 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-LoRA: Graph-Attentive Context Enhancement for Parameter-Efficient Adaptation of Medical Vision-Language Models
Mar 17, 2026The success of CLIP-like vision-language models (VLMs) on natural images has inspired medical counterparts, yet existing approaches largely fall into two extremes: specialist models trained on single-domain data, which capture domain-specific details but generalize poorly, and generalist medical VLMs trained on multi-domain data, which retain broad semantics but dilute fine-grained diagnostic cues. Bridging this specialization-generalization trade-off remains challenging. To address this problem, we propose ACE-LoRA, a parameter-efficient adaptation framework for generalist medical VLMs that maintains robust zero-shot generalization. ACE-LoRA integrates Low-Rank Adaptation (LoRA) modules into frozen image-text encoders and introduces an Attention-based Context Enhancement Hypergraph Neural Network (ACE-HGNN) module that captures higher-order contextual interactions beyond pairwise similarity to enrich global representations with localized diagnostic cues, addressing a key limitation of prior Parameter-Efficient Fine-Tuning (PEFT) methods that overlook fine-grained details. To further enhance cross-modal alignment, we formulate a label-guided InfoNCE loss to effectively suppress false negatives between semantically related image-text pairs. Despite adding only 0.95M trainable parameters, ACE-LoRA consistently outperforms state-of-the-art medical VLMs and PEFT baselines across zero-shot classification, segmentation, and detection benchmarks spanning multiple domains. Our code is available at https://github.com/icon-lab/ACE-LoRA.
Meta-Entity Driven Triplet Mining for Aligning Medical Vision-Language Models
Apr 22, 2025Diagnostic imaging relies on interpreting both images and radiology reports, but the growing data volumes place significant pressure on medical experts, yielding increased errors and workflow backlogs. Medical vision-language models (med-VLMs) have emerged as a powerful framework to efficiently process multimodal imaging data, particularly in chest X-ray (CXR) evaluations, albeit their performance hinges on how well image and text representations are aligned. Existing alignment methods, predominantly based on contrastive learning, prioritize separation between disease classes over segregation of fine-grained pathology attributes like location, size or severity, leading to suboptimal representations. Here, we propose MedTrim (Meta-entity-driven Triplet mining), a novel method that enhances image-text alignment through multimodal triplet learning