 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Modeling for Scientific Writing Evaluation
Jan 16, 2026Scientific writing is an expert-domain task that demands deep domain knowledge, task-specific requirements and reasoning capabilities that leverage the domain knowledge to satisfy the task specifications. While scientific text generation has been widely studied, its evaluation remains a challenging and open problem. It is critical to develop models that can be reliably deployed for evaluating diverse open-ended scientific writing tasks while adhering to their distinct requirements. However, existing LLM-based judges and reward models are primarily optimized for general-purpose benchmarks with fixed scoring rubrics and evaluation criteria. Consequently, they often fail to reason over sparse knowledge of scientific domains when interpreting task-dependent and multi-faceted criteria. Moreover, fine-tuning for each individual task is costly and impractical for low-resource settings. To bridge these gaps, we propose cost-efficient, open-source reward models tailored for scientific writing evaluation. We introduce a two-stage training framework that initially optimizes scientific evaluation preferences and then refines reasoning capabilities. Our multi-aspect evaluation design and joint training across diverse tasks enable fine-grained assessment and robustness to dynamic criteria and scoring rubrics. Experimental analysis shows that our training regime strongly improves LLM-based scientific writing evaluation. Our models generalize effectively across tasks and to previously unseen scientific writing evaluation settings, allowing a single trained evaluator to be reused without task-specific retraining.
Expert Preference-based Evaluation of Automated Related Work Generation
Aug 11, 2025Expert domain writing, such as scientific writing, typically demands extensive domain knowledge. Recent advances in LLMs show promising potential in reducing the expert workload. However, evaluating the quality of automatically generated scientific writing is a crucial open issue, as it requires knowledge of domain-specific evaluation criteria and the ability to discern expert preferences. Conventional automatic metrics and LLM-as-a-judge systems are insufficient to grasp expert preferences and domain-specific quality standards. To address this gap and support human-AI collaborative writing, we focus on related work generation, one of the most challenging scientific tasks, as an exemplar. We propose GREP, a multi-turn evaluation framework that integrates classical related work evaluation criteria with expert-specific preferences. Instead of assigning a single score, our framework decomposes the evaluation into fine-grained dimensions. This localized evaluation approach is further augmented with contrastive few-shot examples to provide detailed contextual guidance for the evaluation dimensions. The design principles allow our framework to deliver cardinal assessment of quality, which can facilitate better post-training compared to ordinal preference data. For better accessibility, we design two variants of GREP: a more precise variant with proprietary LLMs as evaluators, and a cheaper alternative with open-weight LLMs. Empirical investigation reveals that our framework is able to assess the quality of related work sections in a much more robust manner compared to standard LLM judges, reflects natural scenarios of scientific writing, and bears a strong correlation with the human expert assessment. We also observe that generations from state-of-the-art LLMs struggle to satisfy validation constraints of a suitable related work section. They (mostly) fail to improve based on feedback as well.
Systematic Task Exploration with LLMs: A Study in Citation Text Generation
Jul 04, 2024
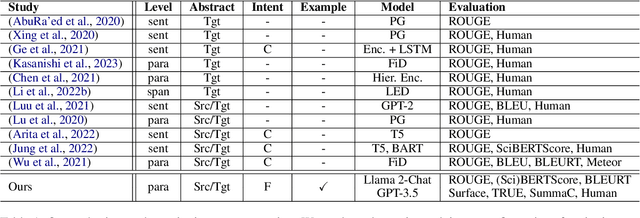


Large language models (LLMs) bring unprecedented flexibility in defining and executing complex, creative natural language generation (NLG) tasks. Yet, this flexibility brings new challenges, as it introduces new degrees of freedom in formulating the task inputs and instructions and in evaluating model performance. To facilitate the exploration of creative NLG tasks, we propose a three-component research framework that consists of systematic input manipulation, reference data, and output measurement. We use this framework to explore citation text generation -- a popular scholarly NLP task that lacks consensus on the task definition and evaluation metric and has not yet been tackled within the LLM paradigm. Our results highlight the importance of systematically investigating both task instruction and input configuration when prompting LLMs, and reveal non-trivial relationships between different evaluation metrics used for citation text generation. Additional human generation and human evaluation experiments provide new qualitative insights into the task to guide future research in citation text generation. We make our code and data publicly available.
