 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMem: Context Management with A Decoupled Long-Context Model
May 29, 2026Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment. In this paper, we introduce CoMem, a novel framework that decouples memory management from the primary agent workflow, enabling these processes to execute in parallel. We propose a $k$-step-off asynchronous pipeline that overlaps the memory model's summarization with the agent's inference, effectively masking the latency of context processing. To ensure robustness under this asynchronous setting, we introduce a reward-driven training strategy that aligns the memory model to capture sufficient statistics for the agent's decision-making. Theoretical analysis confirms that CoMem offers a superior efficiency-effectiveness trade-off compared to coupled architectures. Our extensive experimental results on SWE-Bench-Verified show that CoMem provides 1.4x latency improvements upon vanilla long-context solutions while preserving most of the performance. Furthermore, we demonstrate that these latency gains scale favorably with increased system throughput, offering a modular path forward for the independent optimization of agent reasoning and memory compression.
A Broad Ensemble Learning System for Drifting Stream Classification
Oct 07, 2021
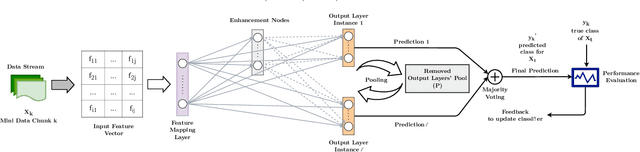
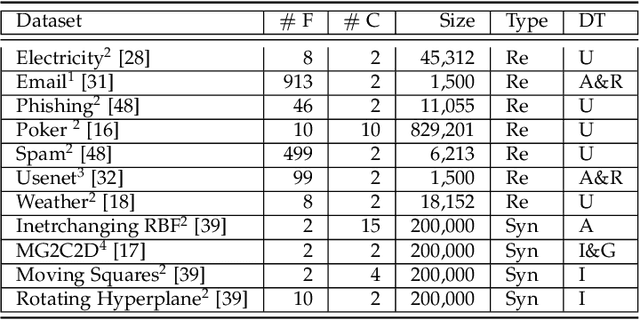
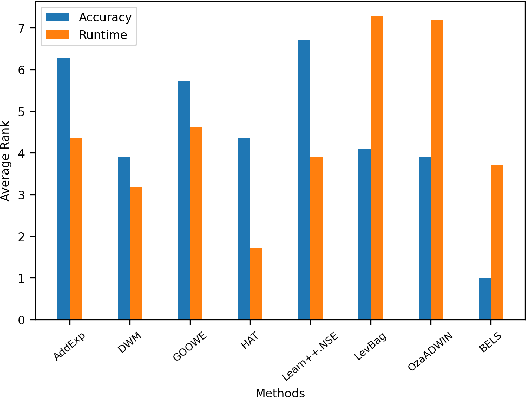
Data stream classification has become a major research topic due to the increase in temporal data. One of the biggest hurdles of data stream classification is the development of algorithms that deal with evolving data, also known as concept drifts. As data changes over time, static prediction models lose their validity. Adapting to concept drifts provides more robust and better performing models. The Broad Learning System (BLS) is an effective broad neural architecture recently developed for incremental learning. BLS cannot provide instant response since it requires huge data chunks and is unable to handle concept drifts. We propose a Broad Ensemble Learning System (BELS) for stream classification with concept drift. BELS uses a novel updating method that greatly improves best-in-class model accuracy. It employs a dynamic output ensemble layer to address the limitations of BLS. We present its mathematical derivation, provide comprehensive experiments with 11 datasets that demonstrate the adaptability of our model, including a comparison of our model with BLS, and provide parameter and robustness analysis on several drifting streams, showing that it statistically significantly outperforms seven state-of-the-art baselines. We show that our proposed method improves on average 44% compared to BLS, and 29% compared to other competitive baselines.
