 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoteVAR: Autoregressive Visual Modeling for Remote Sensing Change Detection
Jan 17, 2026Remote sensing change detection aims to localize and characterize scene changes between two time points and is central to applications such as environmental monitoring and disaster assessment. Meanwhile, visual autoregressive models (VARs) have recently shown impressive image generation capability, but their adoption for pixel-level discriminative tasks remains limited due to weak controllability, suboptimal dense prediction performance and exposure bias. We introduce RemoteVAR, a new VAR-based change detection framework that addresses these limitations by conditioning autoregressive prediction on multi-resolution fused bi-temporal features via cross-attention, and by employing an autoregressive training strategy designed specifically for change map prediction. Extensive experiments on standard change detection benchmarks show that RemoteVAR delivers consistent and significant improvements over strong diffusion-based and transformer-based baselines, establishing a competitive autoregressive alternative for remote sensing change detection. Code will be available \href{https://github.com/yilmazkorkmaz1/RemoteVAR}{\underline{here}}.
Referring Change Detection in Remote Sensing Imagery
Dec 12, 2025Change detection in remote sensing imagery is essential for applications such as urban planning, environmental monitoring, and disaster management. Traditional change detection methods typically identify all changes between two temporal images without distinguishing the types of transitions, which can lead to results that may not align with specific user needs. Although semantic change detection methods have attempted to address this by categorizing changes into predefined classes, these methods rely on rigid class definitions and fixed model architectures, making it difficult to mix datasets with different label sets or reuse models across tasks, as the output channels are tightly coupled with the number and type of semantic classes. To overcome these limitations, we introduce Referring Change Detection (RCD), which leverages natural language prompts to detect specific classes of changes in remote sensing images. By integrating language understanding with visual analysis, our approach allows users to specify the exact type of change they are interested in. However, training models for RCD is challenging due to the limited availability of annotated data and severe class imbalance in existing datasets. To address this, we propose a two-stage framework consisting of (I) \textbf{RCDNet}, a cross-modal fusion network designed for referring change detection, and (II) \textbf{RCDGen}, a diffusion-based synthetic data generation pipeline that produces realistic post-change images and change maps for a specified category using only pre-change image, without relying on semantic segmentation masks and thereby significantly lowering the barrier to scalable data creation. Experiments across multiple datasets show that our framework enables scalable and targeted change detection. Project website is here: https://yilmazkorkmaz1.github.io/RCD.