synergistically guided by disease class as well as adjectival and directional pathology descriptors. Unlike common alignment methods that separate broad disease classes, MedTrim leverages structured meta-entity information to preserve subtle but clinically significant intra-class variations. For this purpose, we first introduce an ontology-based entity recognition module that extracts pathology-specific meta-entities from CXR reports, as annotations on pathology attributes are rare in public datasets. For refined sample selection in triplet mining, we then introduce a novel score function that captures an aggregate measure of inter-sample similarity based on disease classes and adjectival/directional descriptors. Lastly, we introduce a multimodal triplet alignment objective for explicit within- and cross-modal alignment between samples sharing detailed pathology characteristics. Our demonstrations indicate that MedTrim improves performance in downstream retrieval and classification tasks compared to state-of-the-art alignment methods.
Fast-FNet: Accelerating Transformer Encoder Models via Efficient Fourier Layers
Sep 26, 2022
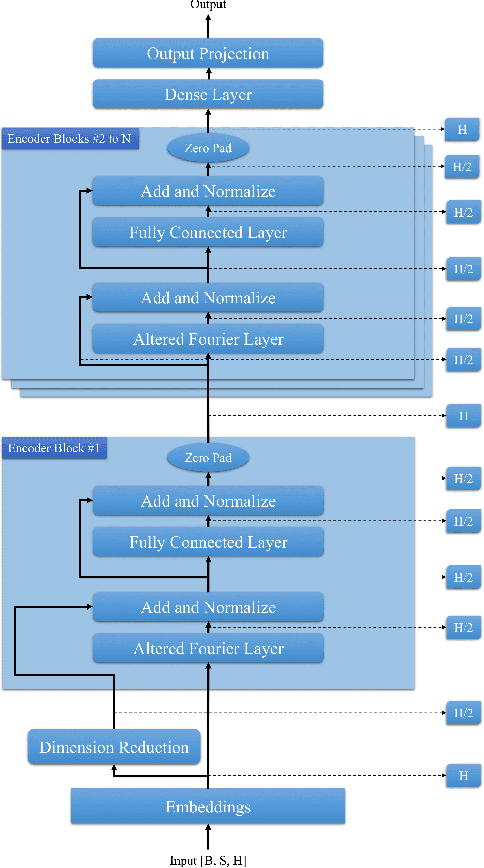
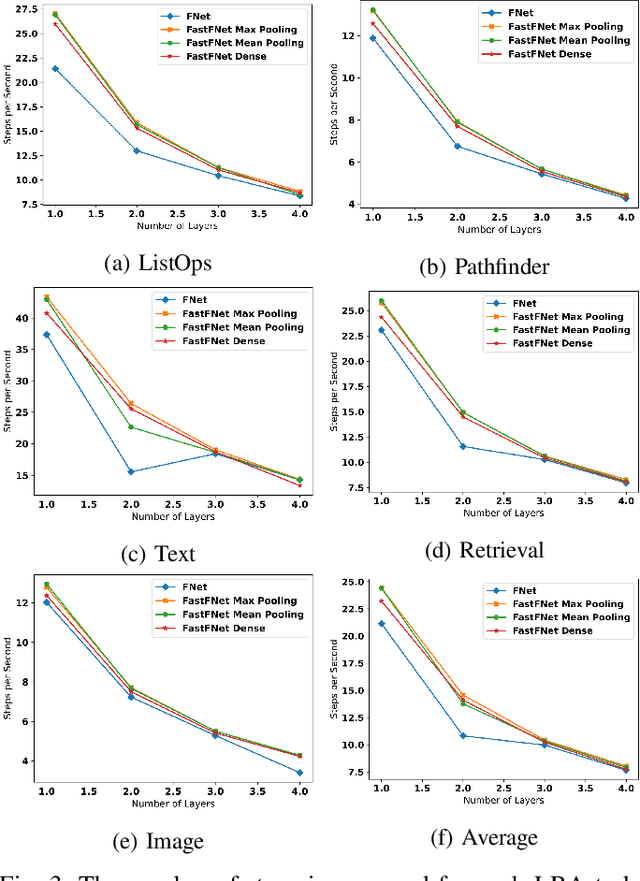
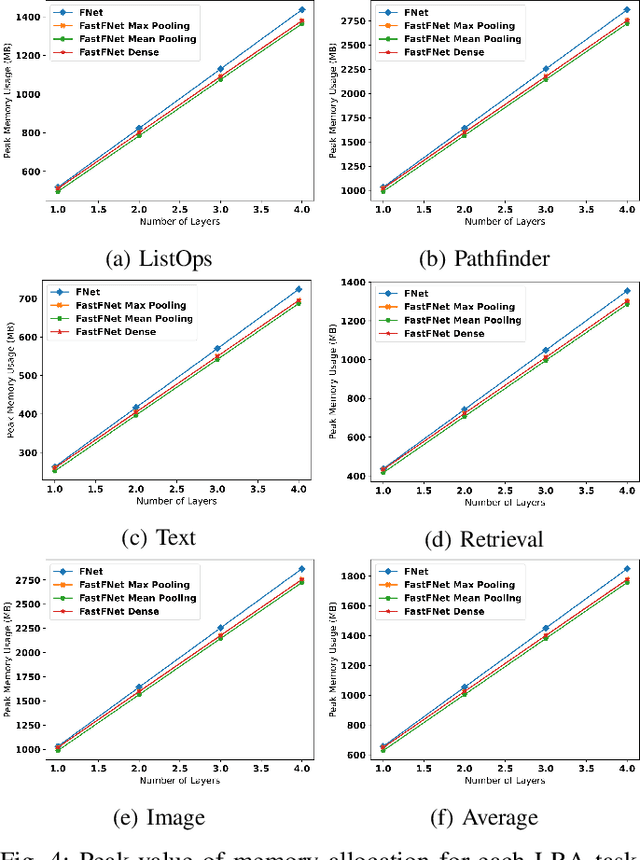
Transformer-based language models utilize the attention mechanism for substantial performance improvements in almost all natural language processing (NLP) tasks. Similar attention structures are also extensively studied in several other areas. Although the attention mechanism enhances the model performances significantly, its quadratic complexity prevents efficient processing of long sequences. Recent works focused on eliminating the disadvantages of computational inefficiency and showed that transformer-based models can still reach competitive results without the attention layer. A pioneering study proposed the FNet, which replaces the attention layer with the Fourier Transform (FT) in the transformer encoder architecture. FNet achieves competitive performances concerning the original transformer encoder model while accelerating training process by removing the computational burden of the attention mechanism. However, the FNet model ignores essential properties of the FT from the classical signal processing that can be leveraged to increase model efficiency further. We propose different methods to deploy FT efficiently in transformer encoder models. Our proposed architectures have smaller number of model parameters, shorter training times, less memory usage, and some additional performance improvements. We demonstrate these improvements through extensive experiments on common benchmarks.
