 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Voxelwise SNR Estimation for Iterative MRI Reconstructions
May 10, 2026Purpose: To develop a fast, general-purpose framework for voxelwise noise characterization in linear and nonlinear iterative MRI reconstructions, recovering the image-domain noise variance from which SNR, $g$-factor, and related image-quality metrics are derived. The framework addresses both the intractability of closed-form formulas beyond Cartesian sampling and the long runtime of Pseudo Multiple Replica (PMR) methods. Methods: We propose PICO (Probing Image-space COvariance), an estimator that operates in the image domain by probing the image-domain noise covariance operator -- or, for nonlinear compressed-sensing reconstructions, the Jacobian of the converged solution -- with random probe images. Complex random-phase probes are shown theoretically and empirically to minimize estimator variance compared with Gaussian or real-valued alternatives. PICO was validated against analytical benchmarks and high-replica PMR references using retrospective Cartesian knee data ($R=2$), prospective non-Cartesian spiral brain phantom data ($R=2,3,4$), and compressed-sensing knee reconstructions ($R=2$). Results: In Cartesian experiments, PICO accurately reproduced analytical SENSE $g$-factor maps. In non-Cartesian spiral imaging ($R=2$), it achieved 1% estimation error in 64 s compared with 462 s for PMR (approximately 7.2x speedup), with the efficiency advantage persisting at higher acceleration. For nonlinear compressed sensing, the Jacobian-based estimator produced noise maps consistent with PMR while converging faster (52 s vs. 95 s; approximately 1.8x speedup). Conclusion: PICO provides a computationally efficient alternative to PMR for voxelwise noise and $g$-factor estimation across generalized iterative MRI reconstructions. By reusing existing reconstruction primitives, it enables voxelwise noise maps to be produced as a routine by-product of the reconstruction pipeline.
Efficient Noise Calculation in Deep Learning-based MRI Reconstructions
May 04, 2025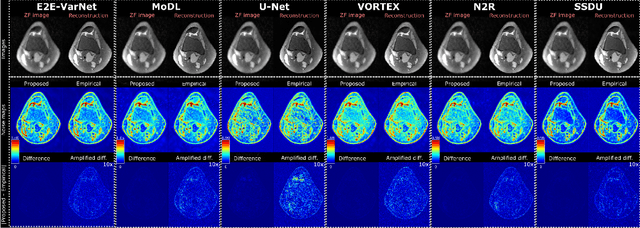
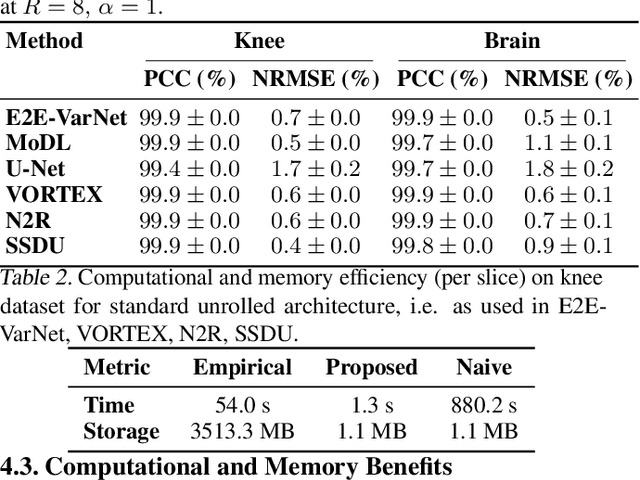
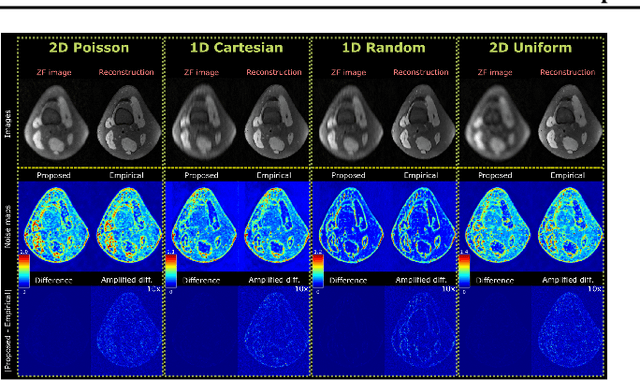
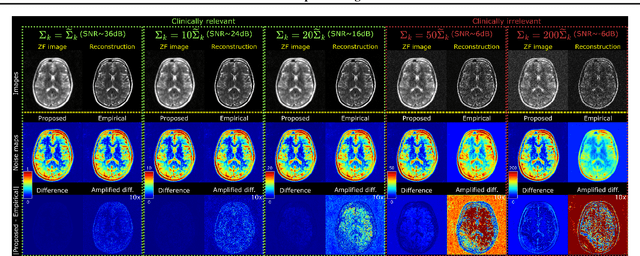
Accelerated MRI reconstruction involves solving an ill-posed inverse problem where noise in acquired data propagates to the reconstructed images. Noise analyses are central to MRI reconstruction for providing an explicit measure of solution fidelity and for guiding the design and deployment of novel reconstruction methods. However, deep learning (DL)-based reconstruction methods have often overlooked noise propagation due to inherent analytical and computational challenges, despite its critical importance. This work proposes a theoretically grounded, memory-efficient technique to calculate voxel-wise variance for