Learning Fourier-Constrained Diffusion Bridges for MRI Reconstruction
Aug 04, 2023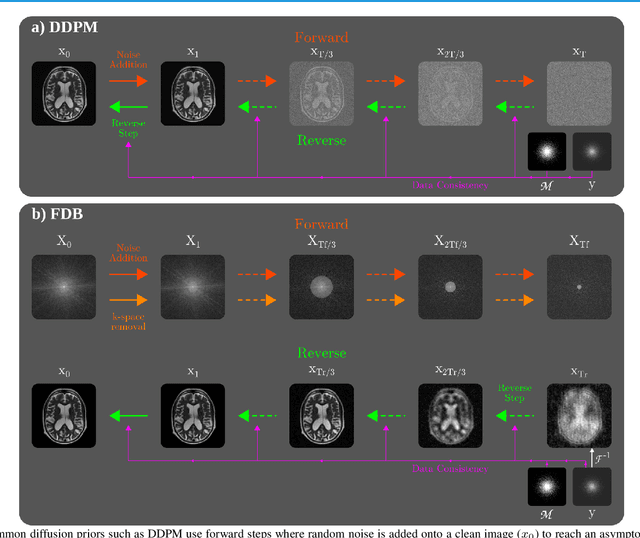
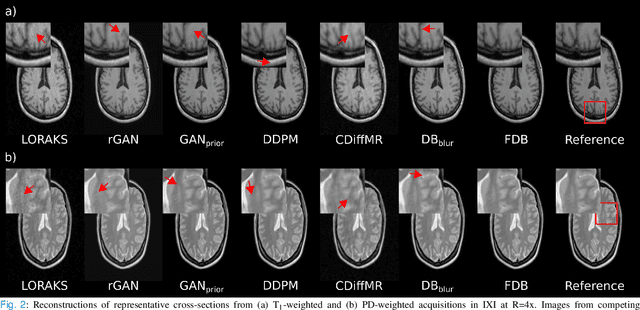
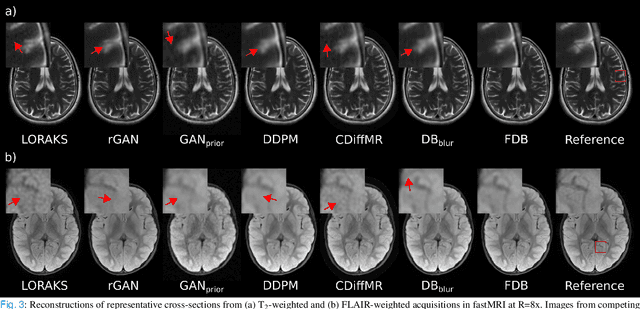
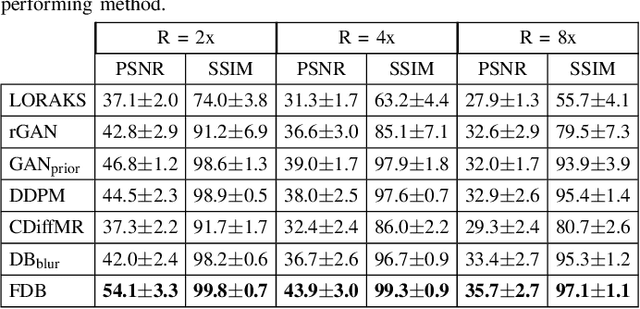
Recent years have witnessed a surge in deep generative models for accelerated MRI reconstruction. Diffusion priors in particular have gained traction with their superior representational fidelity and diversity. Instead of the target transformation from undersampled to fully-sampled data, common diffusion priors are trained to learn a multi-step transformation from Gaussian noise onto fully-sampled data. During inference, data-fidelity projections are injected in between reverse diffusion steps to reach a compromise solution within the span of both the diffusion prior and the imaging operator. Unfortunately, suboptimal solutions can arise as the normality assumption of the diffusion prior causes divergence between learned and target transformations. To address this limitation, here we introduce the first diffusion bridge for accelerated MRI reconstruction. The proposed Fourier-constrained diffusion bridge (FDB) leverages a generalized process to transform between undersampled and fully-sampled data via random noise addition and random frequency removal as degradation operators. Unlike common diffusion priors that use an asymptotic endpoint based on Gaussian noise, FDB captures a transformation between finite endpoints where the initial endpoint is based on moderate degradation of fully-sampled data. Demonstrations on brain MRI indicate that FDB outperforms state-of-the-art reconstruction methods including conventional diffusion priors.
Self-Supervised MRI Reconstruction with Unrolled Diffusion Models
Jun 29, 2023Magnetic Resonance Imaging (MRI) produces excellent soft tissue contrast, albeit it is an inherently slow imaging modality. Promising deep learning methods have recently been proposed to reconstruct accelerated MRI scans. However, existing methods still suffer from various limitations regarding image fidelity, contextual sensitivity, and reliance on fully-sampled acquisitions for model training. To comprehensively address these limitations, we propose a novel self-supervised deep reconstruction model, named Self-Supervised Diffusion Reconstruction (SSDiffRecon). SSDiffRecon expresses a conditional diffusion process as an unrolled architecture that interleaves cross-attention transformers for reverse diffusion steps with data-consistency blocks for physics-driven processing. Unlike recent diffusion methods for MRI reconstruction, a self-supervision strategy is adopted to train SSDiffRecon using only undersampled k-space data. Comprehensive experiments on public brain MR datasets demonstrates the superiority of SSDiffRecon against state-of-the-art supervised, and self-supervised baselines in terms of reconstruction speed and quality. Implementation will be available at https://github.com/yilmazkorkmaz1/SSDiffRecon.