Unsupervised Simplification of Legal Texts
Sep 01, 2022
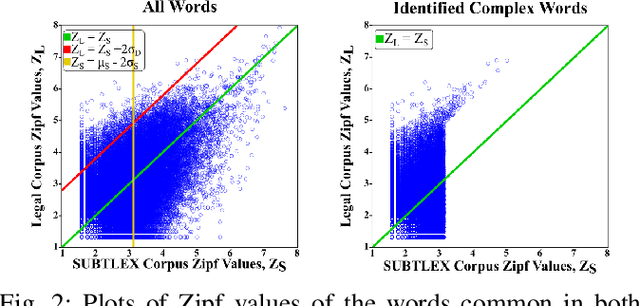
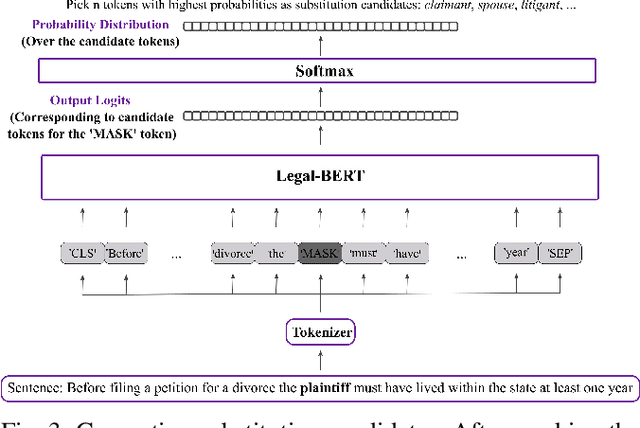

The processing of legal texts has been developing as an emerging field in natural language processing (NLP). Legal texts contain unique jargon and complex linguistic attributes in vocabulary, semantics, syntax, and morphology. Therefore, the development of text simplification (TS) methods specific to the legal domain is of paramount importance for facilitating comprehension of legal text by ordinary people and providing inputs to high-level models for mainstream legal NLP applications. While a recent study proposed a rule-based TS method for legal text, learning-based TS in the legal domain has not been considered previously. Here we introduce an unsupervised simplification method for legal texts (USLT). USLT performs domain-specific TS by replacing complex words and splitting long sentences. To this end, USLT detects complex words in a sentence, generates candidates via a masked-transformer model, and selects a candidate for substitution based on a rank score. Afterward, USLT recursively decomposes long sentences into a hierarchy of shorter core and context sentences while preserving semantic meaning. We demonstrate that USLT outperforms state-of-the-art domain-general TS methods in text simplicity while keeping the semantics intact.
Joint Time-Vertex Fractional Fourier Transform
Mar 15, 2022

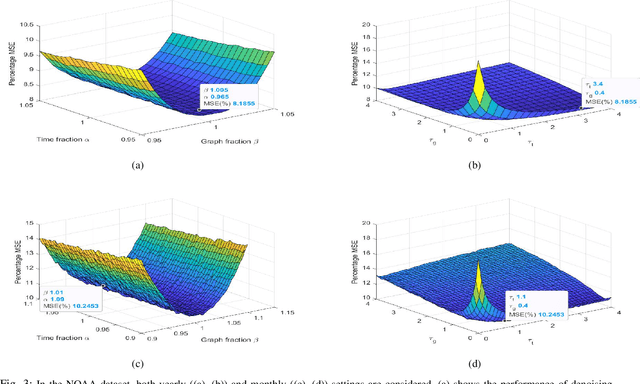
Graphs signal processing successfully captures high-dimensional data on non-Euclidean domains by using graph signals defined on graph vertices. However, data sources on each vertex can also continually provide time-series signals such that graph signals on each vertex are now time-series signals. Joint time-vertex Fourier transform (JFT) and the associated framework of time-vertex signal processing enable us to study such signals defined on joint time-vertex domains by providing spectral analysis. Just as the fractional Fourier transform (FRT) generalizes the ordinary Fourier transform (FT), we propose the joint time-vertex fractional Fourier transform (JFRT) as a generalization to the JFT. JFRT provides an additional fractional analysis tool for joint time-vertex processing by extending both temporal and vertex domain Fourier analysis to fractional orders. We theoretically show that the proposed JFRT generalizes the JFT and satisfies the properties of index additivity, reversibility, reduction to identity, and unitarity (for certain graph topologies). We provide theoretical derivations for JFRT-based denoising as well as computational cost analysis. Results of numerical experiments are also presented to demonstrate the benefits of JFRT.
