 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUFFICIENT: A scan-specific unsupervised deep learning framework for high-resolution 3D isotropic fetal brain MRI reconstruction
May 26, 2025High-quality 3D fetal brain MRI reconstruction from motion-corrupted 2D slices is crucial for clinical diagnosis. Reliable slice-to-volume registration (SVR)-based motion correction and super-resolution reconstruction (SRR) methods are essential. Deep learning (DL) has demonstrated potential in enhancing SVR and SRR when compared to conventional methods. However, it requires large-scale external training datasets, which are difficult to obtain for clinical fetal MRI. To address this issue, we propose an unsupervised iterative SVR-SRR framework for isotropic HR volume reconstruction. Specifically, SVR is formulated as a function mapping a 2D slice and a 3D target volume to a rigid transformation matrix, which aligns the slice to the underlying location in the target volume. The function is parameterized by a convolutional neural network, which is trained by minimizing the difference between the volume slicing at the predicted position and the input slice. In SRR, a decoding network embedded within a deep image prior framework is incorporated with a comprehensive image degradation model to produce the high-resolution (HR) volume. The deep image prior framework offers a local consistency prior to guide the reconstruction of HR volumes. By performing a forward degradation model, the HR volume is optimized by minimizing loss between predicted slices and the observed slices. Comprehensive experiments conducted on large-magnitude motion-corrupted simulation data and clinical data demonstrate the superior performance of the proposed framework over state-of-the-art fetal brain reconstruction frameworks.
Meta-Entity Driven Triplet Mining for Aligning Medical Vision-Language Models
Apr 22, 2025Diagnostic imaging relies on interpreting both images and radiology reports, but the growing data volumes place significant pressure on medical experts, yielding increased errors and workflow backlogs. Medical vision-language models (med-VLMs) have emerged as a powerful framework to efficiently process multimodal imaging data, particularly in chest X-ray (CXR) evaluations, albeit their performance hinges on how well image and text representations are aligned. Existing alignment methods, predominantly based on contrastive learning, prioritize separation between disease classes over segregation of fine-grained pathology attributes like location, size or severity, leading to suboptimal representations. Here, we propose MedTrim (Meta-entity-driven Triplet mining), a novel method that enhances image-text alignment through multimodal triplet learning synergistically guided by disease class as well as adjectival and directional pathology descriptors. Unlike common alignment methods that separate broad disease classes, MedTrim leverages structured meta-entity information to preserve subtle but clinically significant intra-class variations. For this purpose, we first introduce an ontology-based entity recognition module that extracts pathology-specific meta-entities from CXR reports, as annotations on pathology attributes are rare in public datasets. For refined sample selection in triplet mining, we then introduce a novel score function that captures an aggregate measure of inter-sample similarity based on disease classes and adjectival/directional descriptors. Lastly, we introduce a multimodal triplet alignment objective for explicit within- and cross-modal alignment between samples sharing detailed pathology characteristics. Our demonstrations indicate that MedTrim improves performance in downstream retrieval and classification tasks compared to state-of-the-art alignment methods.
Physics-Driven Autoregressive State Space Models for Medical Image Reconstruction
Dec 12, 2024Medical image reconstruction from undersampled acquisitions is an ill-posed problem that involves inversion of the imaging operator linking measurement and image domains. In recent years, physics-driven (PD) models have gained prominence in learning-based reconstruction given their enhanced balance between efficiency and performance. For reconstruction, PD models cascade data-consistency modules that enforce fidelity to acquired data based on the imaging operator, with network modules that process feature maps to alleviate image artifacts due to undersampling. Success in artifact suppression inevitably depends on the ability of the network modules to tease apart artifacts from underlying tissue structures, both of which can manifest contextual relations over broad spatial scales. Convolutional modules that excel at capturing local correlations are relatively insensitive to non-local context. While transformers promise elevated sensitivity to non-local context, practical implementations often suffer from a suboptimal trade-off between local and non-local sensitivity due to intrinsic model complexity. Here, we introduce a novel physics-driven autoregressive state space model (MambaRoll) for enhanced fidelity in medical image reconstruction. In each cascade of an unrolled architecture, MambaRoll employs an autoregressive framework based on physics-driven state space modules (PSSM), where PSSMs efficiently aggregate contextual features at a given spatial scale while maintaining fidelity to acquired data, and autoregressive prediction of next-scale feature maps from earlier spatial scales enhance capture of multi-scale contextual features. Demonstrations on accelerated MRI and sparse-view CT reconstructions indicate that MambaRoll outperforms state-of-the-art PD methods based on convolutional, transformer and conventional SSM modules.