quantifying uncertainty due to acquisition noise in accelerated MRI reconstructions. Our approach approximates noise covariance using the DL network's Jacobian, which is intractable to calculate. To circumvent this, we derive an unbiased estimator for the diagonal of this covariance matrix (voxel-wise variance) and introduce a Jacobian sketching technique to efficiently implement it. We evaluate our method on knee and brain MRI datasets for both data- and physics-driven networks trained in supervised and unsupervised manners. Compared to empirical references obtained via Monte Carlo simulations, our technique achieves near-equivalent performance while reducing computational and memory demands by an order of magnitude or more. Furthermore, our method is robust across varying input noise levels, acceleration factors, and diverse undersampling schemes, highlighting its broad applicability. Our work reintroduces accurate and efficient noise analysis as a central tenet of reconstruction algorithms, holding promise to reshape how we evaluate and deploy DL-based MRI. Our code will be made publicly available upon acceptance.
I2I-Mamba: Multi-modal medical image synthesis via selective state space modeling
May 22, 2024



In recent years, deep learning models comprising transformer components have pushed the performance envelope in medical image synthesis tasks. Contrary to convolutional neural networks (CNNs) that use static, local filters, transformers use self-attention mechanisms to permit adaptive, non-local filtering to sensitively capture long-range context. However, this sensitivity comes at the expense of substantial model complexity, which can compromise learning efficacy particularly on relatively modest-sized imaging datasets. Here, we propose a novel adversarial model for multi-modal medical image synthesis, I2I-Mamba, that leverages selective state space modeling (SSM) to efficiently capture long-range context while maintaining local precision. To do this, I2I-Mamba injects channel-mixed Mamba (cmMamba) blocks in the bottleneck of a convolutional backbone. In cmMamba blocks, SSM layers are used to learn context across the spatial dimension and channel-mixing layers are used to learn context across the channel dimension of feature maps. Comprehensive demonstrations are reported for imputing missing images in multi-contrast MRI and MRI-CT protocols. Our results indicate that I2I-Mamba offers superior performance against state-of-the-art CNN- and transformer-based methods in synthesizing target-modality images.
Self-Consistent Recursive Diffusion Bridge for Medical Image Translation
May 10, 2024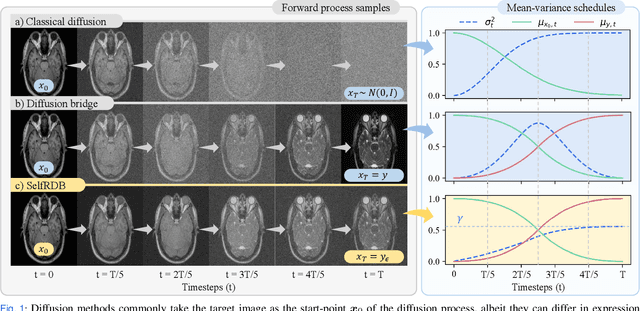
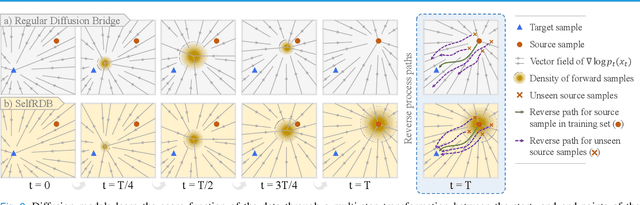
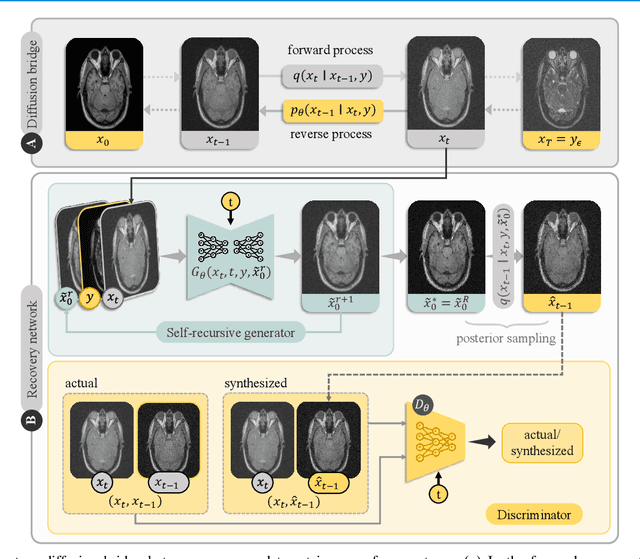
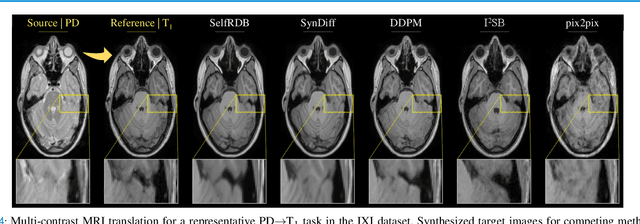