Multi-Label Sentiment Analysis on 100 Languages with Dynamic Weighting for Label Imbalance
Aug 26, 2020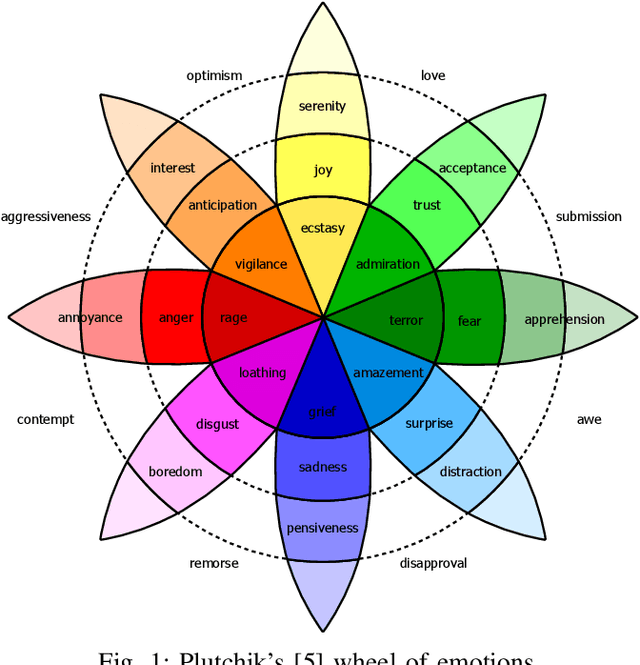
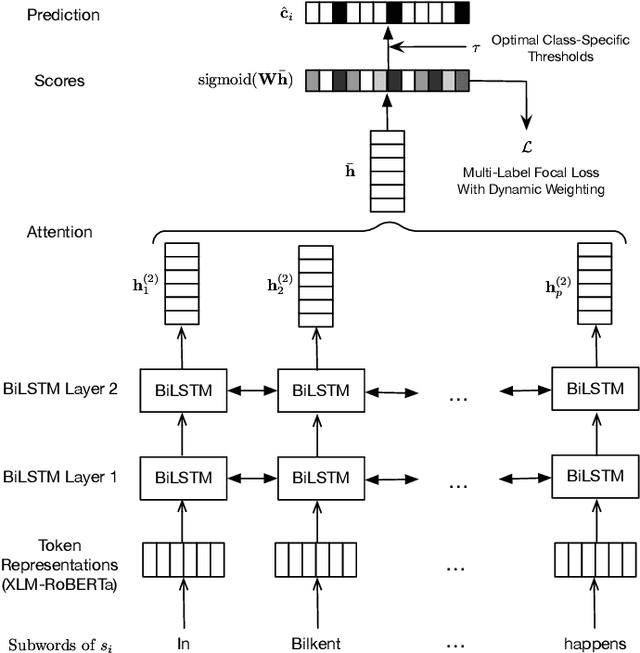
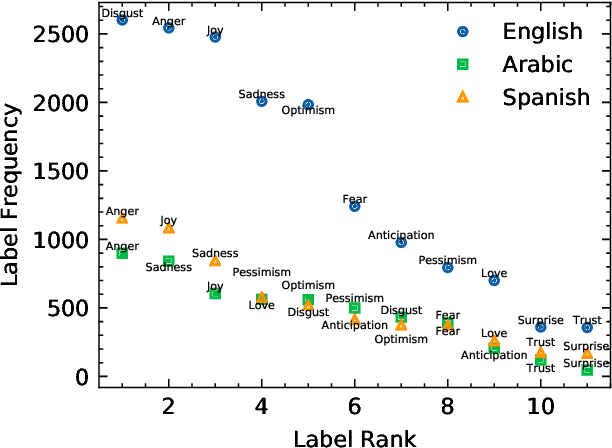
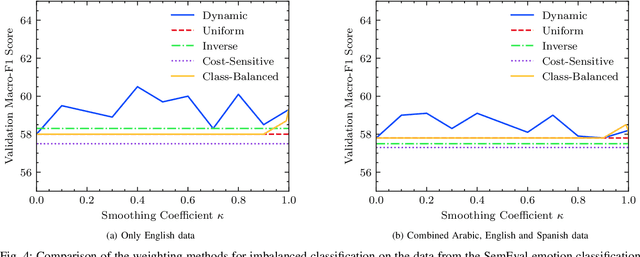
We investigate cross-lingual sentiment analysis, which has attracted significant attention due to its applications in various areas including market research, politics and social sciences. In particular, we introduce a sentiment analysis framework in multi-label setting as it obeys Plutchik wheel of emotions. We introduce a novel dynamic weighting method that balances the contribution from each class during training, unlike previous static weighting methods that assign non-changing weights based on their class frequency. Moreover, we adapt the focal loss that favors harder instances from single-label object recognition literature to our multi-label setting. Furthermore, we derive a method to choose optimal class-specific thresholds that maximize the macro-f1 score in linear time complexity. Through an extensive set of experiments, we show that our method obtains the state-of-the-art performance in 7 of 9 metrics in 3 different languages using a single model compared to the common baselines and the best-performing methods in the SemEval competition. We publicly share our code for our model, which can perform sentiment analysis in 100 languages, to facilitate further research.
