 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Law: Datasets, Benchmarks, and Ontologies
Mar 06, 2025
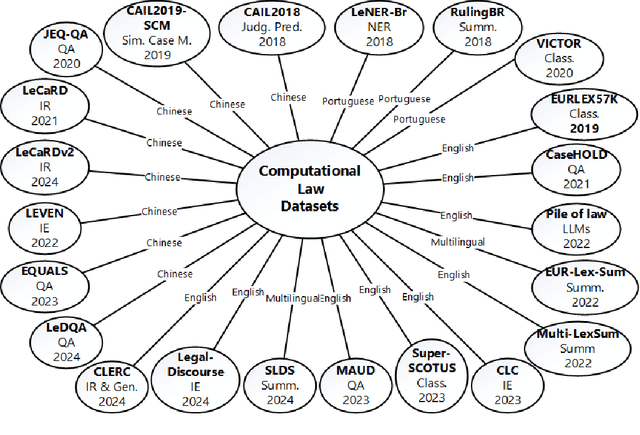
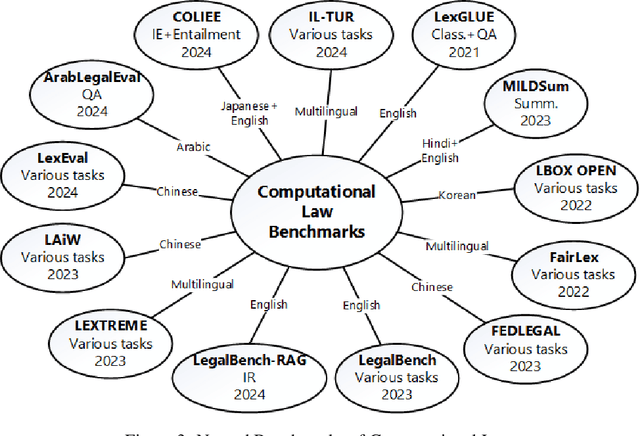
Recent developments in computer science and artificial intelligence have also contributed to the legal domain, as revealed by the number and range of related publications and applications. Machine and deep learning models require considerable amount of domain-specific data for training and comparison purposes, in order to attain high-performance in the legal domain. Additionally, semantic resources such as ontologies are valuable for building large-scale computational legal systems, in addition to ensuring interoperability of such systems. Considering these aspects, we present an up-to-date review of the literature on datasets, benchmarks, and ontologies proposed for computational law. We believe that this comprehensive and recent review will help researchers and practitioners when developing and testing approaches and systems for computational law.
Balancing Efficiency vs. Effectiveness and Providing Missing Label Robustness in Multi-Label Stream Classification
Oct 01, 2023Available works addressing multi-label classification in a data stream environment focus on proposing accurate models; however, these models often exhibit inefficiency and cannot balance effectiveness and efficiency. In this work, we propose a neural network-based approach that tackles this issue and is suitable for high-dimensional multi-label classification. Our model uses a selective concept drift adaptation mechanism that makes it suitable for a non-stationary environment. Additionally, we adapt our model to an environment with missing labels using a simple yet effective imputation strategy and demonstrate that it outperforms a vast majority of the state-of-the-art supervised models. To achieve our purposes, we introduce a weighted binary relevance-based approach named ML-BELS using the Broad Ensemble Learning System (BELS) as its base classifier. Instead of a chain of stacked classifiers, our model employs independent weighted ensembles, with the weights generated by the predictions of a BELS classifier. We show that using the weighting strategy on datasets with low label cardinality negatively impacts the accuracy of the model; with this in mind, we use the label cardinality as a trigger for applying the weights. We present an extensive assessment of our model using 11 state-of-the-art baselines, five synthetics, and 13 real-world datasets, all with different characteristics. Our results demonstrate that the proposed approach ML-BELS is successful in balancing effectiveness and efficiency, and is robust to missing labels and concept drift.
DynED: Dynamic Ensemble Diversification in Data Stream Classification
Sep 06, 2023Ensemble methods are commonly used in classification due to their remarkable performance. Achieving high accuracy in a data stream environment is a challenging task considering disruptive changes in the data distribution, also known as concept drift. A greater diversity of ensemble components is known to enhance prediction accuracy in such settings. Despite the diversity of components within an ensemble, not all contribute as expected to its overall performance. This necessitates a method for selecting components that exhibit high performance and diversity. We present a novel ensemble construction and maintenance approach based on MMR (Maximal Marginal Relevance) that dynamically combines the diversity and prediction accuracy of components during the process of structuring an ensemble. The experimental results on both four real and 11 synthetic datasets demonstrate that the proposed approach (DynED) provides a higher average mean accuracy compared to the five state-of-the-art baselines.