Adaptive Diffusion Priors for Accelerated MRI Reconstruction
Jul 12, 2022
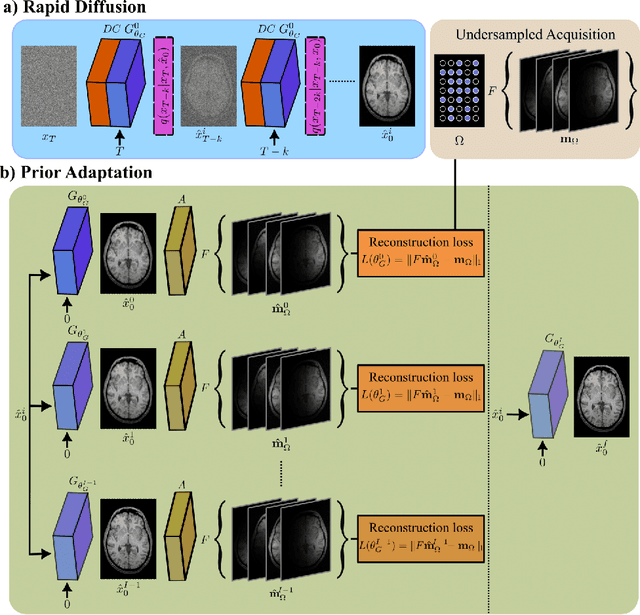
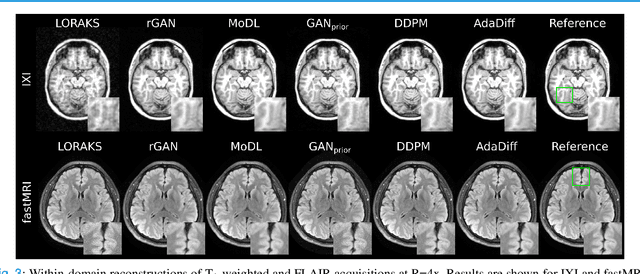
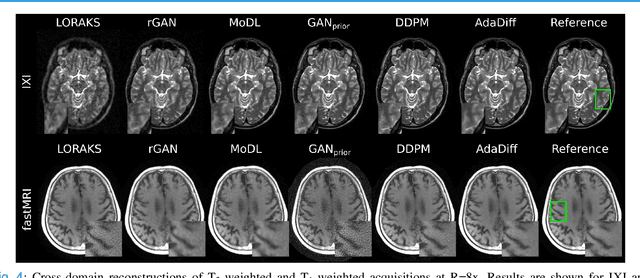
Deep MRI reconstruction is commonly performed with conditional models that map undersampled data as input onto fully-sampled data as output. Conditional models perform de-aliasing under knowledge of the accelerated imaging operator, so they poorly generalize under domain shifts in the operator. Unconditional models are a powerful alternative that instead learn generative image priors to improve reliability against domain shifts. Recent diffusion models are particularly promising given their high representational diversity and sample quality. Nevertheless, projections through a static image prior can lead to suboptimal performance. Here we propose a novel MRI reconstruction, AdaDiff, based on an adaptive diffusion prior. To enable efficient image sampling, an adversarial mapper is introduced that enables use of large diffusion steps. A two-phase reconstruction is performed with the trained prior: a rapid-diffusion phase that produces an initial reconstruction, and an adaptation phase where the diffusion prior is updated to minimize reconstruction loss on acquired k-space data. Demonstrations on multi-contrast brain MRI clearly indicate that AdaDiff achieves superior performance to competing models in cross-domain tasks, and superior or on par performance in within-domain tasks.
Federated Learning of Generative Image Priors for MRI Reconstruction
Feb 08, 2022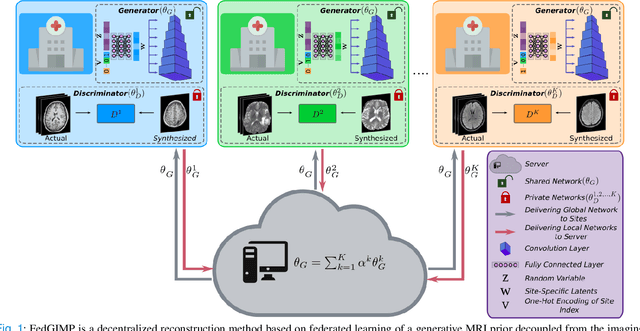
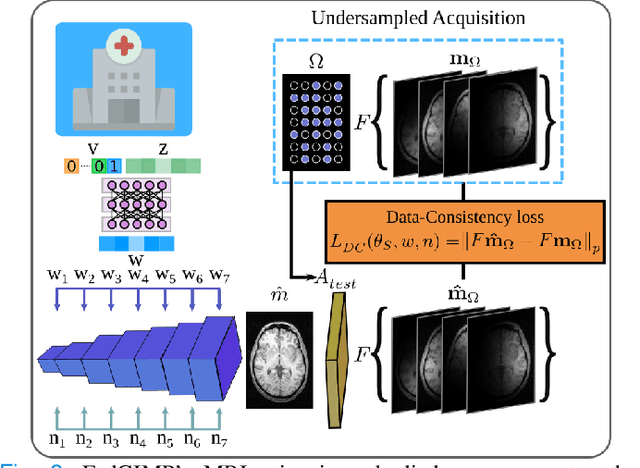
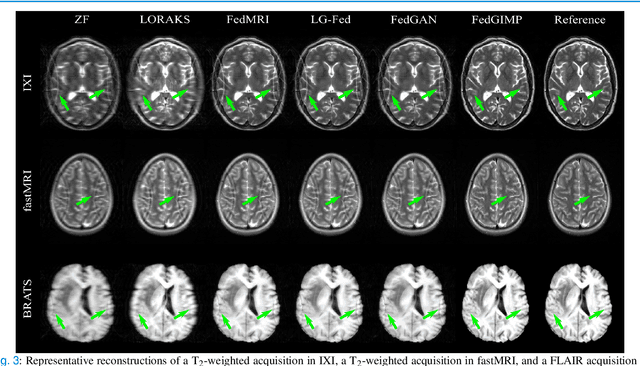
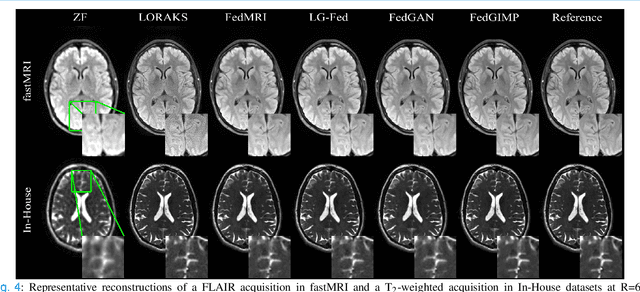
Multi-institutional efforts can facilitate training of deep MRI reconstruction models, albeit privacy risks arise during cross-site sharing of imaging data. Federated learning (FL) has recently been introduced to address privacy concerns by enabling distributed training without transfer of imaging data. Existing FL methods for MRI reconstruction employ conditional