 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Autoregressive Transformers for Model-Agnostic Federated MRI Reconstruction
Feb 06, 2025Although learning-based models hold great promise for MRI reconstruction, single-site models built on limited local datasets often suffer from poor generalization. This challenge has spurred interest in collaborative model training on multi-site datasets via federated learning (FL) -- a privacy-preserving framework that aggregates model updates instead of sharing imaging data. Conventional FL builds a global model by aggregating locally trained model weights, inherently constraining all sites to a homogeneous model architecture. This rigid homogeneity requirement forces sites to forgo architectures tailored to their compute infrastructure and application-specific demands. Consequently, existing FL methods for MRI reconstruction fail to support model-heterogeneous settings, where individual sites are allowed to use distinct architectures. To overcome this fundamental limitation, here we introduce FedGAT, a novel model-agnostic FL technique based on generative autoregressive transformers. FedGAT decentralizes the training of a global generative prior that captures the distribution of multi-site MR images. For enhanced fidelity, we propose a novel site-prompted GAT prior that controllably synthesizes MR images from desired sites via autoregressive prediction across spatial scales. Each site then trains its site-specific reconstruction model -- using its preferred architecture -- on a hybrid dataset comprising the local MRI dataset and GAT-generated synthetic MRI datasets for other sites. Comprehensive experiments on multi-institutional datasets demonstrate that FedGAT supports flexible collaborations while enjoying superior within-site and across-site reconstruction performance compared to state-of-the-art FL baselines.
Physics-Driven Autoregressive State Space Models for Medical Image Reconstruction
Dec 12, 2024Medical image reconstruction from undersampled acquisitions is an ill-posed problem that involves inversion of the imaging operator linking measurement and image domains. In recent years, physics-driven (PD) models have gained prominence in learning-based reconstruction given their enhanced balance between efficiency and performance. For reconstruction, PD models cascade data-consistency modules that enforce fidelity to acquired data based on the imaging operator, with network modules that process feature maps to alleviate image artifacts due to undersampling. Success in artifact suppression inevitably depends on the ability of the network modules to tease apart artifacts from underlying tissue structures, both of which can manifest contextual relations over broad spatial scales. Convolutional modules that excel at capturing local correlations are relatively insensitive to non-local context. While transformers promise elevated sensitivity to non-local context, practical implementations often suffer from a suboptimal trade-off between local and non-local sensitivity due to intrinsic model complexity. Here, we introduce a novel physics-driven autoregressive state space model (MambaRoll) for enhanced fidelity in medical image reconstruction. In each cascade of an unrolled architecture, MambaRoll employs an autoregressive framework based on physics-driven state space modules (PSSM), where PSSMs efficiently aggregate contextual features at a given spatial scale while maintaining fidelity to acquired data, and autoregressive prediction of next-scale feature maps from earlier spatial scales enhance capture of multi-scale contextual features. Demonstrations on accelerated MRI and sparse-view CT reconstructions indicate that MambaRoll outperforms state-of-the-art PD methods based on convolutional, transformer and conventional SSM modules.
I2I-Mamba: Multi-modal medical image synthesis via selective state space modeling
May 22, 2024



In recent years, deep learning models comprising transformer components have pushed the performance envelope in medical image synthesis tasks. Contrary to convolutional neural networks (CNNs) that use static, local filters, transformers use self-attention mechanisms to permit adaptive, non-local filtering to sensitively capture long-range context. However, this sensitivity comes at the expense of substantial model complexity, which can compromise learning efficacy particularly on relatively modest-sized imaging datasets. Here, we propose a novel adversarial model for multi-modal medical image synthesis, I2I-Mamba, that leverages selective state space modeling (SSM) to efficiently capture long-range context while maintaining local precision. To do this, I2I-Mamba injects channel-mixed Mamba (cmMamba) blocks in the bottleneck of a convolutional backbone. In cmMamba blocks, SSM layers are used to learn context across the spatial dimension and channel-mixing layers are used to learn context across the channel dimension of feature maps. Comprehensive demonstrations are reported for imputing missing images in multi-contrast MRI and MRI-CT protocols. Our results indicate that I2I-Mamba offers superior performance against state-of-the-art CNN- and transformer-based methods in synthesizing target-modality images.