Leveraging Linear Independence of Component Classifiers: Optimizing Size and Prediction Accuracy for Online Ensembles
Aug 27, 2023Ensembles, which employ a set of classifiers to enhance classification accuracy collectively, are crucial in the era of big data. However, although there is general agreement that the relation between ensemble size and its prediction accuracy, the exact nature of this relationship is still unknown. We introduce a novel perspective, rooted in the linear independence of classifier's votes, to analyze the interplay between ensemble size and prediction accuracy. This framework reveals a theoretical link, consequently proposing an ensemble size based on this relationship. Our study builds upon a geometric framework and develops a series of theorems. These theorems clarify the role of linear dependency in crafting ensembles. We present a method to determine the minimum ensemble size required to ensure a target probability of linearly independent votes among component classifiers. Incorporating real and synthetic datasets, our empirical results demonstrate a trend: increasing the number of classifiers enhances accuracy, as predicted by our theoretical insights. However, we also identify a point of diminishing returns, beyond which additional classifiers provide diminishing improvements in accuracy. Surprisingly, the calculated ideal ensemble size deviates from empirical results for certain datasets, emphasizing the influence of other factors. This study opens avenues for deeper investigations into the complex dynamics governing ensemble design and offers guidance for constructing efficient and effective ensembles in practical scenarios.
Not Good Times for Lies: Misinformation Detection on the Russia-Ukraine War, COVID-19, and Refugees
Oct 11, 2022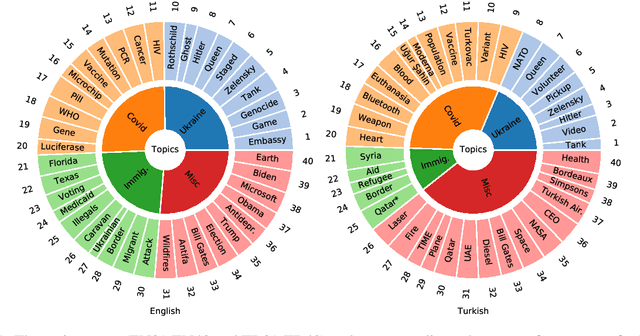
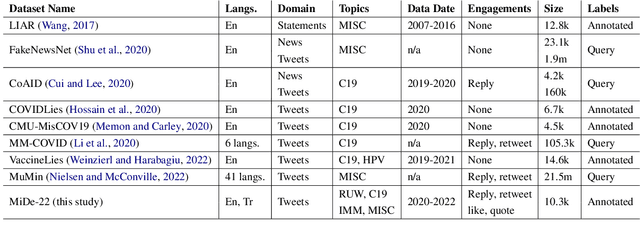
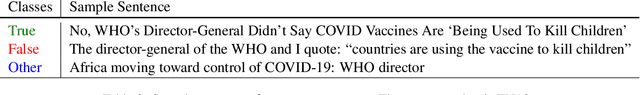

Misinformation spread in online social networks is an urgent-to-solve problem having harmful consequences that threaten human health, public safety, economics, and so on. In this study, we construct a novel dataset, called MiDe-22, having 5,284 English and 5,064 Turkish tweets with their misinformation labels under several recent events, including the Russia-Ukraine war, COVID-19 pandemic, and Refugees. Moreover, we provide the user engagements to the tweets in terms of likes, replies, retweets, and quotes. We present a detailed data analysis with descriptive statistics and temporal analysis, and provide the experimental results of a benchmark evaluation for misinformation detection on our novel dataset.
