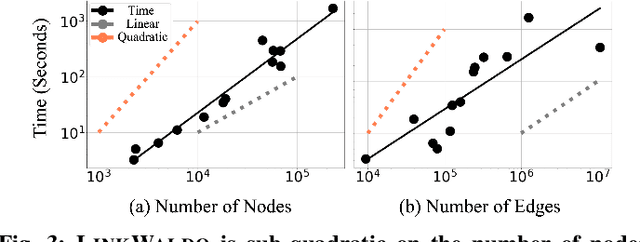

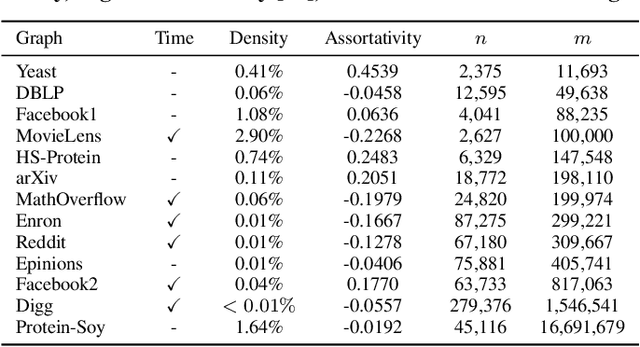
The traditional setup of link prediction in networks assumes that a test set of node pairs, which is usually balanced, is available over which to predict the presence of links. However, in practice, there is no test set: the ground-truth is not known, so the number of possible pairs to predict over is quadratic in the number of nodes in the graph. Moreover, because graphs are sparse, most of these possible pairs will not be links. Thus, link prediction methods, which often rely on proximity-preserving embeddings or heuristic notions of node similarity, face a vast search space, with many pairs that are in close proximity, but that should not be linked. To mitigate this issue, we introduce LinkWaldo, a framework for choosing from this quadratic, massively-skewed search space of node pairs, a concise set of candidate pairs that, in addition to being in close proximity, also structurally resemble the observed edges. This allows it to ignore some high-proximity but low-resemblance pairs, and also identify high-resemblance, lower-proximity pairs. Our framework is built on a model that theoretically combines Stochastic Block Models (SBMs) with node proximity models. The block structure of the SBM maps out where in the search space new links are expected to fall, and the proximity identifies the most plausible links within these blocks, using locality sensitive hashing to avoid expensive exhaustive search. LinkWaldo can use any node representation learning or heuristic definition of proximity, and can generate candidate pairs for any link prediction method, allowing the representation power of current and future methods to be realized for link prediction in practice. We evaluate LinkWaldo on 13 networks across multiple domains, and show that on average it returns candidate sets containing 7-33% more missing and future links than both embedding-based and heuristic baselines' sets.
A Novel Online Stacked Ensemble for Multi-Label Stream Classification
Sep 26, 2018
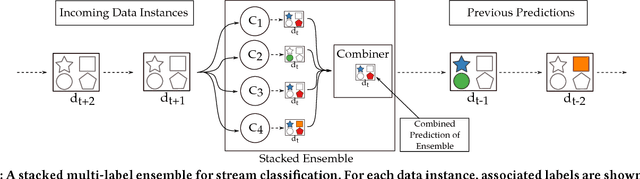

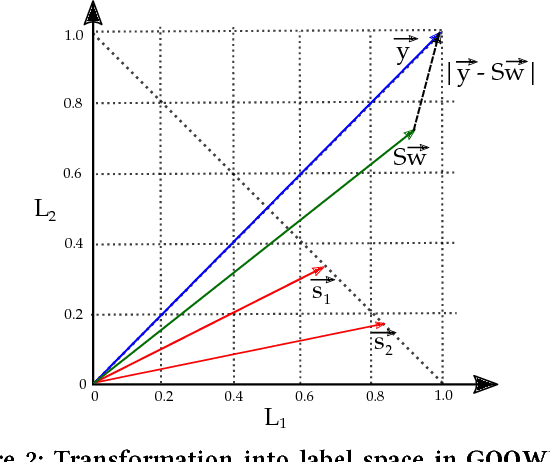
As data streams become more prevalent, the necessity for online algorithms that mine this transient and dynamic data becomes clearer. Multi-label data stream classification is a supervised learning problem where each instance in the data stream is classified into one or more pre-defined sets of labels. Many methods have been proposed to tackle this problem, including but not limited to ensemble-based methods. Some of these ensemble-based methods are specifically designed to work with certain multi-label base classifiers; some others employ online bagging schemes to build their ensembles. In this study, we introduce a novel online and dynamically-weighted stacked ensemble for multi-label classification, called GOOWE-ML, that utilizes spatial modeling to assign optimal weights to its component classifiers. Our model can be used with any existing incremental multi-label classification algorithm as its base classifier. We conduct experiments with 4 GOOWE-ML-based multi-label ensembles and 7 baseline models on 7 real-world datasets from diverse areas of interest. Our experiments show that GOOWE-ML ensembles yield consistently better results in terms of predictive performance in almost all of the datasets, with respect to the other prominent ensemble models.