models to map from undersampled to fully-sampled acquisitions via explicit knowledge of the imaging operator. Since conditional models generalize poorly across different acceleration rates or sampling densities, imaging operators must be fixed between training and testing, and they are typically matched across sites. To improve generalization and flexibility in multi-institutional collaborations, here we introduce a novel method for MRI reconstruction based on Federated learning of Generative IMage Priors (FedGIMP). FedGIMP leverages a two-stage approach: cross-site learning of a generative MRI prior, and subject-specific injection of the imaging operator. The global MRI prior is learned via an unconditional adversarial model that synthesizes high-quality MR images based on latent variables. Specificity in the prior is preserved via a mapper subnetwork that produces site-specific latents. During inference, the prior is combined with subject-specific imaging operators to enable reconstruction, and further adapted to individual test samples by minimizing data-consistency loss. Comprehensive experiments on multi-institutional datasets clearly demonstrate enhanced generalization performance of FedGIMP against site-specific and federated methods based on conditional models, as well as traditional reconstruction methods.
Unsupervised MRI Reconstruction via Zero-Shot Learned Adversarial Transformers
May 21, 2021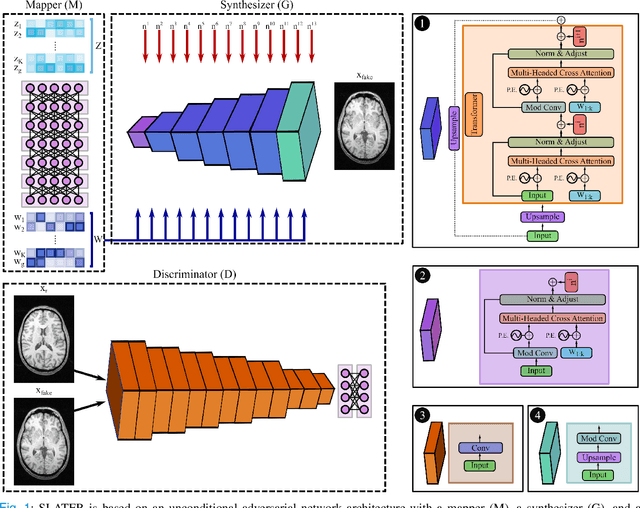
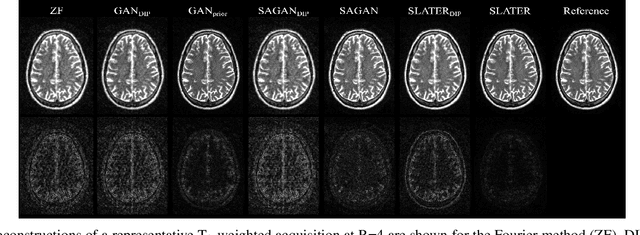
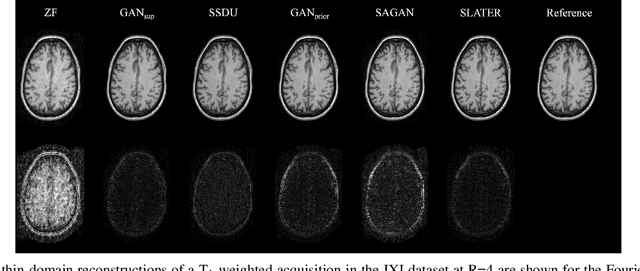
Supervised deep learning has swiftly become a workhorse for accelerated MRI in recent years, offering state-of-the-art performance in image reconstruction from undersampled acquisitions. Training deep supervised models requires large datasets of undersampled and fully-sampled acquisitions typically from a matching set of subjects. Given scarce access to large medical datasets, this limitation has sparked interest in unsupervised methods that reduce reliance on fully-sampled ground-truth data. A common framework is based on the deep image prior, where