Implicit Concept Drift Detection for Multi-label Data Streams
Jan 31, 2022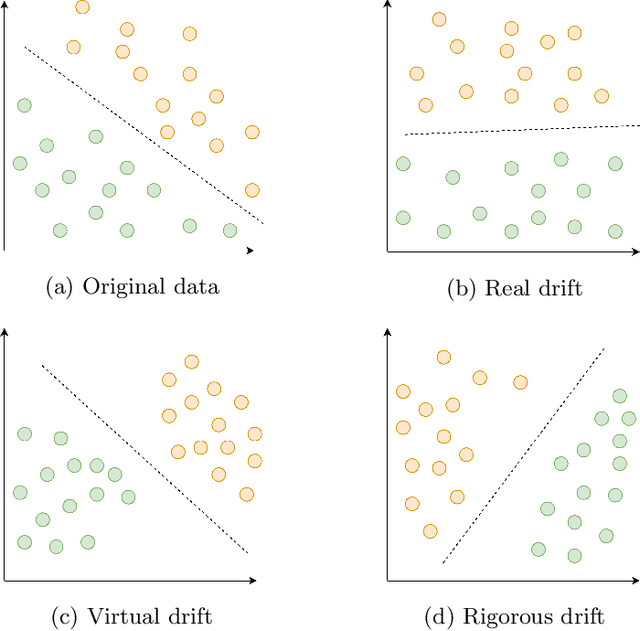
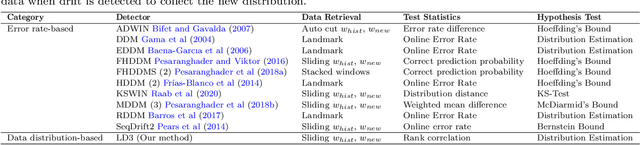
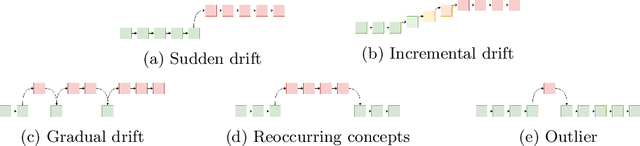
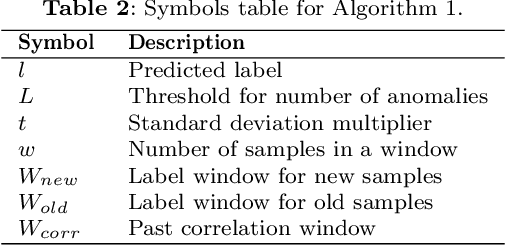
Many real-world applications adopt multi-label data streams as the need for algorithms to deal with rapidly changing data increases. Changes in data distribution, also known as concept drift, cause the existing classification models to rapidly lose their effectiveness. To assist the classifiers, we propose a novel algorithm called Label Dependency Drift Detector (LD3), an implicit (unsupervised) concept drift detector using label dependencies within the data for multi-label data streams. Our study exploits the dynamic temporal dependencies between labels using a label influence ranking method, which leverages a data fusion algorithm and uses the produced ranking to detect concept drift. LD3 is the first unsupervised concept drift detection algorithm in the multi-label classification problem area. In this study, we perform an extensive evaluation of LD3 by comparing it with 14 prevalent supervised concept drift detection algorithms that we adapt to the problem area using 12 datasets and a baseline classifier. The results show that LD3 provides between 19.8\% and 68.6\% better predictive performance than comparable detectors on both real-world and synthetic data streams.
A Broad Ensemble Learning System for Drifting Stream Classification
Oct 07, 2021
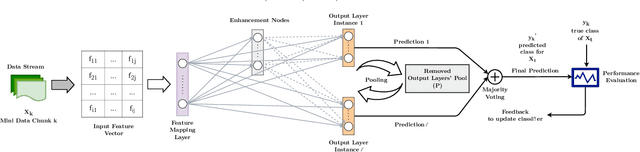
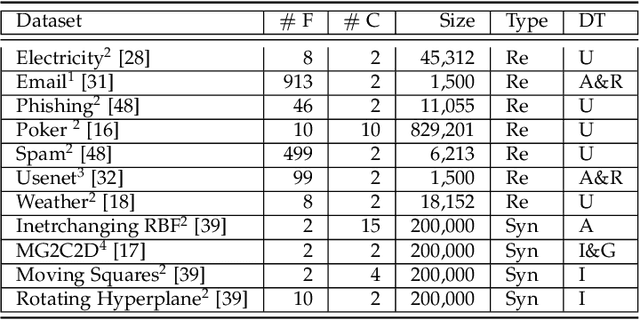
Data stream classification has become a major research topic due to the increase in temporal data. One of the biggest hurdles of data stream classification is the development of algorithms that deal with evolving data, also known as concept drifts. As data changes over time, static prediction models lose their validity. Adapting to concept drifts provides more robust and better performing models. The Broad Learning System (BLS) is an effective broad neural architecture recently developed for incremental learning. BLS cannot provide instant response since it requires huge data chunks and is unable to handle concept drifts. We propose a Broad Ensemble Learning System (BELS) for stream classification with concept drift. BELS uses a novel updating method that greatly improves best-in-class model accuracy. It employs a dynamic output ensemble layer to address the limitations of BLS. We present its mathematical derivation, provide comprehensive experiments with 11 datasets that demonstrate the adaptability of our model, including a comparison of our model with BLS, and provide parameter and robustness analysis on several drifting streams, showing that it statistically significantly outperforms seven state-of-the-art baselines. We show that our proposed method improves on average 44% compared to BLS, and 29% compared to other competitive baselines.