On-the-Fly Ensemble Pruning in Evolving Data Streams
Sep 15, 2021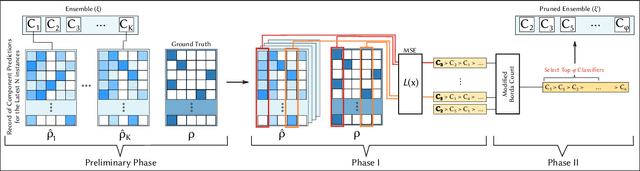
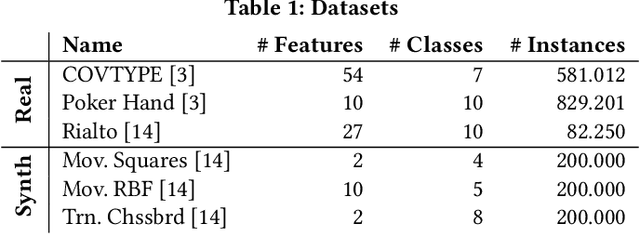
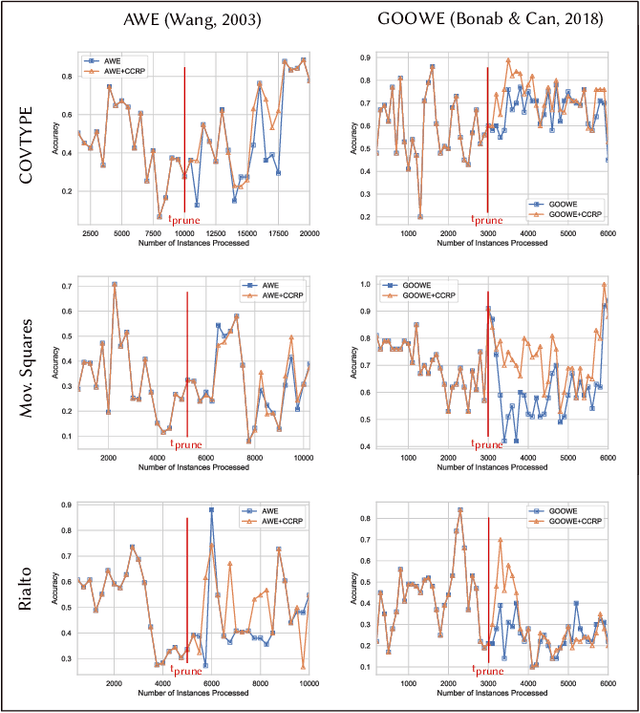
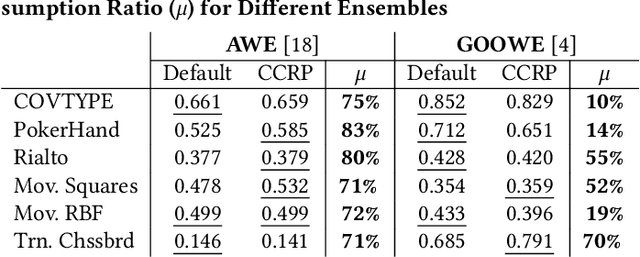
Ensemble pruning is the process of selecting a subset of componentclassifiers from an ensemble which performs at least as well as theoriginal ensemble while reducing storage and computational costs.Ensemble pruning in data streams is a largely unexplored area ofresearch. It requires analysis of ensemble components as they arerunning on the stream, and differentiation of useful classifiers fromredundant ones. We present CCRP, an on-the-fly ensemble prun-ing method for multi-class data stream classification empoweredby an imbalance-aware fusion of class-wise component rankings.CCRP aims that the resulting pruned ensemble contains the bestperforming classifier for each target class and hence, reduces the ef-fects of class imbalance. The conducted experiments on real-worldand synthetic data streams demonstrate that different types of en-sembles that integrate CCRP as their pruning scheme consistentlyyield on par or superior performance with 20% to 90% less averagememory consumption. Lastly, we validate the proposed pruningscheme by comparing our approach against pruning schemes basedon ensemble weights and basic rank fusion methods.