Denoising diffusion models (DDM) have gained recent traction in medical image translation given improved training stability over adversarial models. DDMs learn a multi-step denoising transformation to progressively map random Gaussian-noise images onto target-modality images, while receiving stationary guidance from source-modality images. As this denoising transformation diverges significantly from the task-relevant source-to-target transformation, DDMs can suffer from weak source-modality guidance. Here, we propose a novel self-consistent recursive diffusion bridge (SelfRDB) for improved performance in medical image translation. Unlike DDMs, SelfRDB employs a novel forward process with start- and end-points defined based on target and source images, respectively. Intermediate image samples across the process are expressed via a normal distribution with mean taken as a convex combination of start-end points, and variance from additive noise. Unlike regular diffusion bridges that prescribe zero variance at start-end points and high variance at mid-point of the process, we propose a novel noise scheduling with monotonically increasing variance towards the end-point in order to boost generalization performance and facilitate information transfer between the two modalities. To further enhance sampling accuracy in each reverse step, we propose a novel sampling procedure where the network recursively generates a transient-estimate of the target image until convergence onto a self-consistent solution. Comprehensive analyses in multi-contrast MRI and MRI-CT translation indicate that SelfRDB offers superior performance against competing methods.
Multi-task Learning for Optical Coherence Tomography Angiography (OCTA) Vessel Segmentation
Nov 03, 2023

Optical Coherence Tomography Angiography (OCTA) is a non-invasive imaging technique that provides high-resolution cross-sectional images of the retina, which are useful for diagnosing and monitoring various retinal diseases. However, manual segmentation of OCTA images is a time-consuming and labor-intensive task, which motivates the development of automated segmentation methods. In this paper, we propose a novel multi-task learning method for OCTA segmentation, called OCTA-MTL, that leverages an image-to-DT (Distance Transform) branch and an adaptive loss combination strategy. The image-to-DT branch predicts the distance from each vessel voxel to the vessel surface, which can provide useful shape prior and boundary information for the segmentation task. The adaptive loss combination strategy dynamically adjusts the loss weights according to the inverse of the average loss values of each task, to balance the learning process and avoid the dominance of one task over the other. We evaluate our method on the ROSE-2 dataset its superiority in terms of segmentation performance against two baseline methods: a single-task segmentation method and a multi-task segmentation method with a fixed loss combination.