network-driven regularization is enforced directly during inference on undersampled acquisitions. Yet, canonical convolutional architectures are suboptimal in capturing long-range relationships, and randomly initialized networks may hamper convergence. To address these limitations, here we introduce a novel unsupervised MRI reconstruction method based on zero-Shot Learned Adversarial TransformERs (SLATER). SLATER embodies a deep adversarial network with cross-attention transformer blocks to map noise and latent variables onto MR images. This unconditional network learns a high-quality MRI prior in a self-supervised encoding task. A zero-shot reconstruction is performed on undersampled test data, where inference is performed by optimizing network parameters, latent and noise variables to ensure maximal consistency to multi-coil MRI data. Comprehensive experiments on brain MRI datasets clearly demonstrate the superior performance of SLATER against several state-of-the-art unsupervised methods.
Stator flux optimization on direct torque control with fuzzy logic
Jul 21, 2012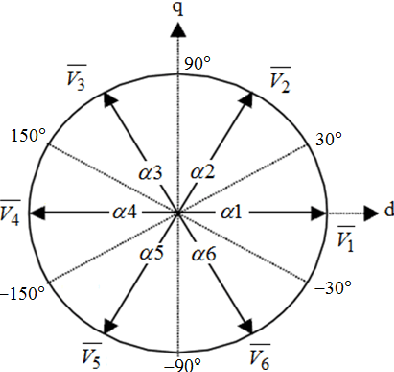
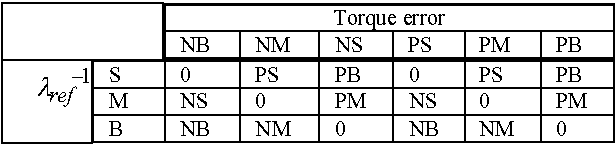
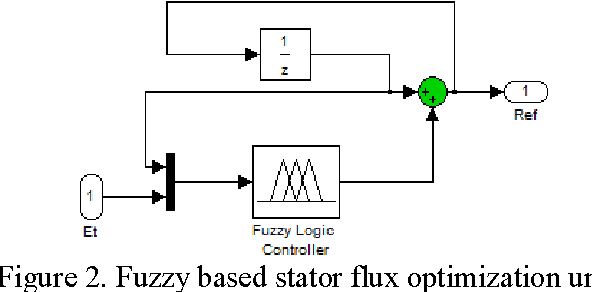
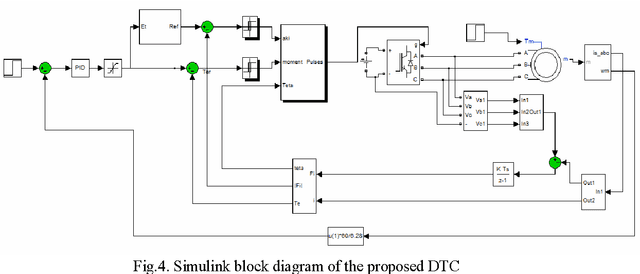
The Direct Torque Control (DTC) is well known as an effective control technique for high performance drives in a wide variety of industrial applications and conventional DTC technique uses two constant reference value: torque and stator flux. In this paper, fuzzy logic based stator flux optimization technique for DTC drives that has been proposed. The proposed fuzzy logic based stator flux optimizer self-regulates the stator flux reference using induction motor load situation without need of any motor parameters. Simulation studies have been carried out with Matlab/Simulink to compare the proposed system behaviors at vary load conditions. Simulation results show that the performance of the proposed DTC technique has been improved and especially at low-load conditions torque ripple are greatly reduced with respect to the conventional DTC.