Deep Iterative Reconstruction for Phase Retrieval
Apr 25, 2019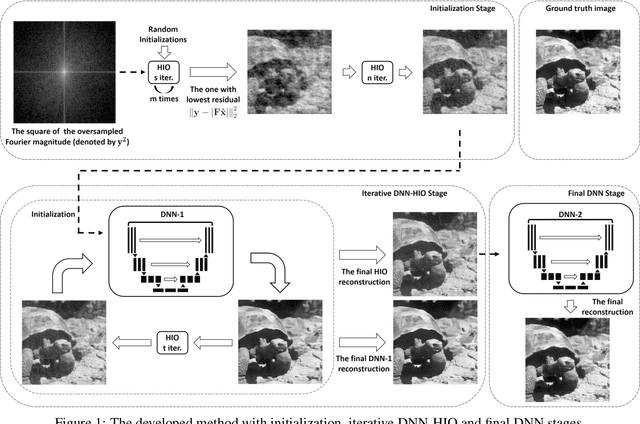
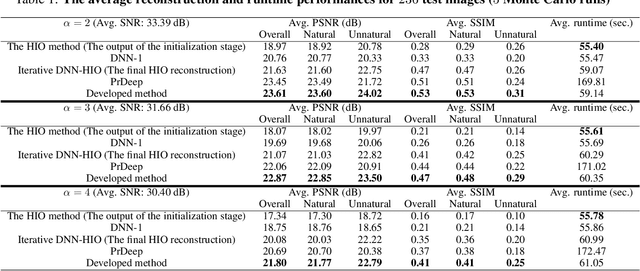
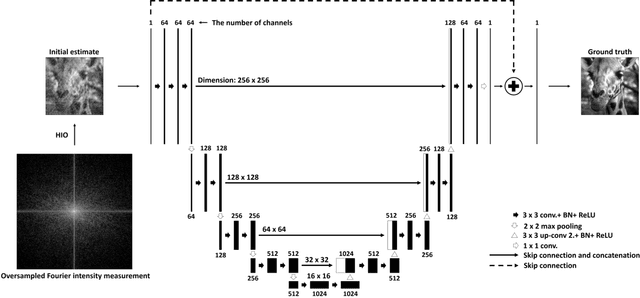

Classical phase retrieval problem is the recovery of a constrained image from the magnitude of its Fourier transform. Although there are several well-known phase retrieval algorithms including the hybrid input-output (HIO) method, the reconstruction performance is generally sensitive to initialization and measurement noise. Recently, deep neural networks (DNNs) have been shown to provide state-of-the-art performance in solving several inverse problems such as denoising, deconvolution, and superresolution. In this work, we develop a phase retrieval algorithm that utilizes DNNs in an iterative manner with the model-based HIO method. The DNN architectures, which are trained to remove the HIO artifacts, are used iteratively with the HIO method to improve the reconstructions. Numerical results demonstrate the effectiveness of our approach, which has little additional computational cost compared to the HIO method. Our approach not only achieves state-of-the-art reconstruction performance but also is more robust to different initialization and noise levels.