Learning Fourier-Constrained Diffusion Bridges for MRI Reconstruction
Aug 04, 2023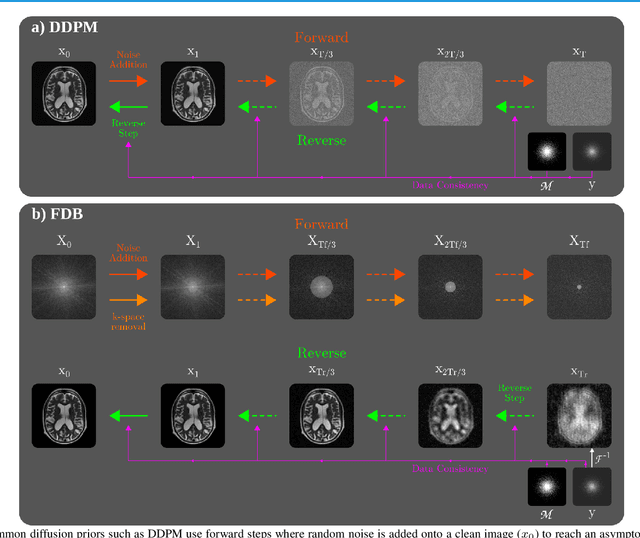
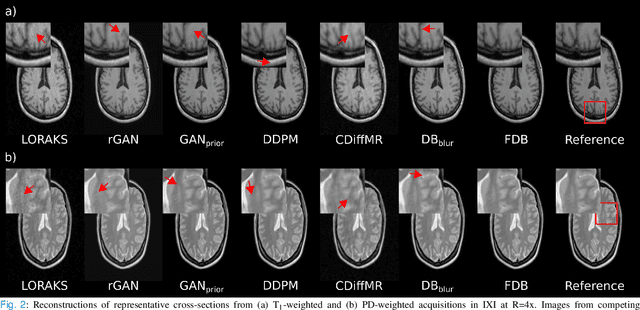
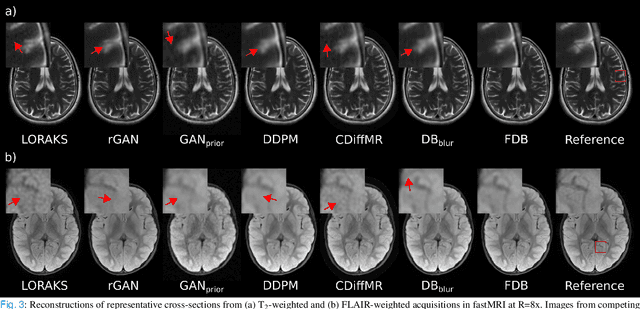
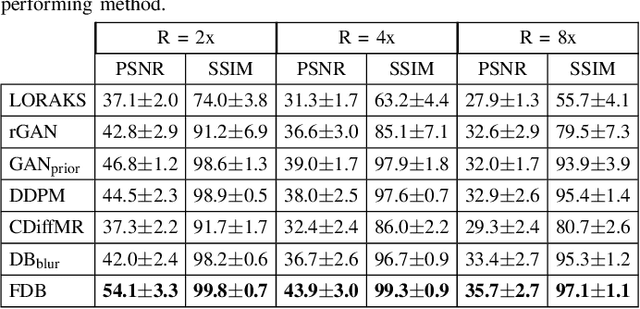
Recent years have witnessed a surge in deep generative models for accelerated MRI reconstruction. Diffusion priors in particular have gained traction with their superior representational fidelity and diversity. Instead of the target transformation from undersampled to fully-sampled data, common diffusion priors are trained to learn a multi-step transformation from Gaussian noise onto fully-sampled data. During inference, data-fidelity projections are injected in between reverse diffusion steps to reach a compromise solution within the span of both the diffusion prior and the imaging operator. Unfortunately, suboptimal solutions can arise as the normality assumption of the diffusion prior causes divergence between learned and target transformations. To address this limitation, here we introduce the first diffusion bridge for accelerated MRI reconstruction. The proposed Fourier-constrained diffusion bridge (FDB) leverages a generalized process to transform between undersampled and fully-sampled data via random noise addition and random frequency removal as degradation operators. Unlike common diffusion priors that use an asymptotic endpoint based on Gaussian noise, FDB captures a transformation between finite endpoints where the initial endpoint is based on moderate degradation of fully-sampled data. Demonstrations on brain MRI indicate that FDB outperforms state-of-the-art reconstruction methods including conventional diffusion priors.