On-the-Fly Ensemble Pruning in Evolving Data Streams
Sep 15, 2021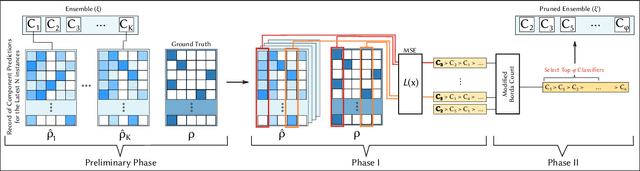
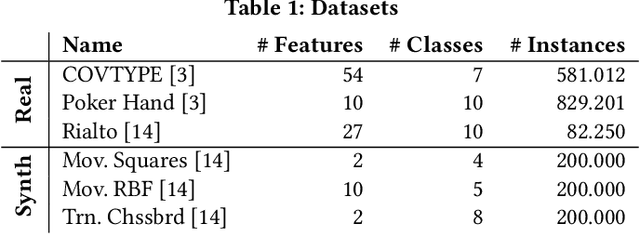
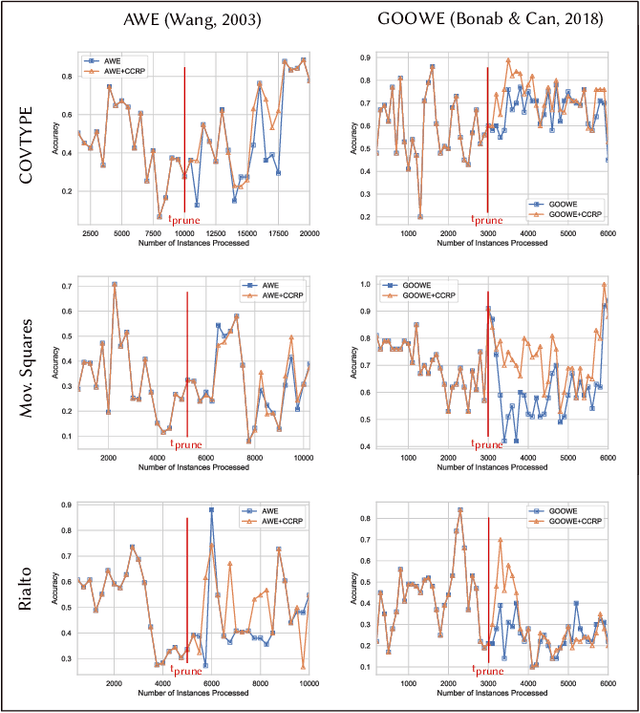
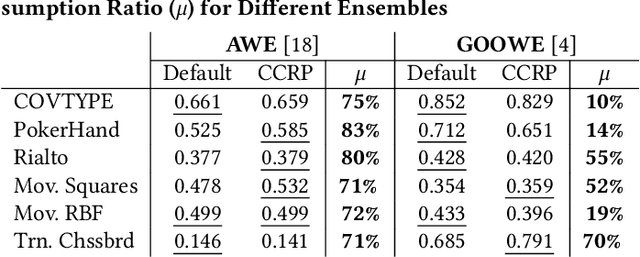
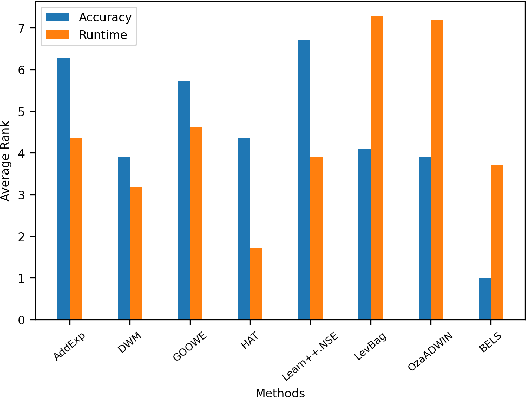
Ensemble pruning is the process of selecting a subset of componentclassifiers from an ensemble which performs at least as well as theoriginal ensemble while reducing storage and computational costs.Ensemble pruning in data streams is a largely unexplored area ofresearch. It requires analysis of ensemble components as they arerunning on the stream, and differentiation of useful classifiers fromredundant ones. We present CCRP, an on-the-fly ensemble prun-ing method for multi-class data stream classification empoweredby an imbalance-aware fusion of class-wise component rankings.CCRP aims that the resulting pruned ensemble contains the bestperforming classifier for each target class and hence, reduces the ef-fects of class imbalance. The conducted experiments on real-worldand synthetic data streams demonstrate that different types of en-sembles that integrate CCRP as their pruning scheme consistentlyyield on par or superior performance with 20% to 90% less averagememory consumption. Lastly, we validate the proposed pruningscheme by comparing our approach against pruning schemes basedon ensemble weights and basic rank fusion methods.
