 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Hate Speech Detection with Cross-Domain Transfer
Mar 02, 2022


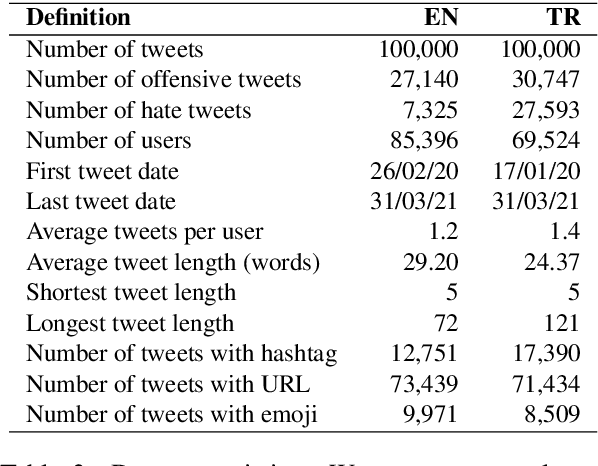
The performance of hate speech detection models relies on the datasets on which the models are trained. Existing datasets are mostly prepared with a limited number of instances or hate domains that define hate topics. This hinders large-scale analysis and transfer learning with respect to hate domains. In this study, we construct large-scale tweet datasets for hate speech detection in English and a low-resource language, Turkish, consisting of human-labeled 100k tweets per each. Our datasets are designed to have equal number of tweets distributed over five domains. The experimental results supported by statistical tests show that Transformer-based language models outperform conventional bag-of-words and neural models by at least 5% in English and 10% in Turkish for large-scale hate speech detection. The performance is also scalable to different training sizes, such that 98% of performance in English, and 97% in Turkish, are recovered when 20% of training instances are used. We further examine the generalization ability of cross-domain transfer among hate domains. We show that 96% of the performance of a target domain in average is recovered by other domains for English, and 92% for Turkish. Gender and religion are more successful to generalize to other domains, while sports fail most.