Deep Clustering via Center-Oriented Margin Free-Triplet Loss for Skin Lesion Detection in Highly Imbalanced Datasets
Apr 03, 2022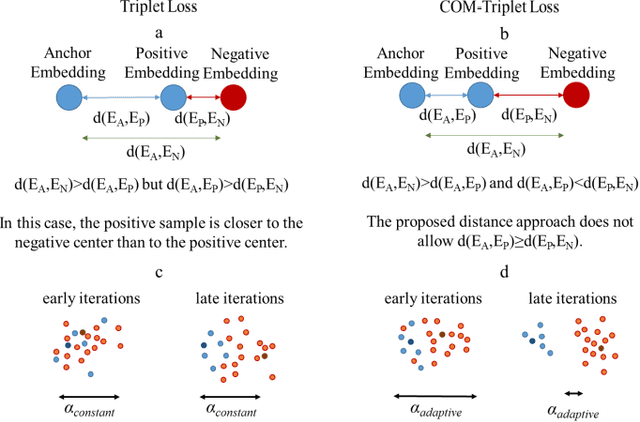
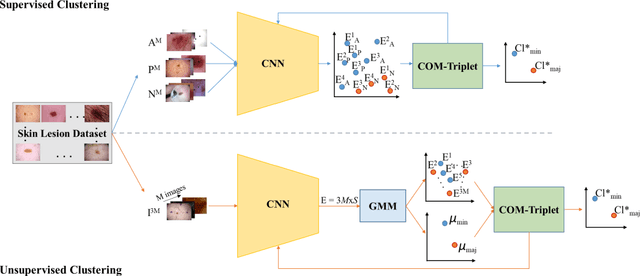
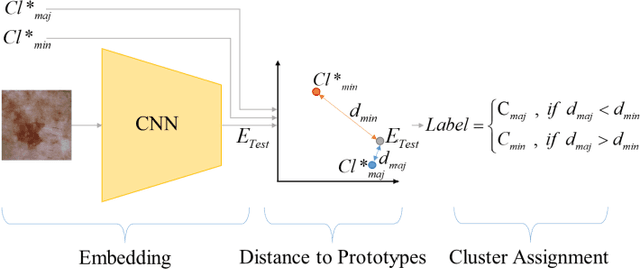
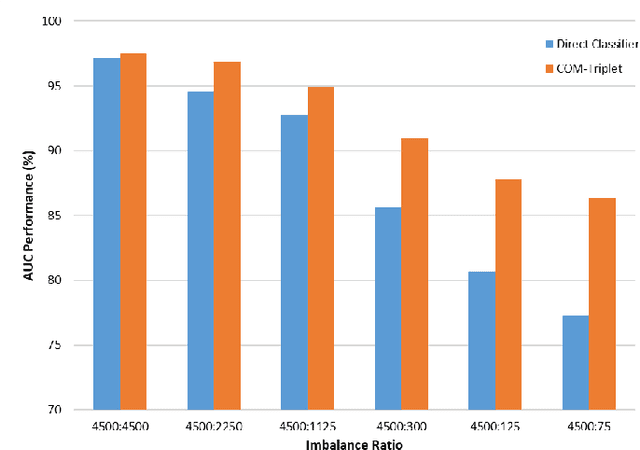
Melanoma is a fatal skin cancer that is curable and has dramatically increasing survival rate when diagnosed at early stages. Learning-based methods hold significant promise for the detection of melanoma from dermoscopic images. However, since melanoma is a rare disease, existing databases of skin lesions predominantly contain highly imbalanced numbers of benign versus malignant samples. In turn, this imbalance introduces substantial bias in classification models due to the statistical dominance of the majority class. To address this issue, we introduce a deep clustering approach based on the latent-space embedding of dermoscopic images. Clustering is achieved using a novel center-oriented margin-free triplet loss (COM-Triplet) enforced on image embeddings from a convolutional neural network backbone. The proposed method aims to form maximally-separated cluster centers as opposed to minimizing classification error, so it is less sensitive to class imbalance. To avoid the need for labeled data, we further propose to implement COM-Triplet based on pseudo-labels generated by a Gaussian mixture model. Comprehensive experiments show that deep clustering with COM-Triplet loss outperforms clustering with triplet loss, and competing classifiers in both supervised and unsupervised settings.