COVID-19 Detection from Respiratory Sounds with Hierarchical Spectrogram Transformers
Jul 19, 2022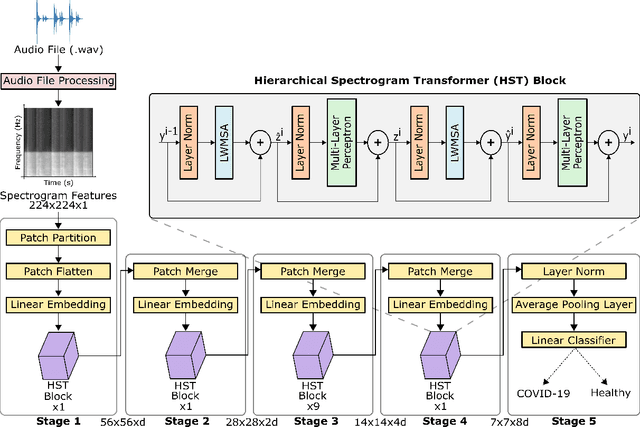
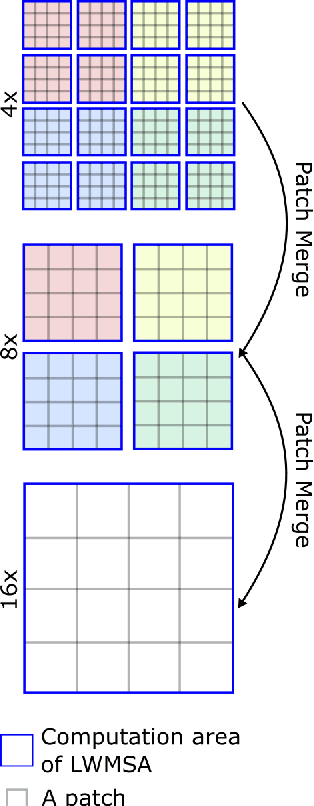
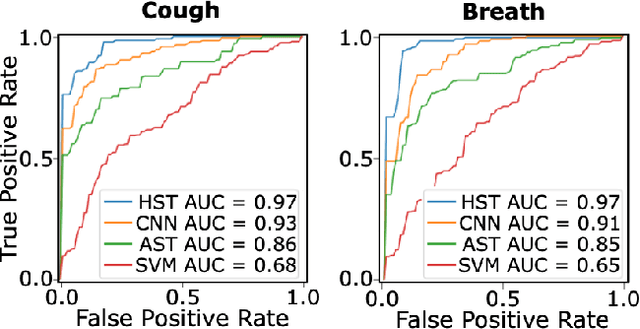
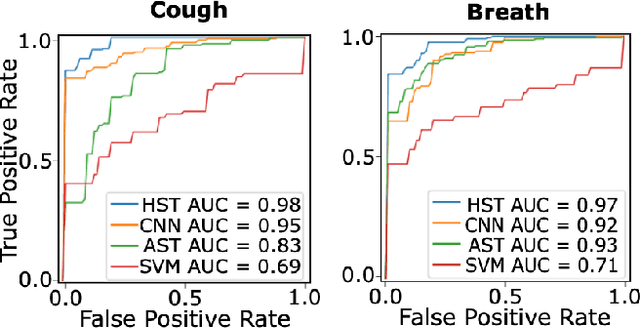
Monitoring of prevalent airborne diseases such as COVID-19 characteristically involve respiratory assessments. While auscultation is a mainstream method for symptomatic monitoring, its diagnostic utility is hampered by the need for dedicated hospital visits. Continual remote monitoring based on recordings of respiratory sounds on portable devices is a promising alternative, which can assist in screening of COVID-19. In this study, we introduce a novel deep learning approach to distinguish patients with COVID-19 from healthy controls given audio recordings of cough or breathing sounds. The proposed approach leverages a novel hierarchical spectrogram transformer (HST) on spectrogram representations of respiratory sounds. HST embodies self-attention mechanisms over local windows in spectrograms, and window size is progressively grown over model stages to capture local to global context. HST is compared against state-of-the-art conventional and deep-learning baselines. Comprehensive demonstrations on a multi-national dataset indicate that HST outperforms competing methods, achieving over 97% area under the receiver operating characteristic curve (AUC) in detecting COVID-19 cases.
Unsupervised Medical Image Translation with Adversarial Diffusion Models
Jul 17, 2022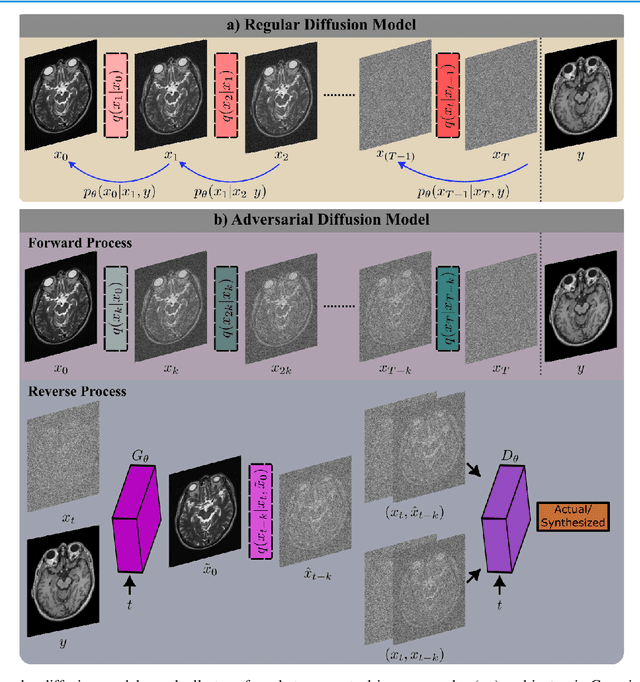
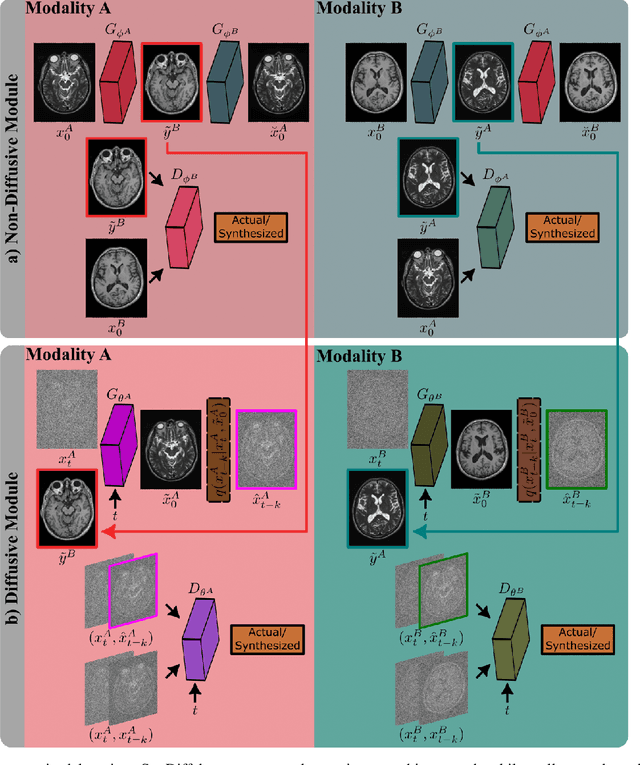
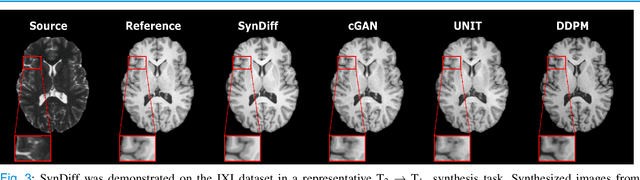
