 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImparting Interpretability to Word Embeddings
Paper and Code
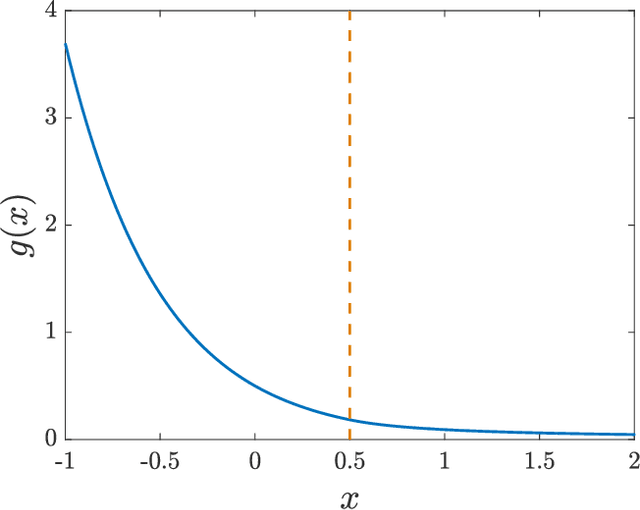
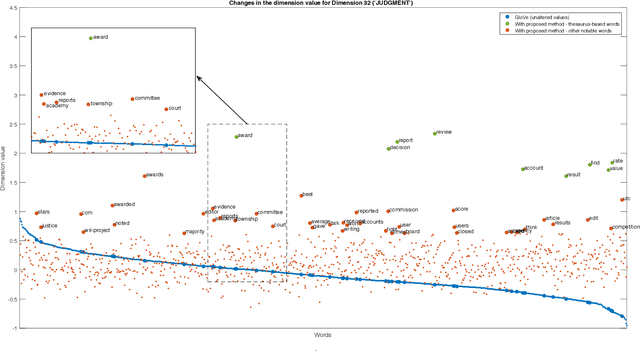
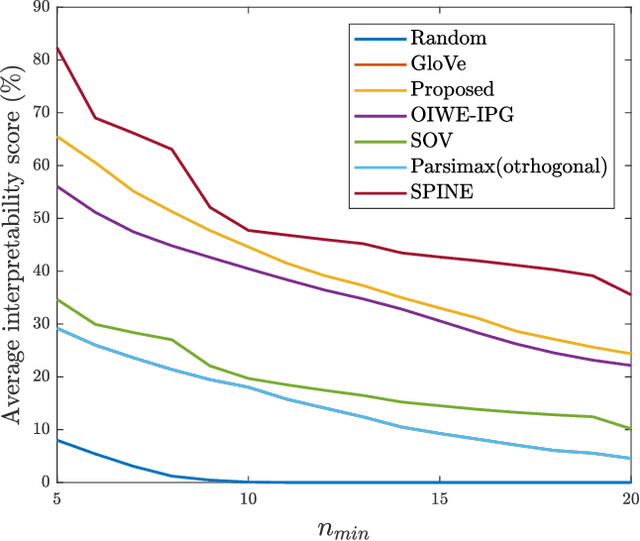
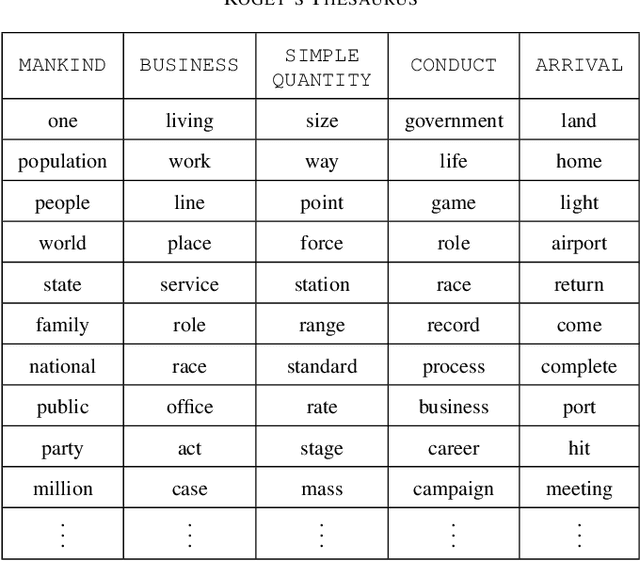
As an ubiquitous method in natural language processing, word embeddings are extensively employed to map semantic properties of words into a dense vector representation. They capture semantic and syntactic relations among words but the vector corresponding to the words are only meaningful relative to each other. Neither the vector nor its dimensions have any absolute, interpretable meaning. We introduce an additive modification to the objective function of the embedding learning algorithm that encourages the embedding vectors of words that are semantically related a predefined concept to take larger values along a specified dimension, while leaving the original semantic learning mechanism mostly unaffected. In other words, we align words that are already determined to be related, along predefined concepts. Therefore, we impart interpretability to the word embedding by assigning meaning to its vector dimensions. The predefined concepts are derived from an external lexical resource, which in this paper is chosen as Roget's Thesaurus. We observe that alignment along the chosen concepts is not limited to words in the Thesaurus and extends to other related words as well. We quantify the extent of interpretability and assignment of meaning from our experimental results. We also demonstrate the preservation of semantic coherence of the resulting vector space by using word-analogy and word-similarity tests. These tests show that the interpretability-imparted word embeddings that are obtained by the proposed framework do not sacrifice performances in common benchmark tests.