A Tweet Dataset Annotated for Named Entity Recognition and Stance Detection
Jan 16, 2019Annotated datasets in different domains are critical for many supervised learning-based solutions to related problems and for the evaluation of the proposed solutions. Topics in natural language processing (NLP) similarly require annotated datasets to be used for such purposes. In this paper, we target at two NLP problems, named entity recognition and stance detection, and present the details of a tweet dataset in Turkish annotated for named entity and stance information. Within the course of the current study, both the named entity and stance annotations of the included tweets are made publicly available, although previously the dataset has been publicly shared with stance annotations only. We believe that this dataset will be useful for uncovering the possible relationships between named entity recognition and stance detection in tweets.
Less Is More: A Comprehensive Framework for the Number of Components of Ensemble Classifiers
Sep 29, 2018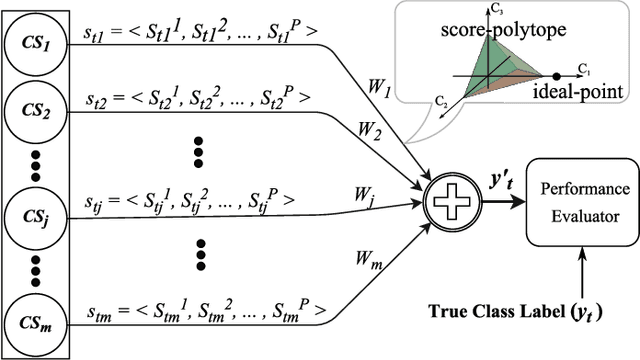
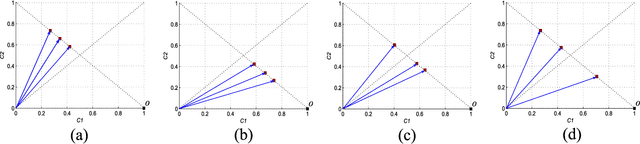
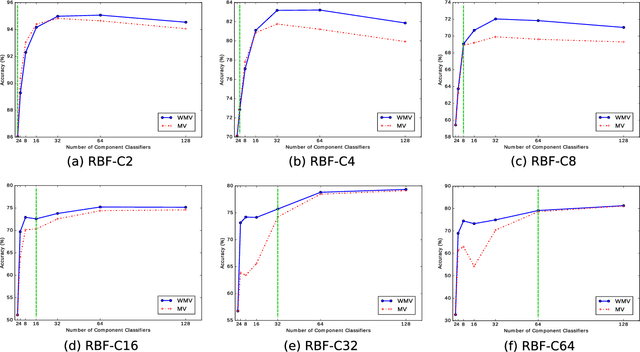
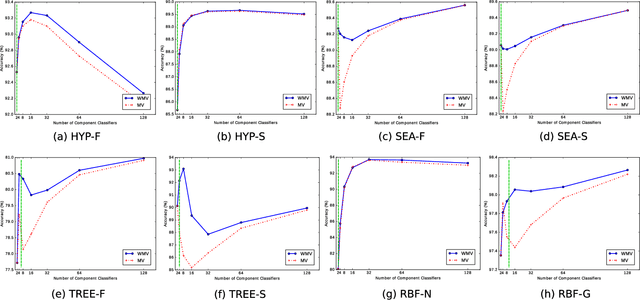
The number of component classifiers chosen for an ensemble greatly impacts the prediction ability. In this paper, we use a geometric framework for a priori determining the ensemble size, which is applicable to most of existing batch and online ensemble classifiers. There are only a limited number of studies on the ensemble size examining Majority Voting (MV) and Weighted Majority Voting (WMV). Almost all of them are designed for batch-mode, hardly addressing online environments. Big data dimensions and resource limitations, in terms of time and memory, make determination of ensemble size crucial, especially for online environments. For the MV aggregation rule, our framework proves that the more strong components we add to the ensemble, the more accurate predictions we can achieve. For the WMV aggregation rule, our framework proves the existence of an ideal number of components, which is equal to the number of class labels, with the premise that components are completely independent of each other and strong enough. While giving the exact definition for a strong and independent classifier in the context of an ensemble is a challenging task, our proposed geometric framework provides a theoretical explanation of diversity and its impact on the accuracy of predictions. We conduct a series of experimental evaluations to show the practical value of our theorems and existing challenges.