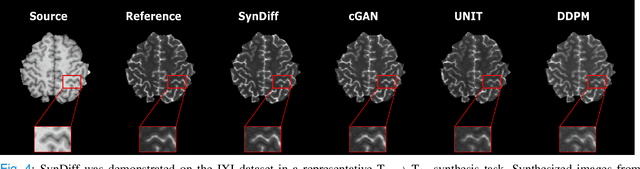
Imputation of missing images via source-to-target modality translation can facilitate downstream tasks in medical imaging. A pervasive approach for synthesizing target images involves one-shot mapping through generative adversarial networks (GAN). Yet, GAN models that implicitly characterize the image distribution can suffer from limited sample fidelity and diversity. Here, we propose a novel method based on adversarial diffusion modeling, SynDiff, for improved reliability in medical image synthesis. To capture a direct correlate of the image distribution, SynDiff leverages a conditional diffusion process to progressively map noise and source images onto the target image. For fast and accurate image sampling during inference, large diffusion steps are coupled with adversarial projections in the reverse diffusion direction. To enable training on unpaired datasets, a cycle-consistent architecture is devised with two coupled diffusion processes to synthesize the target given source and the source given target. Extensive assessments are reported on the utility of SynDiff against competing GAN and diffusion models in multi-contrast MRI and MRI-CT translation. Our demonstrations indicate that SynDiff offers superior performance against competing baselines both qualitatively and quantitatively.
One Model to Unite Them All: Personalized Federated Learning of Multi-Contrast MRI Synthesis
Jul 13, 2022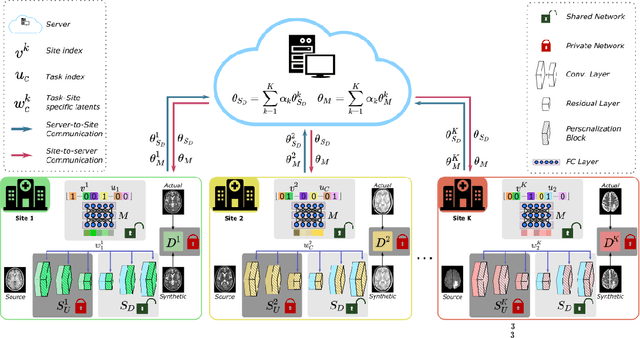
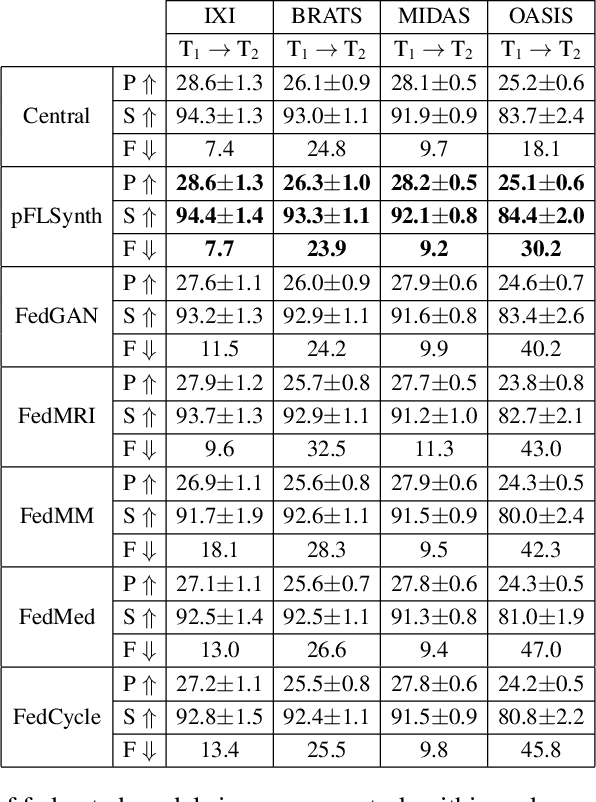
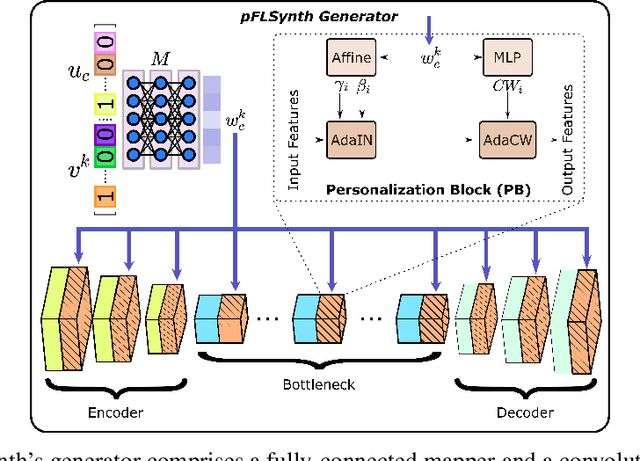
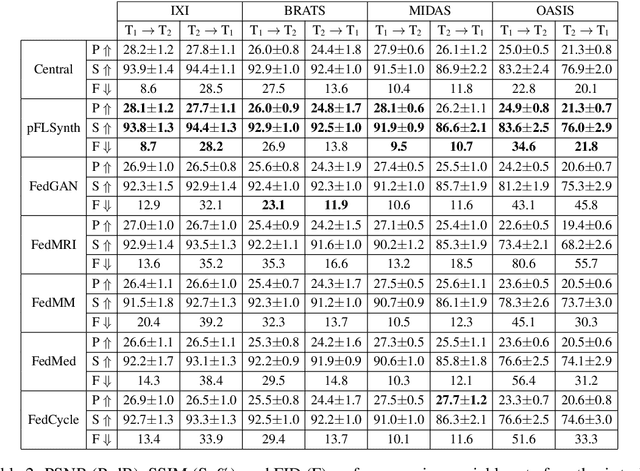