Mixed Attention Transformer for Leveraging Word-Level Knowledge to Neural Cross-Lingual Information Retrieval
Sep 14, 2021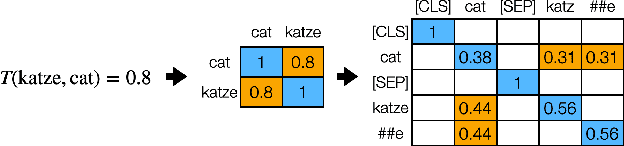

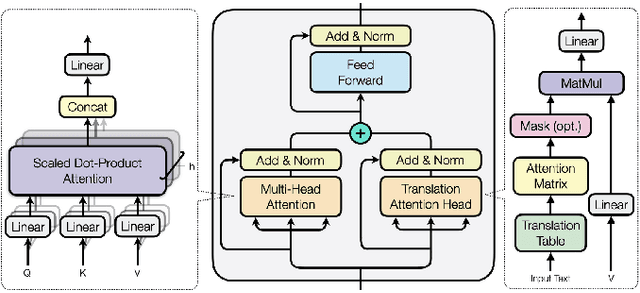
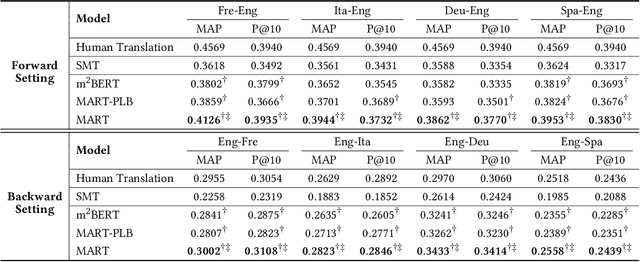
Pretrained contextualized representations offer great success for many downstream tasks, including document ranking. The multilingual versions of such pretrained representations provide a possibility of jointly learning many languages with the same model. Although it is expected to gain big with such joint training, in the case of cross lingual information retrieval (CLIR), the models under a multilingual setting are not achieving the same level of performance as those under a monolingual setting. We hypothesize that the performance drop is due to the translation gap between query and documents. In the monolingual retrieval task, because of the same lexical inputs, it is easier for model to identify the query terms that occurred in documents. However, in the multilingual pretrained models that the words in different languages are projected into the same hyperspace, the model tends to translate query terms into related terms, i.e., terms that appear in a similar context, in addition to or sometimes rather than synonyms in the target language. This property is creating difficulties for the model to connect terms that cooccur in both query and document. To address this issue, we propose a novel Mixed Attention Transformer (MAT) that incorporates external word level knowledge, such as a dictionary or translation table. We design a sandwich like architecture to embed MAT into the recent transformer based deep neural models. By encoding the translation knowledge into an attention matrix, the model with MAT is able to focus on the mutually translated words in the input sequence. Experimental results demonstrate the effectiveness of the external knowledge and the significant improvement of MAT embedded neural reranking model on CLIR task.
