 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC-NLP at Multimodal Hate Speech Event Detection 2023: Multimodal Methods Boosted by Ensemble Learning, Syntactical and Entity Features
Jul 25, 2023
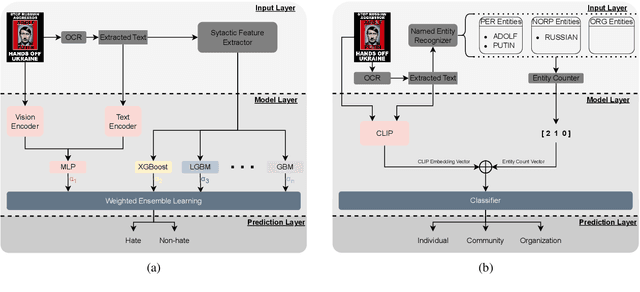


Text-embedded images can serve as a means of spreading hate speech, propaganda, and extremist beliefs. Throughout the Russia-Ukraine war, both opposing factions heavily relied on text-embedded images as a vehicle for spreading propaganda and hate speech. Ensuring the effective detection of hate speech and propaganda is of utmost importance to mitigate the negative effect of hate speech dissemination. In this paper, we outline our methodologies for two subtasks of Multimodal Hate Speech Event Detection 2023. For the first subtask, hate speech detection, we utilize multimodal deep learning models boosted by ensemble learning and syntactical text attributes. For the second subtask, target detection, we employ multimodal deep learning models boosted by named entity features. Through experimentation, we demonstrate the superior performance of our models compared to all textual, visual, and text-visual baselines employed in multimodal hate speech detection. Furthermore, our models achieve the first place in both subtasks on the final leaderboard of the shared task.
Tweets Under the Rubble: Detection of Messages Calling for Help in Earthquake Disaster
Feb 26, 2023The importance of social media is again exposed in the recent tragedy of the 2023 Turkey and Syria earthquake. Many victims who were trapped under the rubble called for help by posting messages in Twitter. We present an interactive tool to provide situational awareness for missing and trapped people, and disaster relief for rescue and donation efforts. The system (i) collects tweets, (ii) classifies the ones calling for help, (iii) extracts important entity tags, and (iv) visualizes them in an interactive map screen. Our initial experiments show that the performance in terms of the F1 score is up to 98.30 for tweet classification, and 84.32 for entity extraction. The demonstration, dataset, and other related files can be accessed at https://github.com/avaapm/deprem
Not Good Times for Lies: Misinformation Detection on the Russia-Ukraine War, COVID-19, and Refugees
Oct 11, 2022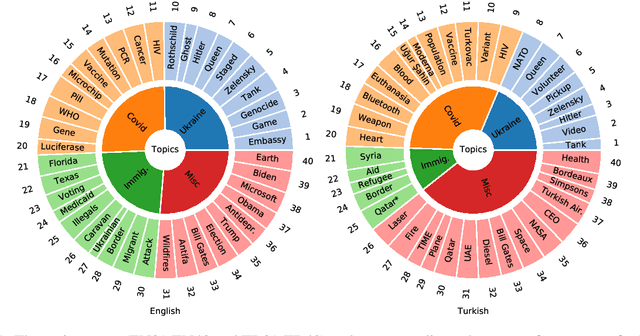
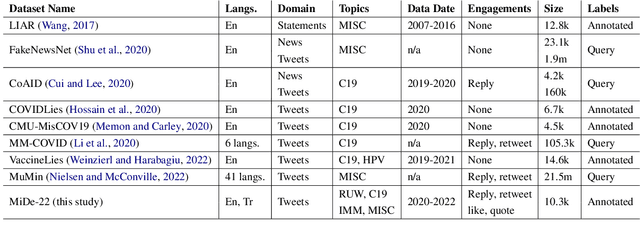
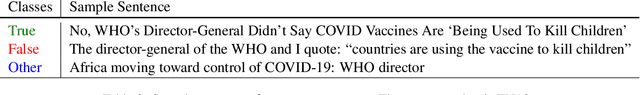

Misinformation spread in online social networks is an urgent-to-solve problem having harmful consequences that threaten human health, public safety, economics, and so on. In this study, we construct a novel dataset, called MiDe-22, having 5,284 English and 5,064 Turkish tweets with their misinformation labels under several recent events, including the Russia-Ukraine war, COVID-19 pandemic, and Refugees. Moreover, we provide the user engagements to the tweets in terms of likes, replies, retweets, and quotes. We present a detailed data analysis with descriptive statistics and temporal analysis, and provide the experimental results of a benchmark evaluation for misinformation detection on our novel dataset.
Impact of Tokenization on Language Models: An Analysis for Turkish
Apr 19, 2022
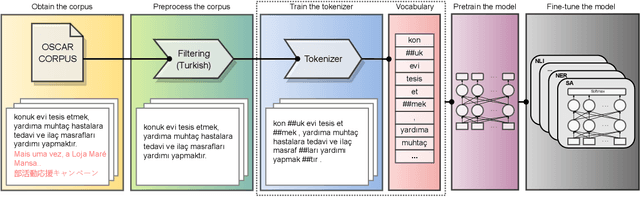

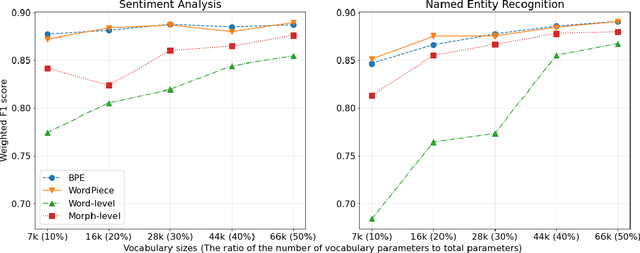
Tokenization is an important text preprocessing step to prepare input tokens for deep language models. WordPiece and BPE are de facto methods employed by important models, such as BERT and GPT. However, the impact of tokenization can be different for morphologically rich languages, such as Turkic languages, where many words can be generated by adding prefixes and suffixes. We compare five tokenizers at different granularity levels, i.e. their outputs vary from smallest pieces of characters to the surface form of words, including a Morphological-level tokenizer. We train these tokenizers and pretrain medium-sized language models using RoBERTa pretraining procedure on the Turkish split of the OSCAR corpus. We then fine-tune our models on six downstream tasks. Our experiments, supported by statistical tests, reveal that Morphological-level tokenizer has challenging performance with de facto tokenizers. Furthermore, we find that increasing the vocabulary size improves the performance of Morphological and Word-level tokenizers more than that of de facto tokenizers. The ratio of the number of vocabulary parameters to the total number of model parameters can be empirically chosen as 20% for de facto tokenizers and 40% for other tokenizers to obtain a reasonable trade-off between model size and performance.