Learning-based MRI translation involves a synthesis model that maps a source-contrast onto a target-contrast image. Multi-institutional collaborations are key to training synthesis models across broad datasets, yet centralized training involves privacy risks. Federated learning (FL) is a collaboration framework that instead adopts decentralized training to avoid sharing imaging data and mitigate privacy concerns. However, FL-trained models can be impaired by the inherent heterogeneity in the distribution of imaging data. On the one hand, implicit shifts in image distribution are evident across sites, even for a common translation task with fixed source-target configuration. Conversely, explicit shifts arise within and across sites when diverse translation tasks with varying source-target configurations are prescribed. To improve reliability against domain shifts, here we introduce the first personalized FL method for MRI Synthesis (pFLSynth). pFLSynth is based on an adversarial model equipped with a mapper that produces latents specific to individual sites and source-target contrasts. It leverages novel personalization blocks that adaptively tune the statistics and weighting of feature maps across the generator based on these latents. To further promote site-specificity, partial model aggregation is employed over downstream layers of the generator while upstream layers are retained locally. As such, pFLSynth enables training of a unified synthesis model that can reliably generalize across multiple sites and translation tasks. Comprehensive experiments on multi-site datasets clearly demonstrate the enhanced performance of pFLSynth against prior federated methods in multi-contrast MRI synthesis.
