 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Tokenization on Language Models: An Analysis for Turkish
Apr 19, 2022
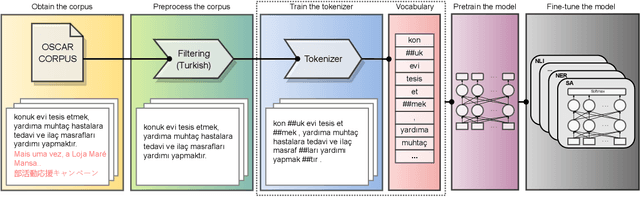

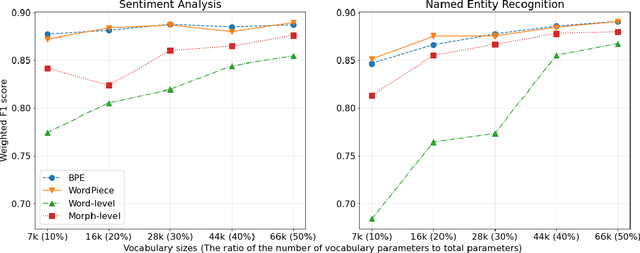
Tokenization is an important text preprocessing step to prepare input tokens for deep language models. WordPiece and BPE are de facto methods employed by important models, such as BERT and GPT. However, the impact of tokenization can be different for morphologically rich languages, such as Turkic languages, where many words can be generated by adding prefixes and suffixes. We compare five tokenizers at different granularity levels, i.e. their outputs vary from smallest pieces of characters to the surface form of words, including a Morphological-level tokenizer. We train these tokenizers and pretrain medium-sized language models using RoBERTa pretraining procedure on the Turkish split of the OSCAR corpus. We then fine-tune our models on six downstream tasks. Our experiments, supported by statistical tests, reveal that Morphological-level tokenizer has challenging performance with de facto tokenizers. Furthermore, we find that increasing the vocabulary size improves the performance of Morphological and Word-level tokenizers more than that of de facto tokenizers. The ratio of the number of vocabulary parameters to the total number of model parameters can be empirically chosen as 20% for de facto tokenizers and 40% for other tokenizers to obtain a reasonable trade-off between model size and performance.
ConQX: Semantic Expansion of Spoken Queries for Intent Detection based on Conditioned Text Generation
Sep 02, 2021


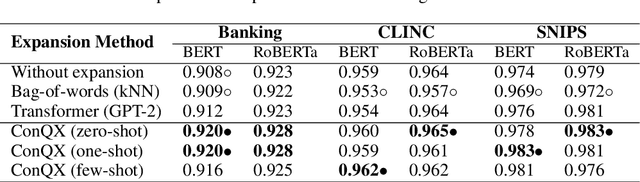
Intent detection of spoken queries is a challenging task due to their noisy structure and short length. To provide additional information regarding the query and enhance the performance of intent detection, we propose a method for semantic expansion of spoken queries, called ConQX, which utilizes the text generation ability of an auto-regressive language model, GPT-2. To avoid off-topic text generation, we condition the input query to a structured context with prompt mining. We then apply zero-shot, one-shot, and few-shot learning. We lastly use the expanded queries to fine-tune BERT and RoBERTa for intent detection. The experimental results show that the performance of intent detection can be improved by our semantic expansion method.