Self-Consistent Recursive Diffusion Bridge for Medical Image Translation
May 10, 2024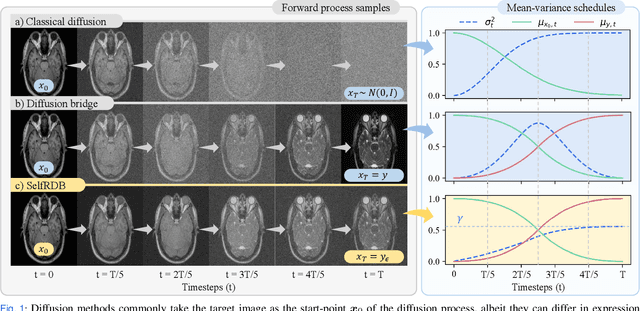
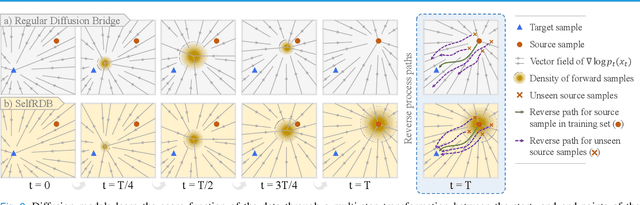
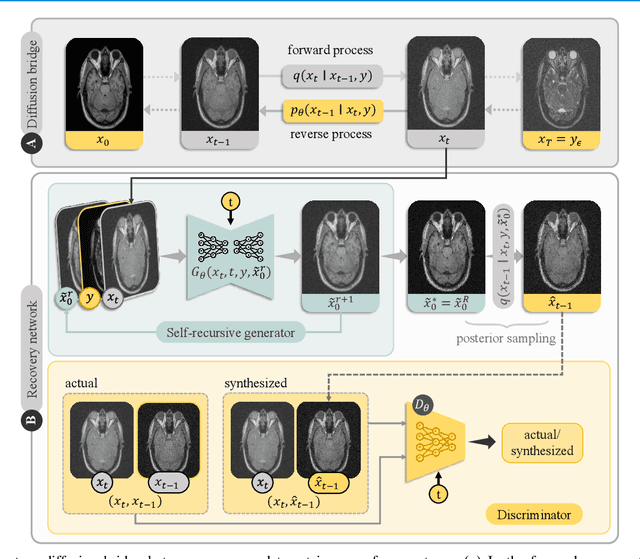
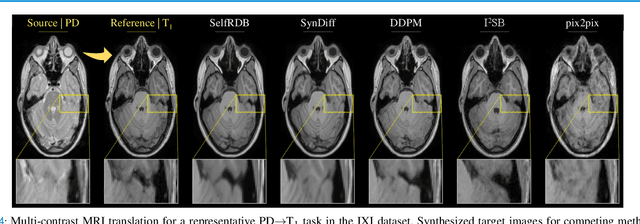
Denoising diffusion models (DDM) have gained recent traction in medical image translation given improved training stability over adversarial models. DDMs learn a multi-step denoising transformation to progressively map random Gaussian-noise images onto target-modality images, while receiving stationary guidance from source-modality images. As this denoising transformation diverges significantly from the task-relevant source-to-target transformation, DDMs can suffer from weak source-modality guidance. Here, we propose a novel self-consistent recursive diffusion bridge (SelfRDB) for improved performance in medical image translation. Unlike DDMs, SelfRDB employs a novel forward process with start- and end-points defined based on target and source images, respectively. Intermediate image samples across the process are expressed via a normal distribution with mean taken as a convex combination of start-end points, and variance from additive noise. Unlike regular diffusion bridges that prescribe zero variance at start-end points and high variance at mid-point of the process, we propose a novel noise scheduling with monotonically increasing variance towards the end-point in order to boost generalization performance and facilitate information transfer between the two modalities. To further enhance sampling accuracy in each reverse step, we propose a novel sampling procedure where the network recursively generates a transient-estimate of the target image until convergence onto a self-consistent solution. Comprehensive analyses in multi-contrast MRI and MRI-CT translation indicate that SelfRDB offers superior performance against competing methods.
