 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes He Wink or Does He Nod? A Challenging Benchmark for Evaluating Word Understanding of Language Models
Paper and Code
Feb 06, 2021
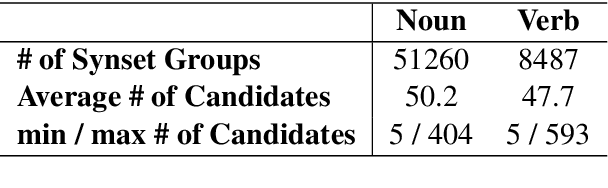

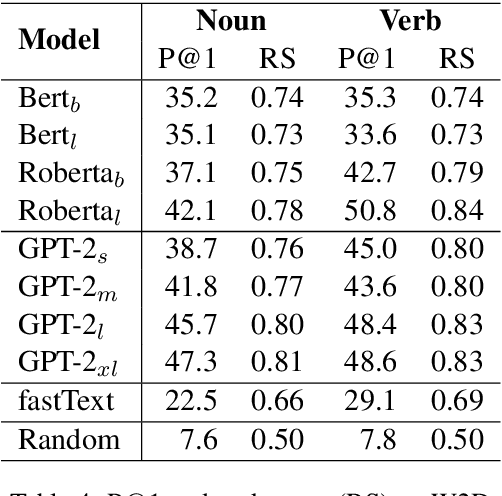
Recent progress in pretraining language models on large corpora has resulted in large performance gains on many NLP tasks. These large models acquire linguistic knowledge during pretraining, which helps to improve performance on downstream tasks via fine-tuning. To assess what kind of knowledge is acquired, language models are commonly probed by querying them with `fill in the blank' style cloze questions. Existing probing datasets mainly focus on knowledge about relations between words and entities. We introduce WDLMPro (Word Definition Language Model Probing) to evaluate word understanding directly using dictionary definitions of words. In our experiments, three popular pretrained language models struggle to match words and their definitions. This indicates that they understand many words poorly and that our new probing task is a difficult challenge that could help guide research on LMs in the future.