Not Good Times for Lies: Misinformation Detection on the Russia-Ukraine War, COVID-19, and Refugees
Oct 11, 2022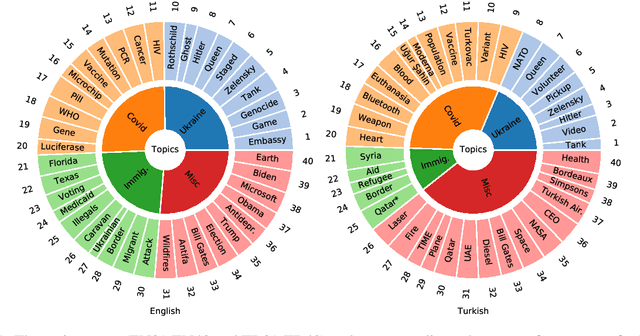
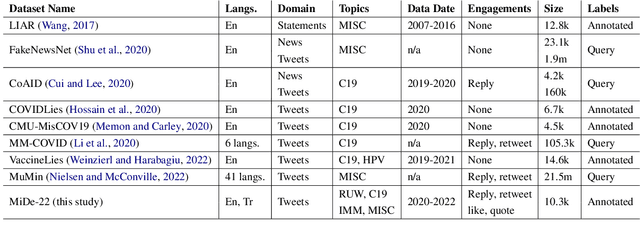
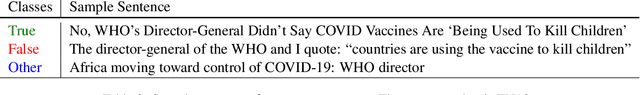

Misinformation spread in online social networks is an urgent-to-solve problem having harmful consequences that threaten human health, public safety, economics, and so on. In this study, we construct a novel dataset, called MiDe-22, having 5,284 English and 5,064 Turkish tweets with their misinformation labels under several recent events, including the Russia-Ukraine war, COVID-19 pandemic, and Refugees. Moreover, we provide the user engagements to the tweets in terms of likes, replies, retweets, and quotes. We present a detailed data analysis with descriptive statistics and temporal analysis, and provide the experimental results of a benchmark evaluation for misinformation detection on our novel dataset.
Fast-FNet: Accelerating Transformer Encoder Models via Efficient Fourier Layers
Sep 26, 2022
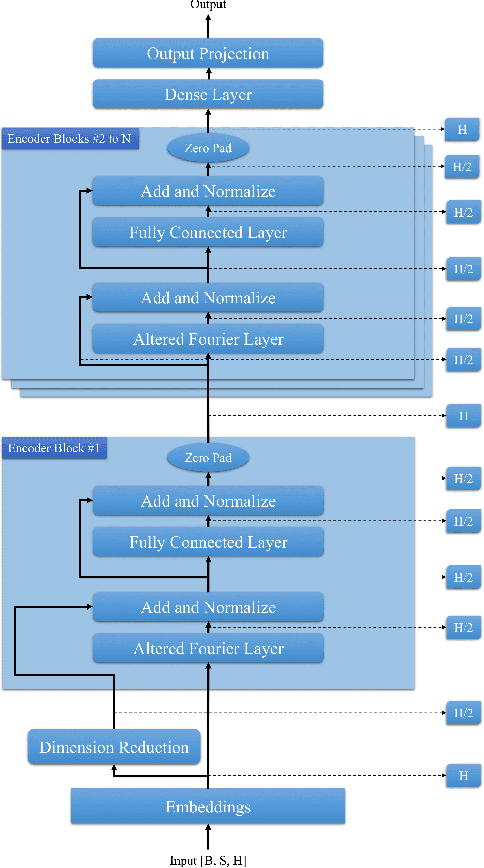
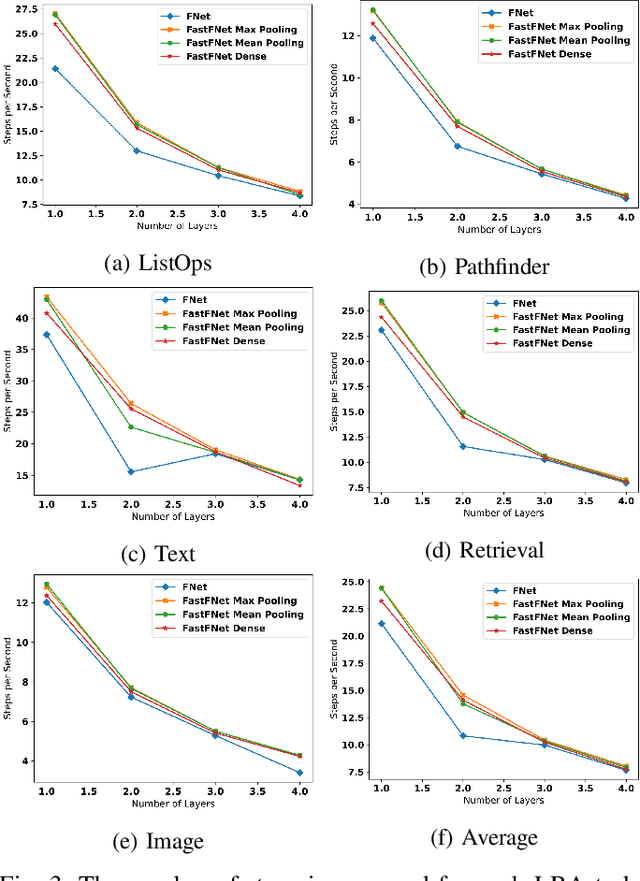
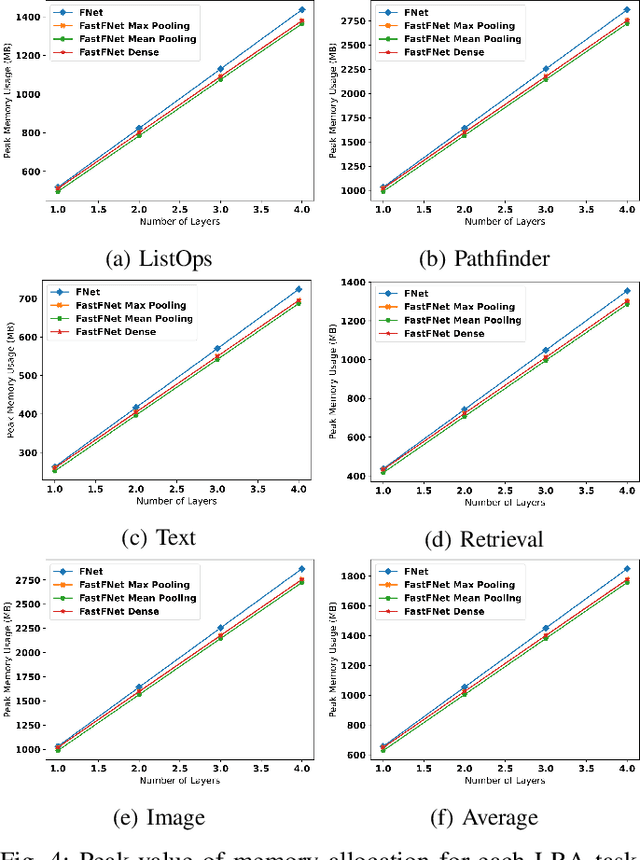
Transformer-based language models utilize the attention mechanism for substantial performance improvements in almost all natural language processing (NLP) tasks. Similar attention structures are also extensively studied in several other areas. Although the attention mechanism enhances the model performances significantly, its quadratic complexity prevents efficient processing of long sequences. Recent works focused on eliminating the disadvantages of computational inefficiency and showed that transformer-based models can still reach competitive results without the attention layer. A pioneering study proposed the FNet, which replaces the attention layer with the Fourier Transform (FT) in the transformer encoder architecture. FNet achieves competitive performances concerning the original transformer encoder model while accelerating training process by removing the computational burden of the attention mechanism. However, the FNet model ignores essential properties of the FT from the classical signal processing that can be leveraged to increase model efficiency further. We propose different methods to deploy FT efficiently in transformer encoder models. Our proposed architectures have smaller number of model parameters, shorter training times, less memory usage, and some additional performance improvements. We demonstrate these improvements through extensive experiments on common benchmarks.
