 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Structure and Interpretability of Word Embeddings
Paper and Code
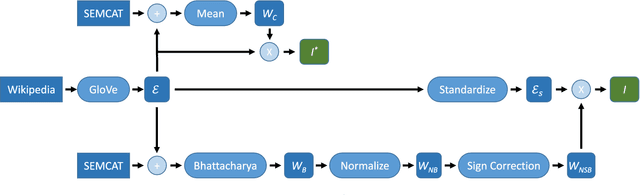
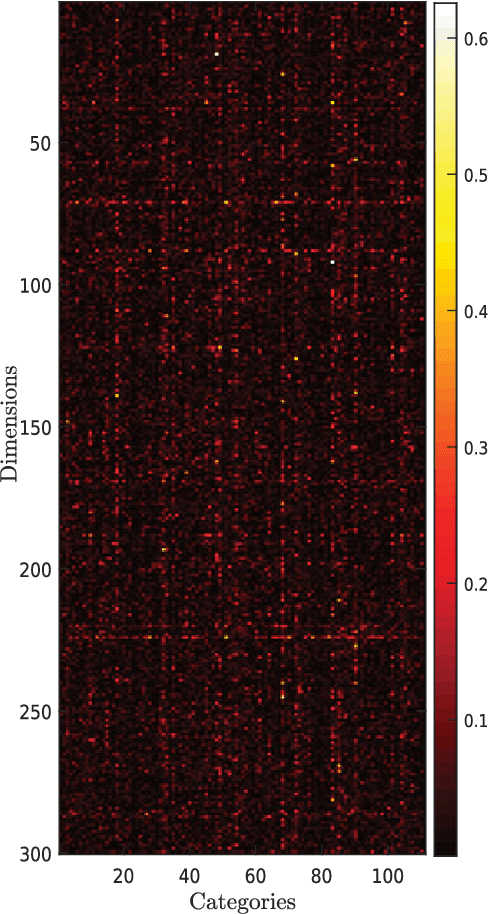
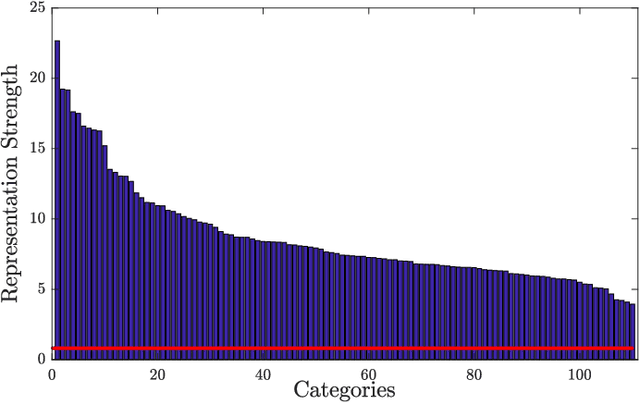
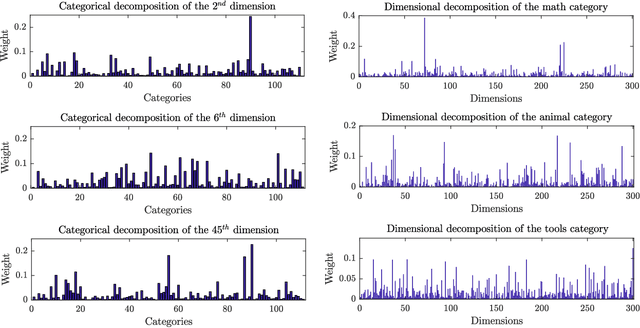
Dense word embeddings, which encode semantic meanings of words to low dimensional vector spaces have become very popular in natural language processing (NLP) research due to their state-of-the-art performances in many NLP tasks. Word embeddings are substantially successful in capturing semantic relations among words, so a meaningful semantic structure must be present in the respective vector spaces. However, in many cases, this semantic structure is broadly and heterogeneously distributed across the embedding dimensions, which makes interpretation a big challenge. In this study, we propose a statistical method to uncover the latent semantic structure in the dense word embeddings. To perform our analysis we introduce a new dataset (SEMCAT) that contains more than 6500 words semantically grouped under 110 categories. We further propose a method to quantify the interpretability of the word embeddings; the proposed method is a practical alternative to the classical word intrusion test that requires human intervention.