Cross-Market Product Recommendation
Sep 13, 2021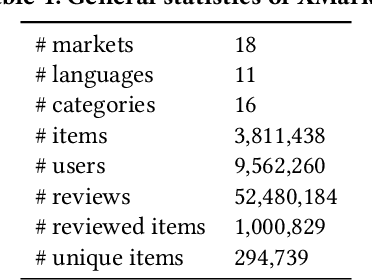
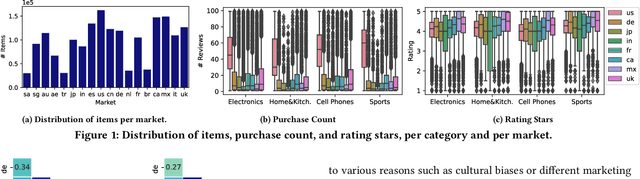
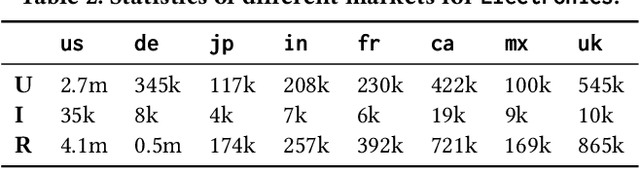
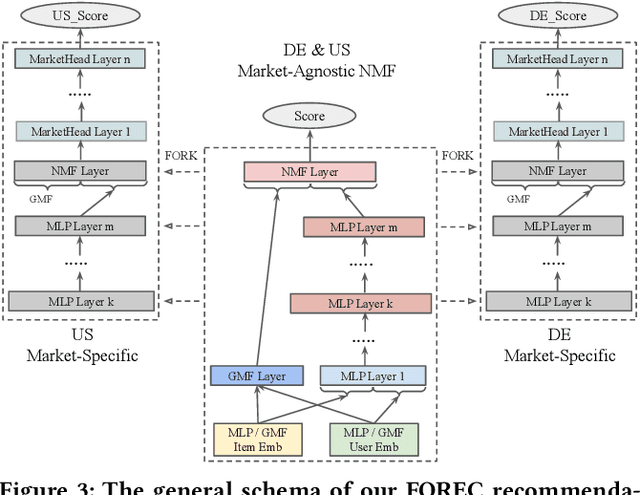
We study the problem of recommending relevant products to users in relatively resource-scarce markets by leveraging data from similar, richer in resource auxiliary markets. We hypothesize that data from one market can be used to improve performance in another. Only a few studies have been conducted in this area, partly due to the lack of publicly available experimental data. To this end, we collect and release XMarket, a large dataset covering 18 local markets on 16 different product categories, featuring 52.5 million user-item interactions. We introduce and formalize the problem of cross-market product recommendation, i.e., market adaptation. We explore different market-adaptation techniques inspired by state-of-the-art domain-adaptation and meta-learning approaches and propose a novel neural approach for market adaptation, named FOREC. Our model follows a three-step procedure -- pre-training, forking, and fine-tuning -- in order to fully utilize the data from an auxiliary market as well as the target market. We conduct extensive experiments studying the impact of market adaptation on different pairs of markets. Our proposed approach demonstrates robust effectiveness, consistently improving the performance on target markets compared to competitive baselines selected for our analysis. In particular, FOREC improves on average 24% and up to 50% in terms of nDCG@10, compared to the NMF baseline. Our analysis and experiments suggest specific future directions in this research area. We release our data and code for academic purposes.
Query-driven Segment Selection for Ranking Long Documents
Sep 10, 2021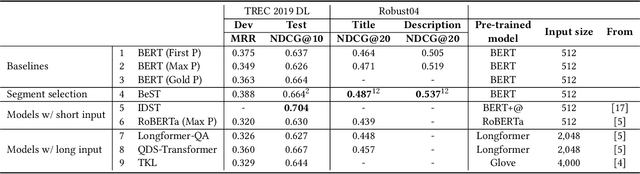
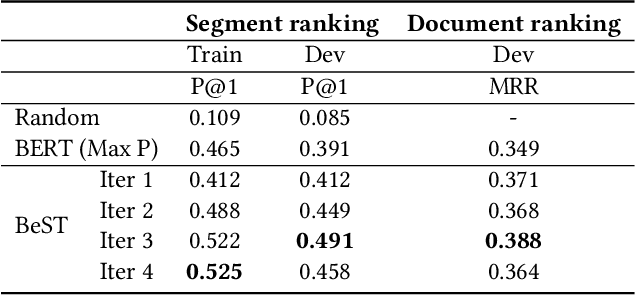
Transformer-based rankers have shown state-of-the-art performance. However, their self-attention operation is mostly unable to process long sequences. One of the common approaches to train these rankers is to heuristically select some segments of each document, such as the first segment, as training data. However, these segments may not contain the query-related parts of documents. To address this problem, we propose query-driven segment selection from long documents to build training data. The segment selector provides relevant samples with more accurate labels and non-relevant samples which are harder to be predicted. The experimental results show that the basic BERT-based ranker trained with the proposed segment selector significantly outperforms that trained by the heuristically selected segments, and performs equally to the state-of-the-art model with localized self-attention that can process longer input sequences. Our findings open up new direction to design efficient transformer-based rankers.