Fused Deep Features Based Classification Framework for COVID-19 Classification with Optimized MLP
Mar 15, 2021



The new type of Coronavirus disease called COVID-19 continues to spread quite rapidly. Although it shows some specific symptoms, this disease, which can show different symptoms in almost every individual, has caused hundreds of thousands of patients to die. Although healthcare professionals work hard to prevent further loss of life, the rate of disease spread is very high. For this reason, the help of computer aided diagnosis (CAD) and artificial intelligence (AI) algorithms is vital. In this study, a method based on optimization of convolutional neural network (CNN) architecture, which is the most effective image analysis method of today, is proposed to fulfill the mentioned COVID-19 detection needs. First, COVID-19 images are trained using ResNet-50 and VGG-16 architectures. Then, features in the last layer of these two architectures are combined with feature fusion. These new image features matrices obtained with feature fusion are classified for COVID detection. A multi-layer perceptron (MLP) structure optimized by the whale optimization algorithm is used for the classification process. The obtained results show that the performance of the proposed framework is almost 4.5% higher than VGG-16 performance and almost 3.5% higher than ResNet-50 performance.
Coronavirus (COVID-19) Classification using Deep Features Fusion and Ranking Technique
Apr 07, 2020

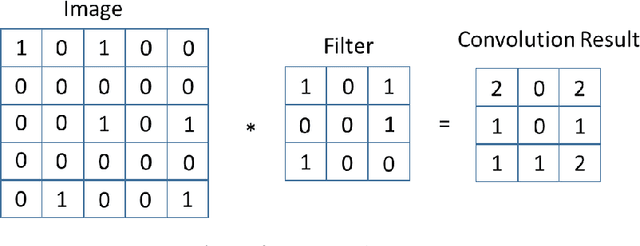

Coronavirus (COVID-19) emerged towards the end of 2019. World Health Organization (WHO) was identified it as a global epidemic. Consensus occurred in the opinion that using Computerized Tomography (CT) techniques for early diagnosis of pandemic disease gives both fast and accurate results. It was stated by expert radiologists that COVID-19 displays different behaviours in CT images. In this study, a novel method was proposed as fusing and ranking deep features to detect COVID-19 in early phase. 16x16 (Subset-1) and 32x32 (Subset-2) patches were obtained from 150 CT images to generate sub-datasets. Within the scope of the proposed method, 3000 patch images have been labelled as CoVID-19 and No finding for using in training and testing phase. Feature fusion and ranking method have been applied in order to increase the performance of the proposed method. Then, the processed data was classified with a Support Vector Machine (SVM). According to other pre-trained Convolutional Neural Network (CNN) models used in transfer learning, the proposed method shows high performance on Subset-2 with 98.27% accuracy, 98.93% sensitivity, 97.60% specificity, 97.63% precision, 98.28% F1-score and 96.54% Matthews Correlation Coefficient (MCC) metrics.
Coronavirus (COVID-19) Classification using CT Images by Machine Learning Methods
Mar 20, 2020
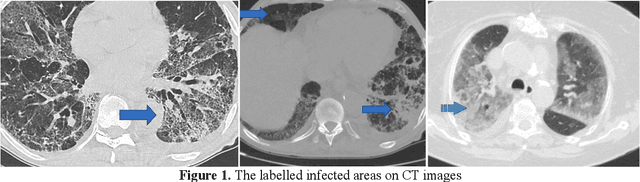


This study presents early phase detection of Coronavirus (COVID-19), which is named by World Health Organization (WHO), by machine learning methods. The detection process was implemented on abdominal Computed Tomography (CT) images. The expert radiologists detected from CT images that COVID-19 shows different behaviours from other viral pneumonia. Therefore, the clinical experts specify that COV\.ID-19 virus needs to be diagnosed in early phase. For detection of the COVID-19, four different datasets were formed by taking patches sized as 16x16, 32x32, 48x48, 64x64 from 150 CT images. The feature extraction process was applied to patches to increase the classification performance. Grey Level Co-occurrence Matrix (GLCM), Local Directional Pattern (LDP), Grey Level Run Length Matrix (GLRLM), Grey-Level Size Zone Matrix (GLSZM), and Discrete Wavelet Transform (DWT) algorithms were used as feature extraction methods. Support Vector Machines (SVM) classified the extracted features. 2-fold, 5-fold and 10-fold cross-validations were implemented during the classification process. Sensitivity, specificity, accuracy, precision, and F-score metrics were used to evaluate the classification performance. The best classification accuracy was obtained as 99.68% with 10-fold cross-validation and GLSZM feature extraction method.