 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Efficiency vs. Effectiveness and Providing Missing Label Robustness in Multi-Label Stream Classification
Oct 01, 2023Available works addressing multi-label classification in a data stream environment focus on proposing accurate models; however, these models often exhibit inefficiency and cannot balance effectiveness and efficiency. In this work, we propose a neural network-based approach that tackles this issue and is suitable for high-dimensional multi-label classification. Our model uses a selective concept drift adaptation mechanism that makes it suitable for a non-stationary environment. Additionally, we adapt our model to an environment with missing labels using a simple yet effective imputation strategy and demonstrate that it outperforms a vast majority of the state-of-the-art supervised models. To achieve our purposes, we introduce a weighted binary relevance-based approach named ML-BELS using the Broad Ensemble Learning System (BELS) as its base classifier. Instead of a chain of stacked classifiers, our model employs independent weighted ensembles, with the weights generated by the predictions of a BELS classifier. We show that using the weighting strategy on datasets with low label cardinality negatively impacts the accuracy of the model; with this in mind, we use the label cardinality as a trigger for applying the weights. We present an extensive assessment of our model using 11 state-of-the-art baselines, five synthetics, and 13 real-world datasets, all with different characteristics. Our results demonstrate that the proposed approach ML-BELS is successful in balancing effectiveness and efficiency, and is robust to missing labels and concept drift.
DynED: Dynamic Ensemble Diversification in Data Stream Classification
Sep 06, 2023Ensemble methods are commonly used in classification due to their remarkable performance. Achieving high accuracy in a data stream environment is a challenging task considering disruptive changes in the data distribution, also known as concept drift. A greater diversity of ensemble components is known to enhance prediction accuracy in such settings. Despite the diversity of components within an ensemble, not all contribute as expected to its overall performance. This necessitates a method for selecting components that exhibit high performance and diversity. We present a novel ensemble construction and maintenance approach based on MMR (Maximal Marginal Relevance) that dynamically combines the diversity and prediction accuracy of components during the process of structuring an ensemble. The experimental results on both four real and 11 synthetic datasets demonstrate that the proposed approach (DynED) provides a higher average mean accuracy compared to the five state-of-the-art baselines.
A Broad Ensemble Learning System for Drifting Stream Classification
Oct 07, 2021
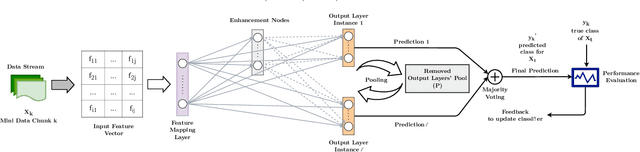
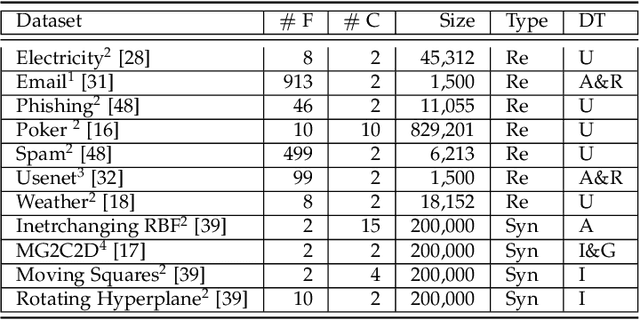
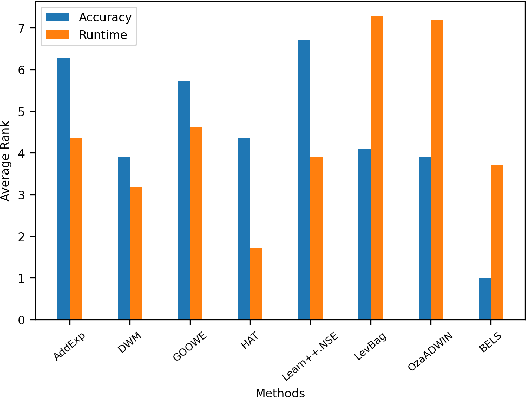
Data stream classification has become a major research topic due to the increase in temporal data. One of the biggest hurdles of data stream classification is the development of algorithms that deal with evolving data, also known as concept drifts. As data changes over time, static prediction models lose their validity. Adapting to concept drifts provides more robust and better performing models. The Broad Learning System (BLS) is an effective broad neural architecture recently developed for incremental learning. BLS cannot provide instant response since it requires huge data chunks and is unable to handle concept drifts. We propose a Broad Ensemble Learning System (BELS) for stream classification with concept drift. BELS uses a novel updating method that greatly improves best-in-class model accuracy. It employs a dynamic output ensemble layer to address the limitations of BLS. We present its mathematical derivation, provide comprehensive experiments with 11 datasets that demonstrate the adaptability of our model, including a comparison of our model with BLS, and provide parameter and robustness analysis on several drifting streams, showing that it statistically significantly outperforms seven state-of-the-art baselines. We show that our proposed method improves on average 44% compared to BLS, and 29% compared to other competitive baselines.