 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes He Wink or Does He Nod? A Challenging Benchmark for Evaluating Word Understanding of Language Models
Feb 06, 2021
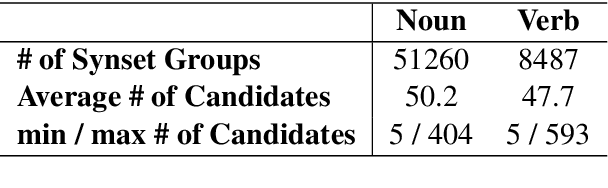

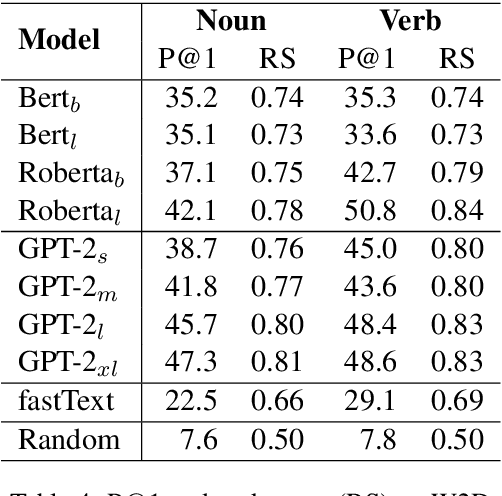
Recent progress in pretraining language models on large corpora has resulted in large performance gains on many NLP tasks. These large models acquire linguistic knowledge during pretraining, which helps to improve performance on downstream tasks via fine-tuning. To assess what kind of knowledge is acquired, language models are commonly probed by querying them with `fill in the blank' style cloze questions. Existing probing datasets mainly focus on knowledge about relations between words and entities. We introduce WDLMPro (Word Definition Language Model Probing) to evaluate word understanding directly using dictionary definitions of words. In our experiments, three popular pretrained language models struggle to match words and their definitions. This indicates that they understand many words poorly and that our new probing task is a difficult challenge that could help guide research on LMs in the future.
Imparting Interpretability to Word Embeddings
Jul 19, 2018
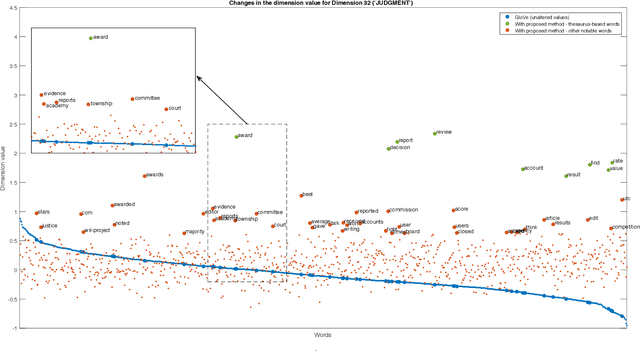
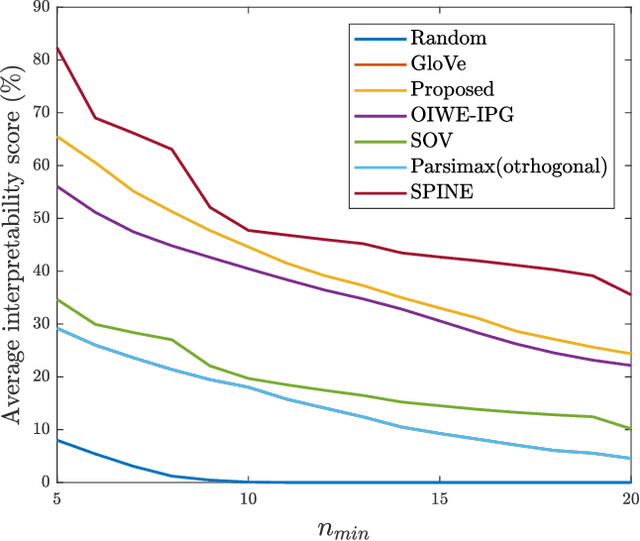
As an ubiquitous method in natural language processing, word embeddings are extensively employed to map semantic properties of words into a dense vector representation. They capture semantic and syntactic relations among words but the vector corresponding to the words are only meaningful relative to each other. Neither the vector nor its dimensions have any absolute, interpretable meaning. We introduce an additive modification to the objective function of the embedding learning algorithm that encourages the embedding vectors of words that are semantically related a predefined concept to take larger values along a specified dimension, while leaving the original semantic learning mechanism mostly unaffected. In other words, we align words that are already determined to be related, along predefined concepts. Therefore, we impart interpretability to the word embedding by assigning meaning to its vector dimensions. The predefined concepts are derived from an external lexical resource, which in this paper is chosen as Roget's Thesaurus. We observe that alignment along the chosen concepts is not limited to words in the Thesaurus and extends to other related words as well. We quantify the extent of interpretability and assignment of meaning from our experimental results. We also demonstrate the preservation of semantic coherence of the resulting vector space by using word-analogy and word-similarity tests. These tests show that the interpretability-imparted word embeddings that are obtained by the proposed framework do not sacrifice performances in common benchmark tests.