BolT: Fused Window Transformers for fMRI Time Series Analysis
May 23, 2022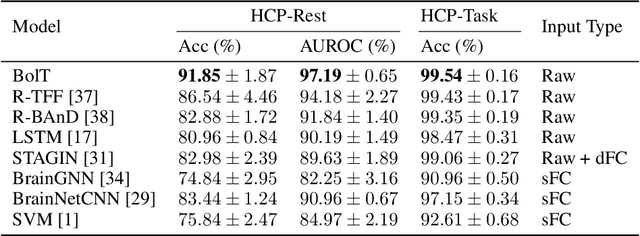
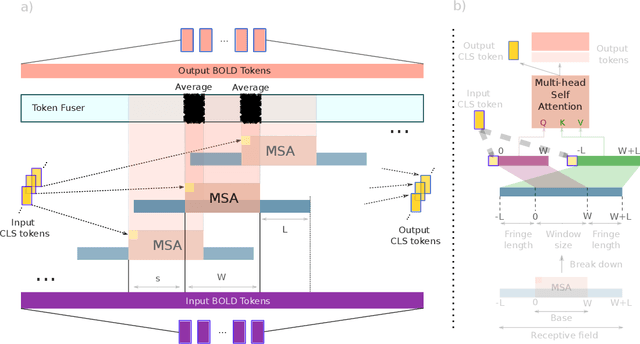
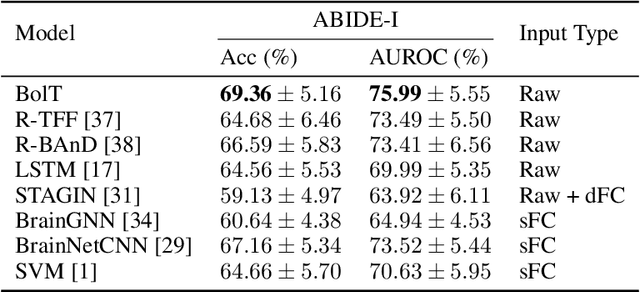
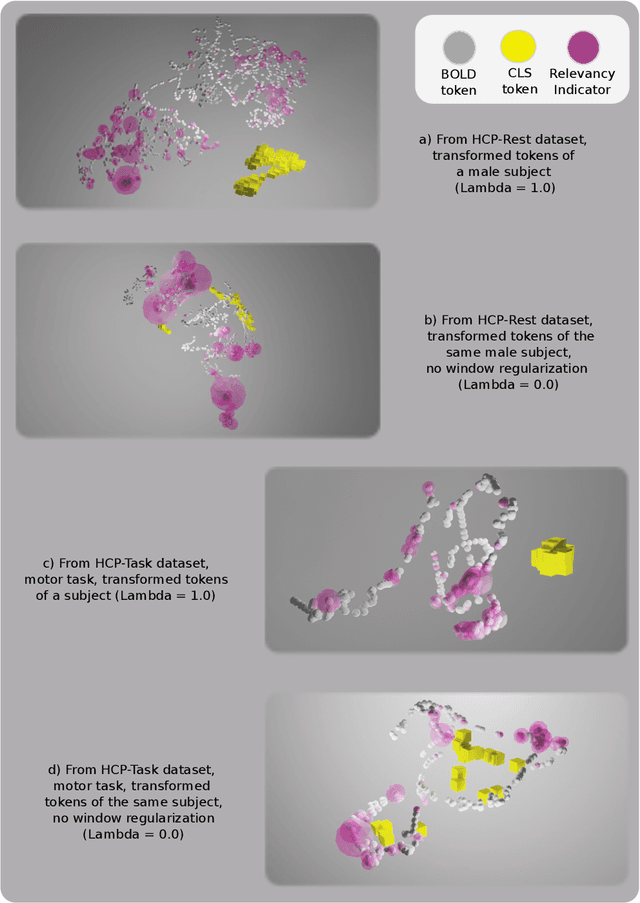
Functional magnetic resonance imaging (fMRI) enables examination of inter-regional interactions in the brain via functional connectivity (FC) analyses that measure the synchrony between the temporal activations of separate regions. Given their exceptional sensitivity, deep-learning methods have received growing interest for FC analyses of high-dimensional fMRI data. In this domain, models that operate directly on raw time series as opposed to pre-computed FC features have the potential benefit of leveraging the full scale of information present in fMRI data. However, previous models are based on architectures suboptimal for temporal integration of representations across multiple time scales. Here, we present BolT, blood-oxygen-level-dependent transformer, for analyzing multi-variate fMRI time series. BolT leverages a cascade of transformer encoders equipped with a novel fused window attention mechanism. Transformer encoding is performed on temporally-overlapped time windows within the fMRI time series to capture short time-scale representations. To integrate information across windows, cross-window attention is computed between base tokens in each time window and fringe tokens from neighboring time windows. To transition from local to global representations, the extent of window overlap and thereby number of fringe tokens is progressively increased across the cascade. Finally, a novel cross-window regularization is enforced to align the high-level representations of global $CLS$ features across time windows. Comprehensive experiments on public fMRI datasets clearly illustrate the superior performance of BolT against state-of-the-art methods. Posthoc explanatory analyses to identify landmark time points and regions that contribute most significantly to model decisions corroborate prominent neuroscientific findings from recent fMRI studies.