Imparting Interpretability to Word Embeddings
Jul 19, 2018
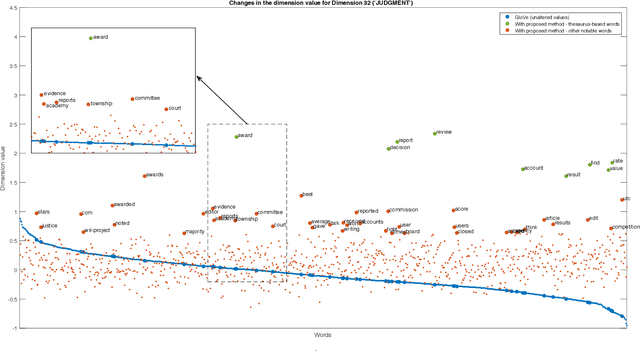
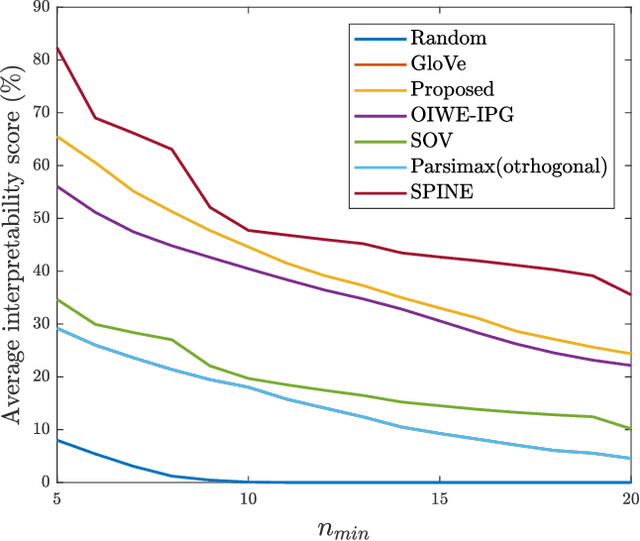
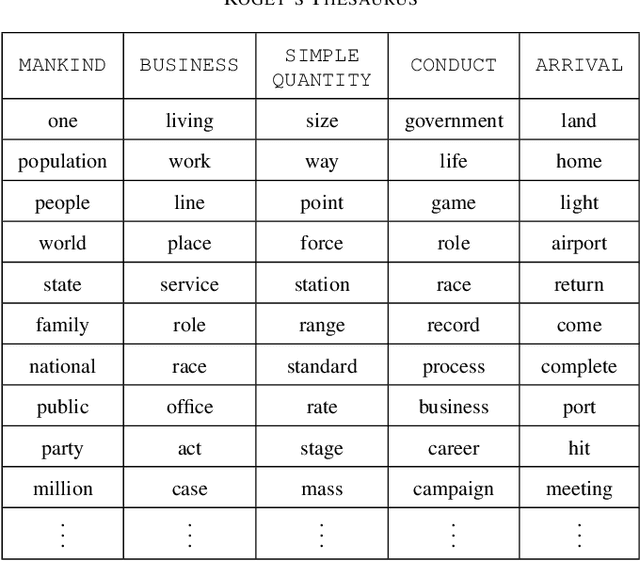
As an ubiquitous method in natural language processing, word embeddings are extensively employed to map semantic properties of words into a dense vector representation. They capture semantic and syntactic relations among words but the vector corresponding to the words are only meaningful relative to each other. Neither the vector nor its dimensions have any absolute, interpretable meaning. We introduce an additive modification to the objective function of the embedding learning algorithm that encourages the embedding vectors of words that are semantically related a predefined concept to take larger values along a specified dimension, while leaving the original semantic learning mechanism mostly unaffected. In other words, we align words that are already determined to be related, along predefined concepts. Therefore, we impart interpretability to the word embedding by assigning meaning to its vector dimensions. The predefined concepts are derived from an external lexical resource, which in this paper is chosen as Roget's Thesaurus. We observe that alignment along the chosen concepts is not limited to words in the Thesaurus and extends to other related words as well. We quantify the extent of interpretability and assignment of meaning from our experimental results. We also demonstrate the preservation of semantic coherence of the resulting vector space by using word-analogy and word-similarity tests. These tests show that the interpretability-imparted word embeddings that are obtained by the proposed framework do not sacrifice performances in common benchmark tests.