Semantic Structure and Interpretability of Word Embeddings
May 16, 2018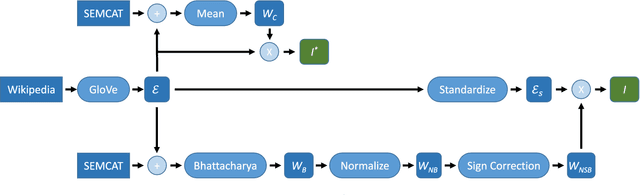
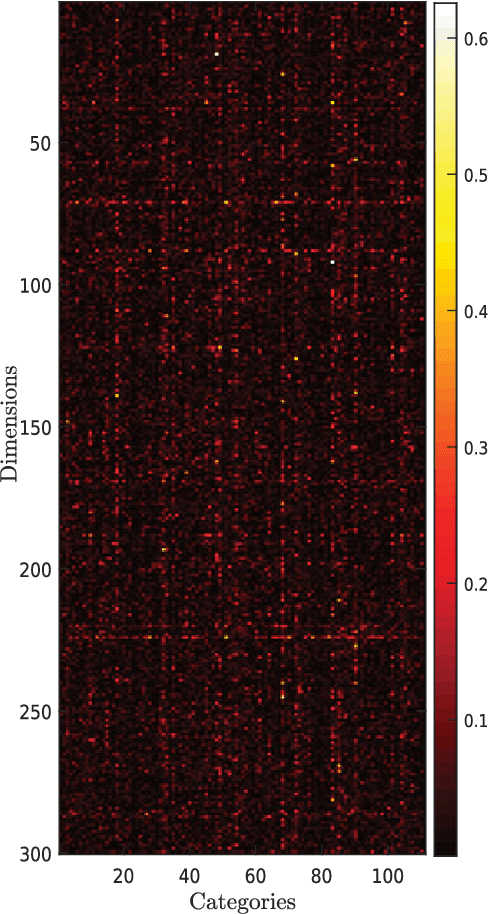
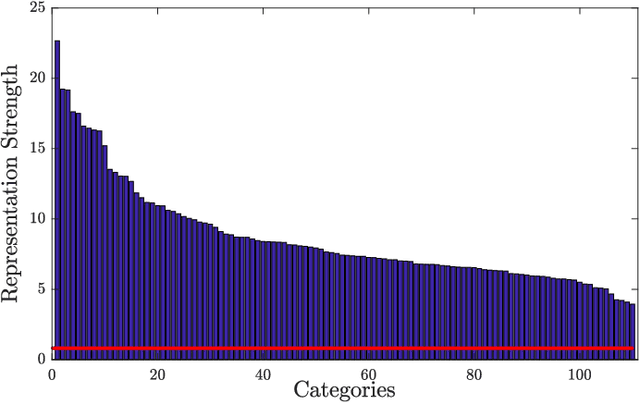
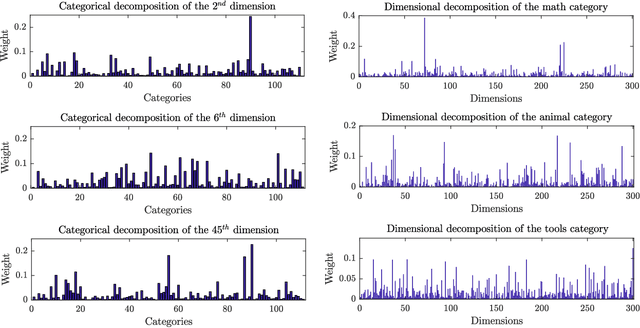
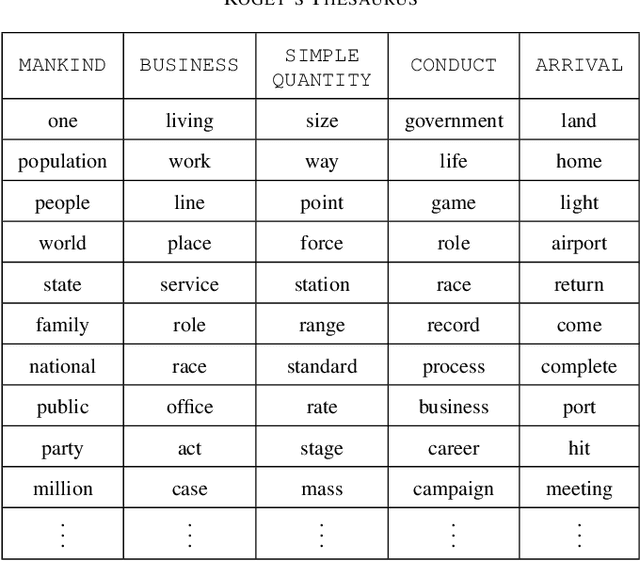
Dense word embeddings, which encode semantic meanings of words to low dimensional vector spaces have become very popular in natural language processing (NLP) research due to their state-of-the-art performances in many NLP tasks. Word embeddings are substantially successful in capturing semantic relations among words, so a meaningful semantic structure must be present in the respective vector spaces. However, in many cases, this semantic structure is broadly and heterogeneously distributed across the embedding dimensions, which makes interpretation a big challenge. In this study, we propose a statistical method to uncover the latent semantic structure in the dense word embeddings. To perform our analysis we introduce a new dataset (SEMCAT) that contains more than 6500 words semantically grouped under 110 categories. We further propose a method to quantify the interpretability of the word embeddings; the proposed method is a practical alternative to the classical word intrusion test that requires human intervention.
* 11 Pages, 8 Figures, accepted by IEEE/ACM Transactions on Audio, Speech, and Language Processing