* 5 pages, 0 figure
A Multi-Task Architecture on Relevance-based Neural Query Translation
Jun 17, 2019

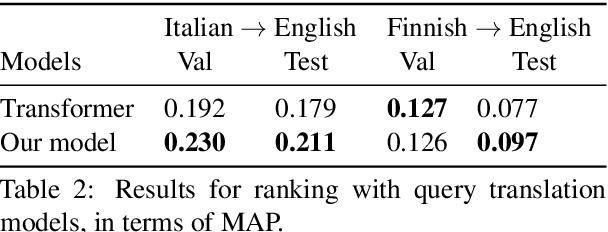
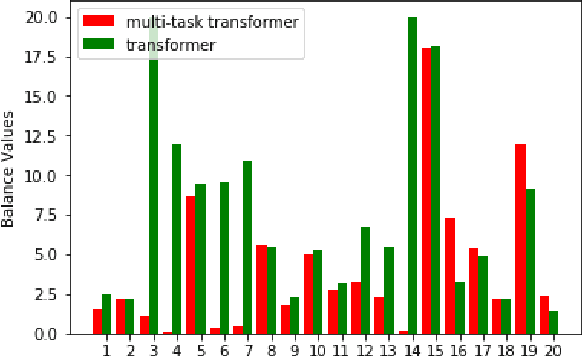
We describe a multi-task learning approach to train a Neural Machine Translation (NMT) model with a Relevance-based Auxiliary Task (RAT) for search query translation. The translation process for Cross-lingual Information Retrieval (CLIR) task is usually treated as a black box and it is performed as an independent step. However, an NMT model trained on sentence-level parallel data is not aware of the vocabulary distribution of the retrieval corpus. We address this problem with our multi-task learning architecture that achieves 16% improvement over a strong NMT baseline on Italian-English query-document dataset. We show using both quantitative and qualitative analysis that our model generates balanced and precise translations with the regularization effect it achieves from multi-task learning paradigm.
Less Is More: A Comprehensive Framework for the Number of Components of Ensemble Classifiers
Sep 29, 2018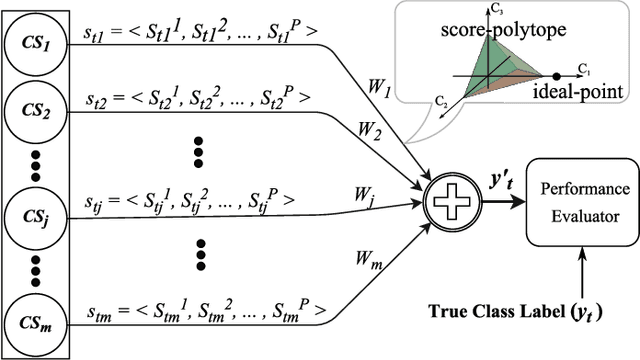
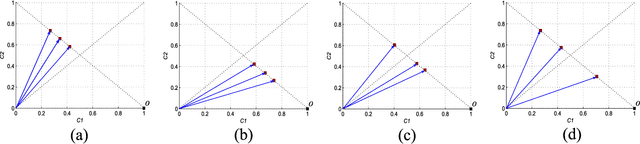
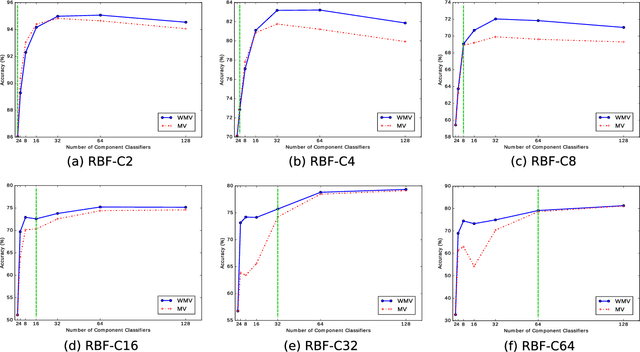
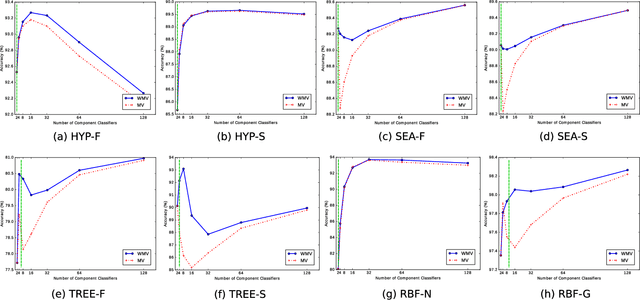
The number of component classifiers chosen for an ensemble greatly impacts the prediction ability. In this paper, we use a geometric framework for a priori determining the ensemble size, which is applicable to most of existing batch and online ensemble classifiers. There are only a limited number of studies on the ensemble size examining Majority Voting (MV) and Weighted Majority Voting (WMV). Almost all of them are designed for batch-mode, hardly addressing online environments. Big data dimensions and resource limitations, in terms of time and memory, make determination of ensemble size crucial, especially for online environments. For the MV aggregation rule, our framework proves that the more strong components we add to the ensemble, the more accurate predictions we can