PID Controller Optimization for Low-cost Line Follower Robots
Nov 07, 2021
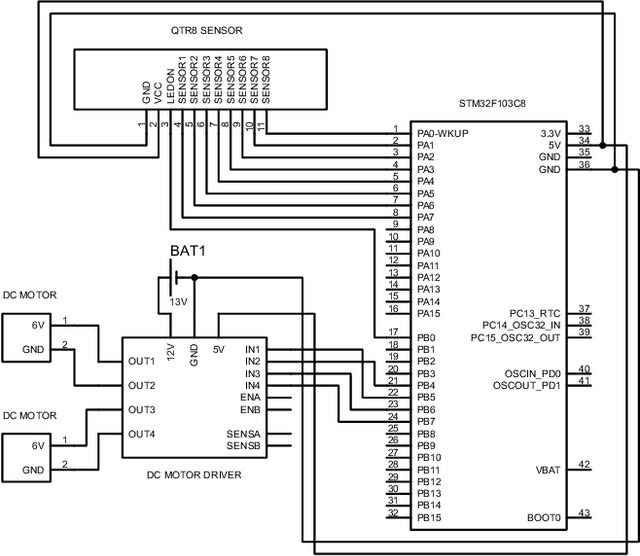
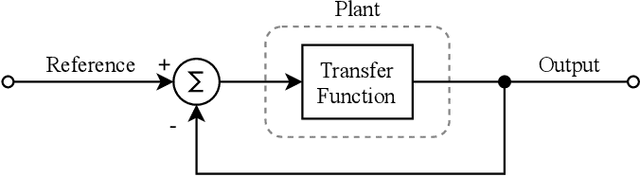
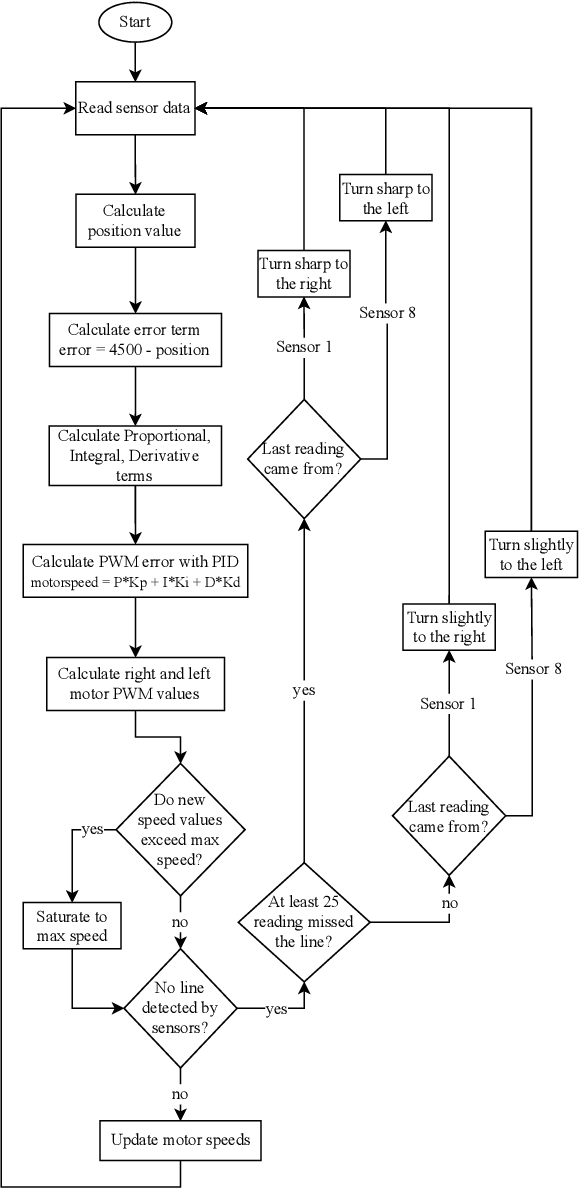
In this paper, modification of the classical PID controller and development of open-loop control mechanisms to improve stability and robustness of a differential wheeled robot are discussed. To deploy the algorithm, a test platform has been constructed using low-cost and off-the-shelf components including a microcontroller, reflectance sensor, and motor driver. This paper describes the heuristic approach used in the identification of the system specifications as well as the optimization of the controller. The PID controller is analyzed in detail and the effect of each term is explained in the context of stability. Lastly, the challenges encountered during the development of controller and robot are discussed. Code is available at: https://github.com/sametoguten/STM32-Line-Follower-with-PID.