Impact of Tokenization on Language Models: An Analysis for Turkish
Apr 19, 2022
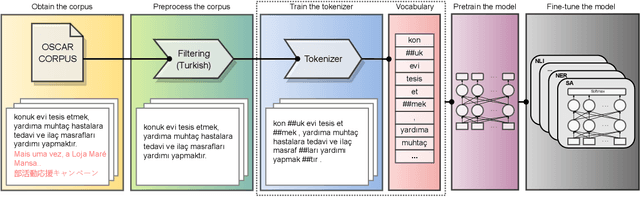

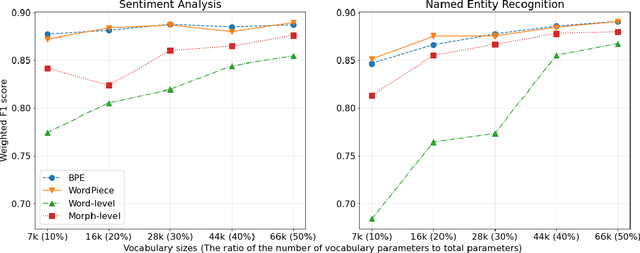
Tokenization is an important text preprocessing step to prepare input tokens for deep language models. WordPiece and BPE are de facto methods employed by important models, such as BERT and GPT. However, the impact of tokenization can be different for morphologically rich languages, such as Turkic languages, where many words can be generated by adding prefixes and suffixes. We compare five tokenizers at different granularity levels, i.e. their outputs vary from smallest pieces of characters to the surface form of words, including a Morphological-level tokenizer. We train these tokenizers and pretrain medium-sized language models using RoBERTa pretraining procedure on the Turkish split of the OSCAR corpus. We then fine-tune our models on six downstream tasks. Our experiments, supported by statistical tests, reveal that Morphological-level tokenizer has challenging performance with de facto tokenizers. Furthermore, we find that increasing the vocabulary size improves the performance of Morphological and Word-level tokenizers more than that of de facto tokenizers. The ratio of the number of vocabulary parameters to the total number of model parameters can be empirically chosen as 20% for de facto tokenizers and 40% for other tokenizers to obtain a reasonable trade-off between model size and performance.
Large-Scale Hate Speech Detection with Cross-Domain Transfer
Mar 02, 2022


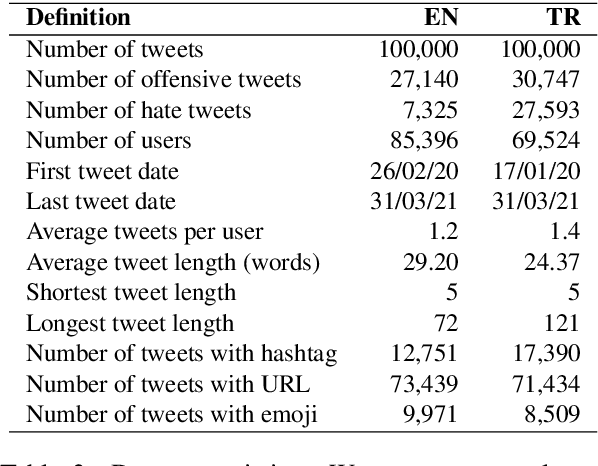
The performance of hate speech detection models relies on the datasets on which the models are trained. Existing datasets are mostly prepared with a limited number of instances or hate domains that define hate topics. This hinders large-scale analysis and transfer learning with respect to hate domains. In this study, we construct large-scale tweet datasets for hate speech detection in English and a low-resource language, Turkish, consisting of human-labeled 100k tweets per each. Our datasets are designed to have equal number of tweets distributed over five domains. The experimental results supported by statistical tests show that Transformer-based language models outperform conventional bag-of-words and neural models by at least 5% in English and 10% in Turkish for large-scale hate speech detection. The performance is also scalable to different training sizes, such that 98% of performance in English, and 97% in Turkish, are recovered when 20% of training instances are used. We further examine the generalization ability of cross-domain transfer among hate domains. We show that 96% of the performance of a target domain in average is recovered by other domains for English, and 92% for Turkish. Gender and religion are more successful to generalize to other domains, while sports fail most.