achieve. For the WMV aggregation rule, our framework proves the existence of an ideal number of components, which is equal to the number of class labels, with the premise that components are completely independent of each other and strong enough. While giving the exact definition for a strong and independent classifier in the context of an ensemble is a challenging task, our proposed geometric framework provides a theoretical explanation of diversity and its impact on the accuracy of predictions. We conduct a series of experimental evaluations to show the practical value of our theorems and existing challenges.
A Novel Online Stacked Ensemble for Multi-Label Stream Classification
Sep 26, 2018
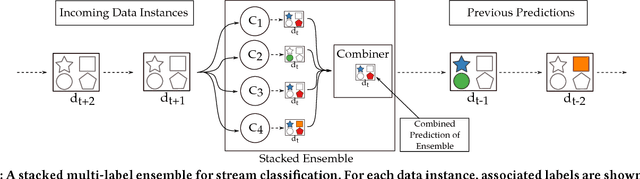

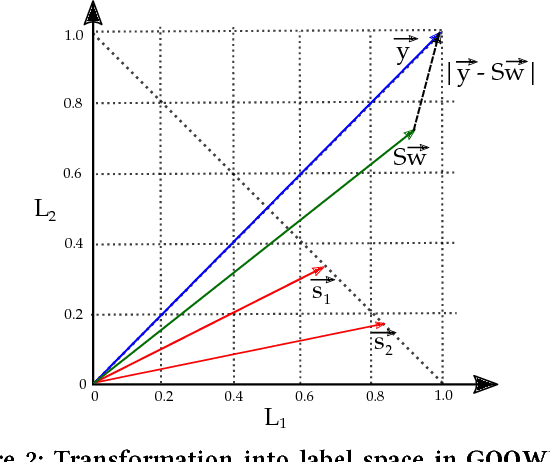
As data streams become more prevalent, the necessity for online algorithms that mine this transient and dynamic data becomes clearer. Multi-label data stream classification is a supervised learning problem where each instance in the data stream is classified into one or more pre-defined sets of labels. Many methods have been proposed to tackle this problem, including but not limited to ensemble-based methods. Some of these ensemble-based methods are specifically designed to work with certain multi-label base classifiers; some others employ online bagging schemes to build their ensembles. In this study, we introduce a novel online and dynamically-weighted stacked ensemble for multi-label classification, called GOOWE-ML, that utilizes spatial modeling to assign optimal weights to its component classifiers. Our model can be used with any existing incremental multi-label classification algorithm as its base classifier. We conduct experiments with 4 GOOWE-ML-based multi-label ensembles and 7 baseline models on 7 real-world datasets from diverse areas of interest. Our experiments show that GOOWE-ML ensembles yield consistently better results in terms of predictive performance in almost all of the datasets, with respect to the other prominent ensemble models.